https://ift.tt/3JFtU7Q Assumptions in OLS Regression — Why do they matter? Why you should care about them, and how they can make or break ...
Assumptions in OLS Regression — Why do they matter?
Why you should care about them, and how they can make or break your regression model
Of course, you know Linear Regression!
Chances are, you have run hundreds of linear regression models in R and Python. All you needed was to call a function from a R/Python library, and voila!
That’s not all. You also have a fair idea about how to run regression diagnostics (or probably your data pipeline does that for you!).
Why then, getting back to the very basics and understanding “assumptions” matter at all?
Why?
It turns out that a fair understanding of the assumptions appears too “theoretical” and above all, acceptably, a bit boring for most beginners in data science (myself included), who want to jump into modeling and test their model’s predictive power.
However, the results that a model spits out, can range from ‘ineffective’ to ‘useless’, depending on whether these assumptions are met (the model will give you those results nonetheless!). A huge number of ML and statistical modeling attempts fail for one reason — lack of proper problem definition and not paying attention to the underlying theory of the model.
In data science and more often in econometrics, generally what is of the essence, is not simply the prediction, but establishing reliable causal connections that allow one to manipulate the independent variables to achieve the desired outcome in the dependent variable. One cannot do that if parameters of a computed model can be rejected straightaway due to a theoretical inconsistency!
While many textbooks that discuss this topic require a patient journey through all the equations and notations, many online articles on the topic skip the math altogether and the explanations turn too superficial. The current article lies somewhere between the two extremes, mostly aiming to provide the right intuition easily; at the same time giving a sneak peek into the math, for the interested reader.
To summarize — this writing explains the following in plain English (and with brain-friendly examples) -
- What exactly are the OLS regression assumptions? Some textbooks say there are 5, some say there are 6, some say there are 10… let’s resolve the confusion for good!
- Most importantly, what does each assumption contribute mathematically?
- What would really (really!) happen, if any of them were to be violated?
What you must know before we start.
A few brain-tattoos you need before we start.
- ‘Linear Regression’ is a model. ‘Ordinary Least Squares’, abbreviated as OLS, is an estimator for the model parameters (among many other available estimators, such as Maximum Likelihood, for example). Knowing the difference between a model and its estimator is vital.
- When we discuss assumptions, it is important to note that all of these assumptions are assumptions for the OLS estimator (and NOT for the Linear Regression model itself).
- As we will see, some of these assumptions are needed for the basic validity of the model, some others are needed for some specific ‘desired’ statistical properties of any estimator. We will introduce them (e.g. a brain-friendly version of the Gauss Markov Theorem) when it makes the most sense.
- Although the number and order of assumptions in different textbooks and articles vary; conceptually we can club a few assumptions under a single head for better understanding. That gives us a total of seven assumptions, which will be discussed below.
- For notational convenience, we stick to the classical matrix notation for linear regression
where y is the response variable vector, ϵ is the stochastic disturbance vector, X is the matrix of independent variable values (with n rows of data points and k columns of regressors xᵢ including the intercept. The first column x₁ contains 1’s only, to account for the coefficients of intercept parameter β₁)
Now on to the assumptions, let’s jump right in!
1. Linearity
While this one may appear most basic, I assure you it’s not.
This is the only assumption that probably applies both to the OLS estimator and the LR model itself, for slightly different reasons.
First, what does linearity mean for the “model”?
Well, linear Regression is quite understandably, ‘linear’.
When you chose Linear Regression as your candidate model of choice, you intended to fit a line, or more generally, a hyperplane to explain the relationship between regressand Y and regressors X(x₁, x₂,…,xₖ).
Your choice to use LR must have been informed by some sort of prior exploration of the data. For example, you might have drawn an old-fashioned scatterplot between Y and each of the xᵢ and noticed a fairly linear pattern without any evident curvature.
But what if you did notice a significant curvature in the plot of Y vs certain xᵢ? Can you still use LR?
No. It does not make sense to fit a line (hyperplane) to an obviously non-linear relationship. That would not be a good fit and defeat the purpose of modeling. So what do you do?
This is where Variable transformation comes in. LR does not necessitate y to be always linearly related to x. What it needs is a function of y, say f(y) to be linearly related to a function of x, say g(x) so that we can model the relationship as
All the above are valid linear regression models although the relationship between y and x is not exactly linear.
Word of caution: While variable transformation makes it possible to model non-linear relationships between regressand and regressor, it may make interpretation of the coefficients a bit tricky.
Second, what does linearity mean for the “OLS estimator”?
The real formal OLS assumption is not about ‘linearity in variables’ but ‘linearity in parameters’.
Here’s the thing, this is not something you need to ensure, generally. This is a theoretical assumption on which the OLS derivation really
OLS estimator is derived in two steps :
- Get the partial derivatives of the ‘Sum of Squared errors’ expression w.r.t each βᵢ. This will give you k expressions. Equate each of these to zero (for an expression to be minimum, the first derivative should be zero). So now you have k equations in k unknowns.
- When you solve these equations for the vector of β coefficient estimates, you get a closed-form solution as below (in matrix notation)

