https://ift.tt/3r9W1DR Batteries included. Comes with Jupyter notebook and pre-installed python packages Photo by Caspar Camille Rubin o...
Batteries included. Comes with Jupyter notebook and pre-installed python packages

Introduction
There are various reasons why we would choose to use cloud CPUs over CPU in our local machine.
- CPU workload: The first and most obvious advantage is using a cloud CPU can free up CPU workload from your local machine. This is especially beneficial is you have an old CPU in your local machine.
- Code Sharing: Using Jupyter notebooks hosted in the cloud makes sharing of code easier. Simply make it pubic and share the URL to the notebook.
- Storage: These platforms also offer storage spaces for your data which helps free up storage in your local machine.
In this article we will look at 3 platforms which offers Jupyter notebook IDE with free and unlimited CPU usage time for your machine learning projects.
Databricks
Databricks is a Data Science, Data Engineering and Machine Learning platform used by Data Scientist, Analyst and Engineers for developing and deploying ETL pipelines, machine learning models and data analysis. Databricks offers free community edition account where you get your own workspace with a cloud hosted Jupyter notebook (aka Databricks notebook). To sign up for Databricks Community Edition:
- Go to: https://databricks.com/try-databricks
- Fill in your details
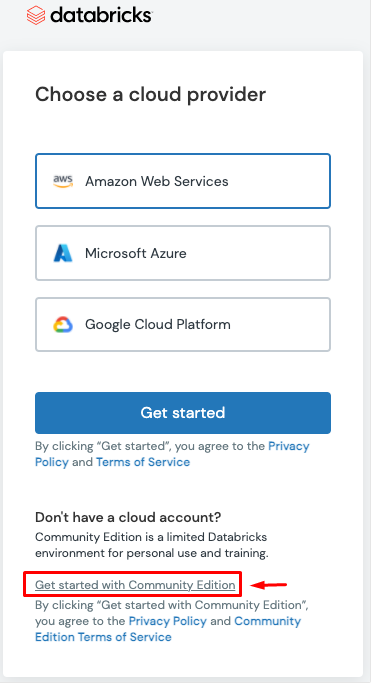
3. Click on “Get Started with Community Edition”
4. Verify your email address
Create a Cluster
After logging in you will see your the following home page. We need an active cluster to start working on datasets. Lets create one.
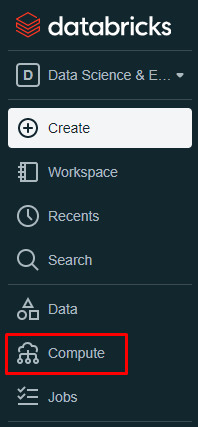
- Go to the left panel and click on “Compute”
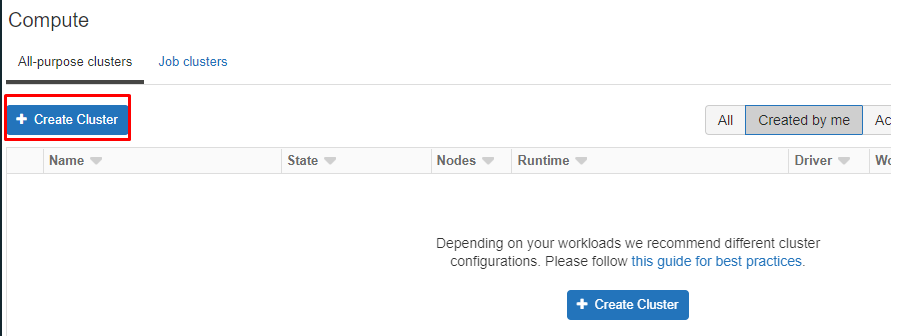
2. Click on “Create Cluster”
3. Give the cluster a name, select a Databricks runtime version and click “Create Cluster”
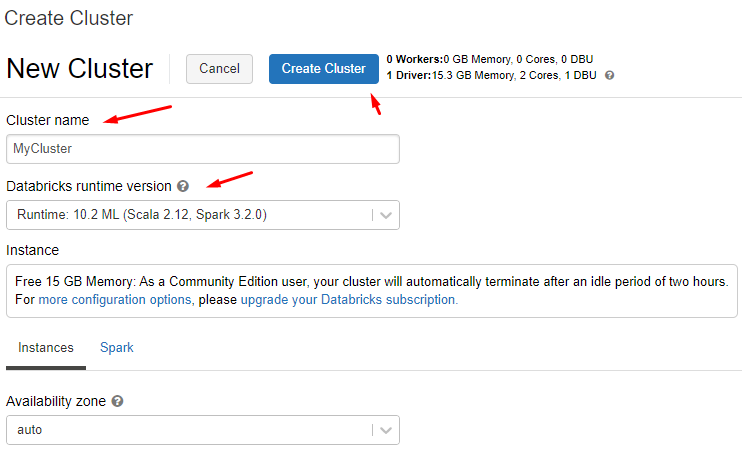
Community edition users are entitled to a driver node (2 cores) with 15GB RAM and no worker node. Databricks ML runtime supports Scala, Spark (Pyspark) and has pre-installed commonly used data science python packages such as pandas, numpy, scikit-learn etc.
