https://ift.tt/3GlRR1I Applying Word2Vec in the food domain to generate food embeddings DayTwo holds a huge database of over 11M logged m...
Applying Word2Vec in the food domain to generate food embeddings
DayTwo holds a huge database of over 11M logged meals (and daily increasing) of over 80K members who span a broad and diverse range of tastes. These meals range from breakfasts to dinners, from single food items to complex meals, from snacks to gourmet dishes, and more. Our members invest in logging their meals so they can keep track of their daily food consumption and get a broader overview of their overall consumption with regards to their periodic sugar response levels.
The increasing number of logged meals (and members) allows us to help our customers with the ongoing process of finding new dishes they can eat based on what they usually eat. Mitigating this burden by looking at historical data and characterizing the potential meals they may want to eat next has a tremendous effect on the user experience and satisfaction of our service.

In this post, we explore how machine learning techniques derived from the NLP domain can aid us in measuring meals similarities. The key advantage of these techniques is twofold. First, they leverage a huge amount of historical data, which is constantly growing and reflects our users’ real food tastes. Second, they can be separated into different regions which are known to have different food preferences. E.G., we know that the western diet is based on carbs and fats while the eastern diet prefers fish and algae. Thus, by learning different food similarities for different regions, we can tailor our recommendation engines to a specific population and increase our personalized experience.
Meals Data
(The dataset used is not open-sourced and belongs to DayTwo)
To calculate a similarity score between 2 meals, we first need to generate meals embeddings (aka vectors). This allows us to use a common distance metric to retrieve a similarity score ranging from 0 to 1, where similar meals are scored higher.
But before having the ability to generate meals embeddings, we first calculate a single embedding vector for each food item. Then, we can consider a meal vector to be the average of all the food vectors in the meal. You may consider removing basic items such as spices or sauces since they won’t add much information to your embeddings (for the same reason stop-words are removed when training word embeddings).
We used a set of ±11M logged meals (for each cohort) where each meal m is represented as a list of k unique food items.
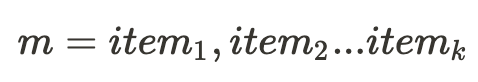
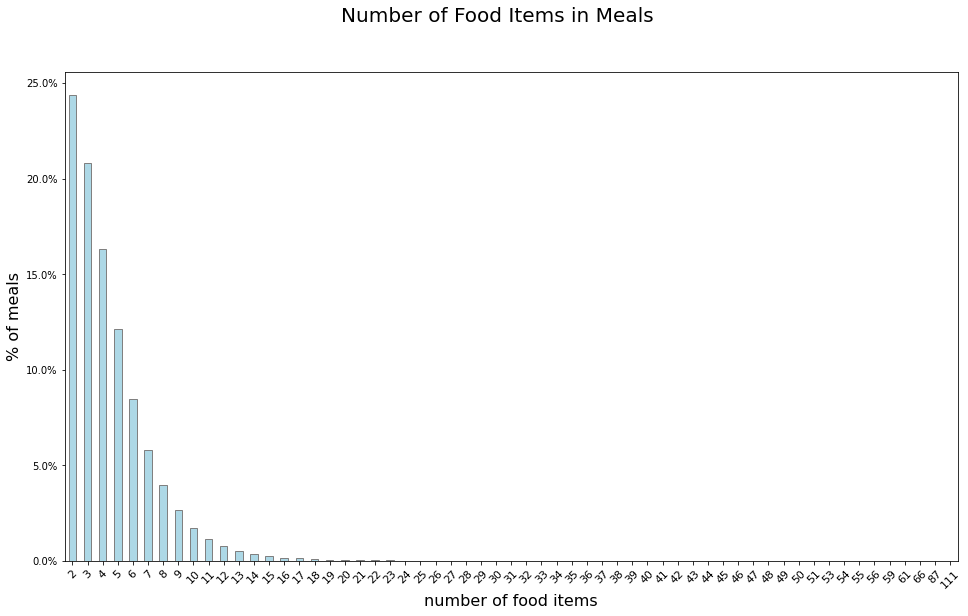
As can be seen in the histogram below, the number of food items varies greatly (meals with a single food item have already been removed). From meals with several items to meals with tens of items, clearly, a deep dive into the data is necessary in order to filter unreasonable meals. In general, it seems that each user logs her meals to a different degree of specificity.