Upload Data
- Lets use the Iris dataset as an example. We can download it from UCI repository.
- Extract the zip file. The data is in CSV format.
- On Databrick’s left panel click on “Data” tab
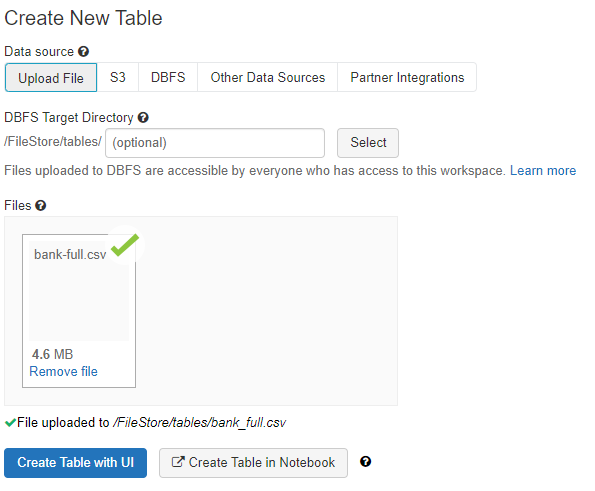
4. To upload the CSV file to Databricks, click on “Upload File”
5. Browse to select file or simply drag and drop it into the grey box
6. Click “Create Table in Notebook”
7. In the notebook cells, change infer_schema and first_row_is_header to True and delimiter to ;
# File location and type
file_location = "/FileStore/tables/bank_full.csv"
file_type = "csv"
# CSV options
infer_schema = "True" # change to True
first_row_is_header = "True" # change to True
delimiter = ";" # Change to ;
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type) \\
.option("inferSchema", infer_schema) \\
.option("header", first_row_is_header) \\
.option("sep", delimiter) \\
.load(file_location)
8. In the last cell you can name the table using the variable permanent_table_name and write the dataframe df to the table
permanent_table_name = "bank_marketing"
df.write.format("parquet").saveAsTable(permanent_table_name)
9. This will create a new table under the data tab in the left panel
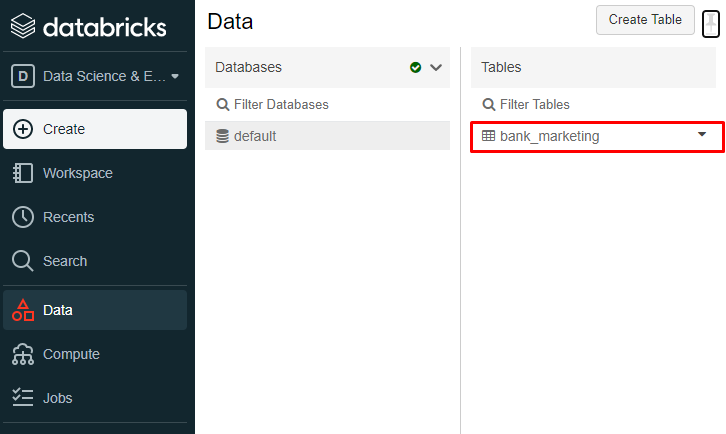
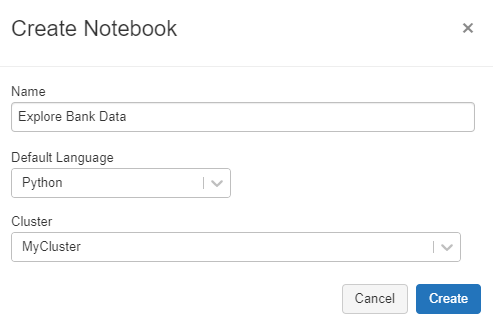
10. Now we can use this table in a new notebook. Go to Create in the left tab and create a notebook. Assign the notebook a Name and Cluster
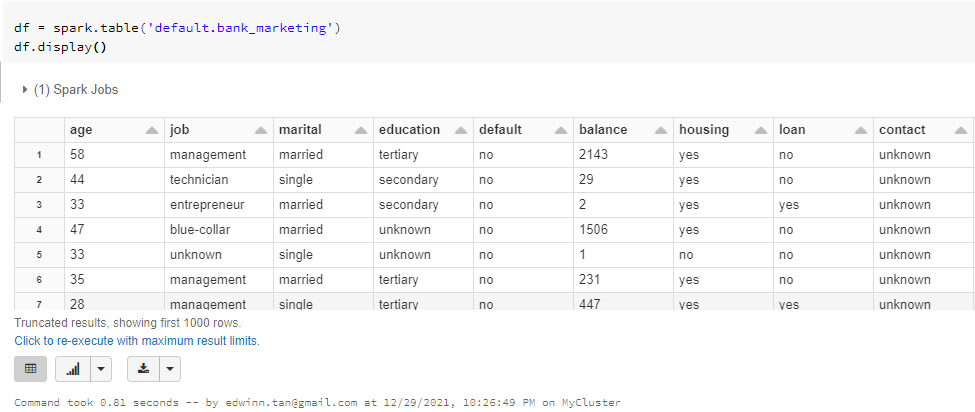
11. Read the table into the new notebook
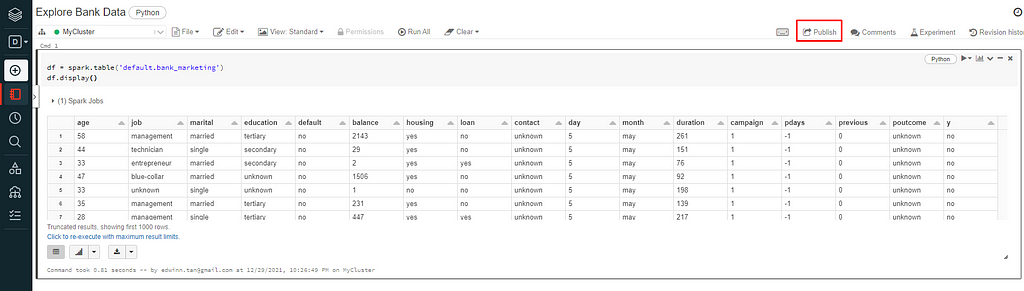
Share Notebooks
To share notebooks click on publish button located at the top right of the notebook
Google Colab
Google Collaboratory powered by Google is a Jupyter notebook IDE with access to unlimited free CPU. It also comes with limited free GPU and TPU. All you need is a Google Account to get started. Google Colab allows you to mount your Google Drive as a storage folder for your projects, and the free version of Google Drive comes with 15GB of storage.
How to use Google Colab?
- Go to Google Collaboratory
- Create a new notebook
- To use data that are already stored in your Google drive, click on the “Mount Drive” icon in the left panel
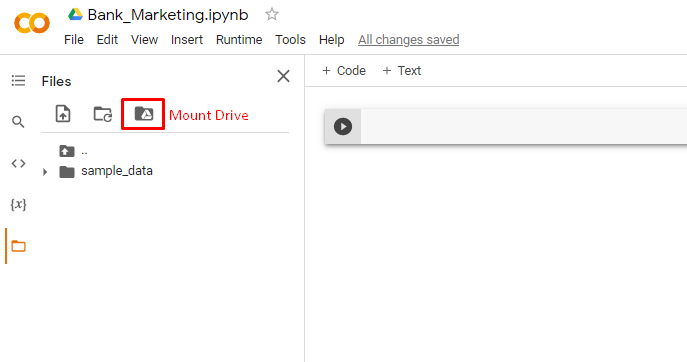
4. After the drive is mounted, we will see a drive folder in the directory. This is your google drive directory.
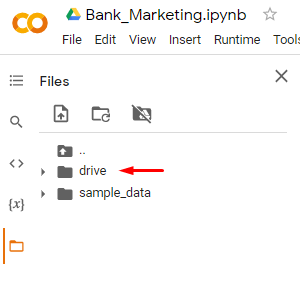
5. Read the csv file
import pandas as pd
df = pd.read_csv('/content/drive/path/to/data.csv')
Share Notebook
To share notebooks click on share button located at the top right of the notebook.

Kaggle
Kaggle offers Kaggle notebooks with unlimited CPU time and limited GPU time. There is a rich repository of datasets on Kaggle which you can start using by addint it to your Kaggle notebook.
How to use Kaggle notebooks
- Create a Kaggle account
- Create a notebook
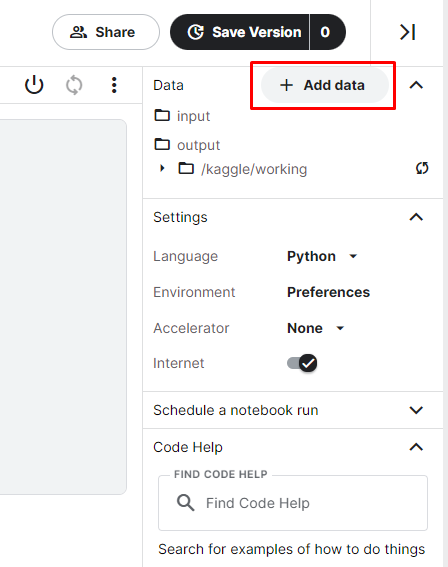
3. Select a dataset using the Add data button. We can upload our own dataset or use an existing Kaggle dataset.
Share Notebook
To share notebook click on the share button on the top right and make the notebook public.
Conclusion
We explored 3 different options for cloud hosted Jupyter notebook with free and unlimited CPU runtime. These platforms offers RAM of 12GB — 15GB making it suitable for training classical machine learning models for small to medium size datasets. If you are training deep learning models it is recommended to use GPUs instead of CPUs. Check out my other article on free cloud GPUs for training your deep learning model.
Free Cloud CPUs for Data Science and Machine Learning was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/32QyAHm
via RiYo Analytics







ليست هناك تعليقات