Using Machine Learning to Learn the Food Vectors
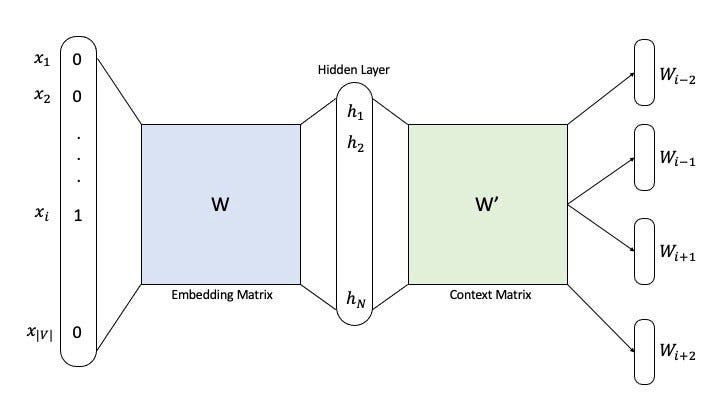
In order to train the food2vec neural network and obtain an embedding vector for each food item, each meal is treated as a sentence of food items ids separated with a single space.
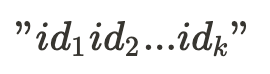
This enables the use of existing word2vec libraries to train the network. We use the skip-gram word2vec model with a window size w equals the maximum meal length to capture all the available food items pairs on all meals. Since the food domain is highly associated with geographic properties, we train our embeddings (including hyperparameters optimization ) for each cohort separately.
Measuring Similarities
Once having an embedding vector for each food item in a high dimensional space, wherein similar items appear closer together with respect to a spatial distance metric such as Euclidean distance, we can then use this embeddings map to identify clusters of food items or meals that share common elements.
Notably, there is no “ground truth” about what considers similar. Embeddings can be optimized on different aspects, which will yield different similarities.
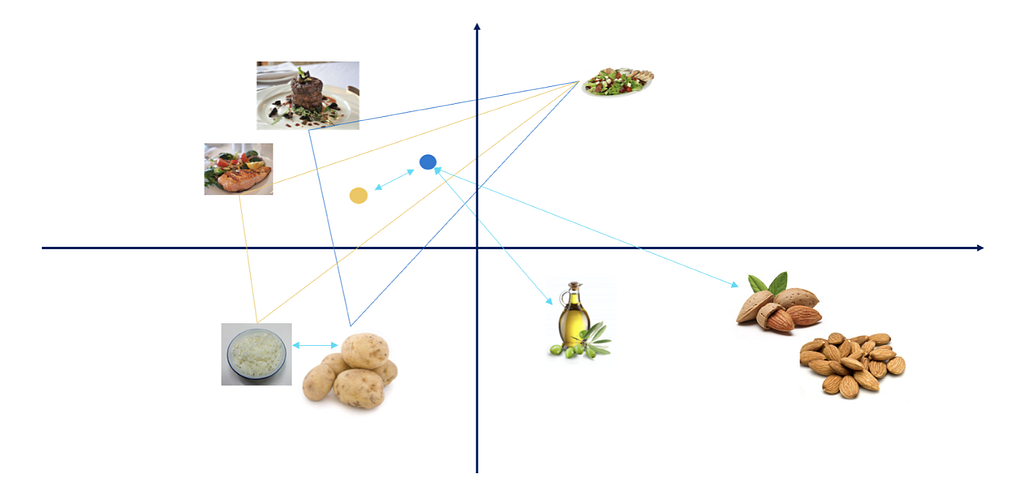
Epilogue
Finding similar meals is hard, especially due to the human taste which tends to be very personal. Luckily, the food embeddings which were discussed in this post help us achieve that and serve several other purposes. First, fueling the recommendation systems with meta-data learned from millions of historical records. Second, serve as the building blocks for many machine learning models, replacing naive features, and clearly outperform them in various classification tasks we’ve tested. Third, they encapsulate all the regional signals we can draw from all the meals, allowing ML models to be more accurate based on specific locations.
If you’d like to hear more about the latest and greatest we’ve been working on, don’t hesitate to contact me.
Measuring Meals’ Similarities was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3K2eZEV
via RiYo Analytics






No comments