The above solution thus found is dependent on the equations that we obtained in step 1 above. If the model was not linear in βᵢ, those equations would have looked absolutely different, and so would the solution in point 2 above.
Thus, linearity in parameters is an essential assumption for OLS regression. However, whenever we choose to go for OLS regression, we just need to ensure that the ‘y’ and ‘x’ (or the transformed ‘y’ and the transformed ‘x’) are linearly related. The linearity of β’s is assumed in the OLS estimation procedure itself. While we do not need to worry much about it, it is important to understand it.
2. Full Rank
This assumption packs three assumptions in itself.
- There should not be any Perfect multicollinearity between any of the regressors.
- The number of observations (n rows of matrix X)should be greater than the number of regressors (k columns of matrix X).
- For the case of simple linear regression, all the values of the regressor x should not be the same.
While many textbooks mention these assumptions separately, these can be precisely understood as a single one — that the regressor matrix X should be ‘full rank’.
What does it mean for a matrix to be ‘full rank’? Well, simply put, you should not be able to express the values in any column of the matrix as a linear combination of other columns. In other words, all columns should be linearly independent of each other. If a column can be expressed linearly in terms of other columns, that would make that column redundant and the matrix becomes “rank-deficient”.
When a matrix is rank deficient (not full rank), its determinant becomes zero and subsequently, its inverse does not exist. Therefore the OLS ‘formula’ for determining the β coefficients does not work
So why do the above 3 assumptions all boil down to a single assumption of ‘full rank’?
Let’s look closely again at those 3 assumptions.
- If perfect multicollinearity exists between any two or more regressors, matrix X does not have “k” linearly independent columns. It is, therefore, not full rank.
- If n<k then the rank of the matrix is less than k, it does not have full column rank. Therefore, when we have k regressors, we should have at least k observations for being able to estimate β by OLS.
- For simple linear regression, if all the values of the independent variables x are the same then we have two columns in matrix X — one having all 1’s (coefficient for the intercept term) and the other having all c (the constant value of the regressor), as shown below. It is evident that in this case too, the matrix is not full rank, the inverse does not exist, and β cannot be determined.

3. Zero Conditional Mean of Disturbances
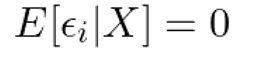
The disturbance term ϵᵢ should be independent of the regressors xᵢ. And its expected value should be zero.
Let’s unpack the above using two questions:
Firstly, why should the mean of the disturbance term be zero across different observations?
Well, the errors or disturbances are small (hopefully so!) random deviations from the estimated value that the model predicts. If the model prediction was correct to the last decimal, that would be strange! Therefore the deviations are quite normal.
However, while disturbances are expected, we do not expect these disturbances to be always positive (that would mean that the model always underestimates the actual value) or always negative (that would mean that our model always overestimates the actual value).
Rather, the disturbances shouldn’t have any fixed pattern at all. In other words, we want our errors to be random — sometimes positive and sometimes negative. Roughly then, the sum of all these individual errors would cancel out and become equal to zero, thereby making the average (or expected value) of error terms equal to zero as well.
Secondly, why should the mean of the error term be independent of the regressors?
Let’s say you want to predict the annual income of employees at your office only using their years of experience. You have three groups of people — the first group has employees with less than 3 years of experience, the second group has 3 to 7 years of experience, and the third group has 7–10 years of experience.
You created an LR model and predicted an estimated income for every member in each group. Next, to see how your model really did, you calculated the average error (call this E(ϵᵢ)) for all members in all three groups. Also, you wanted to know if your model was particularly better in predicting a particular group’s income, so you also computed the average errors in prediction for each of 3 groups individually (E(ϵᵢ|group1), E(ϵᵢ|group2), E(ϵᵢ|group3)).
Now the question is, would you prefer your predictions for one group more erroneous than predictions for the other two groups?
Of course not! You want to estimate each group impartially, and be equally correct (or incorrect) about each of the groups! So ideally the individual group-wise average errors should be the same as the overall average error.
E(ϵᵢ) = E(ϵᵢ|group1) = E(ϵᵢ|group2) = E(ϵᵢ|group3)
Therefore, the value of the variable “years of experience” should play no role in determining how wrong your estimates are.
Generalizing, in a good model, the regressors xᵢ should themselves contain no useful information about the error ϵᵢ — they should be “independent” of the error terms (regressors should be “exogenous”).
Now just combine the answers to the above two questions and you get our third assumption of zero condition mean, as shown below.

Unbiasedness Achieved!
Let’s catch our breath now. Three assumptions down, and what have we achieved so far?
Well, we have achieved a Linear Unbiased Estimator for the parameters of the linear regression model.
Unbiasedness is a desirable statistical property of an estimator. It says that on average, the estimator does not systematically underestimate or overestimate the actual population parameter.
For an estimator to be unbiased, we just need to show that its expected value is equal to the true population parameter. While we hardly ever know the true value of the population parameter to verify this, the proof can be shown analytically (but only if the above 3 assumptions are met).
For those who are interested, the proof is given below. For those who aren’t, do notice at least, how the three assumptions are factored into the proof.
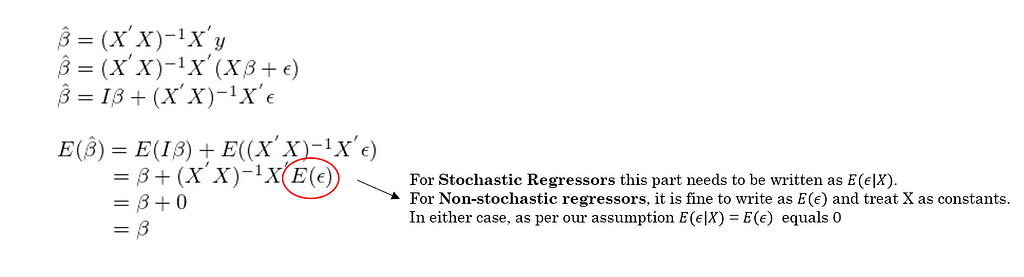
The first equation shown above is the same closed-form solution for estimated β coefficients as shown in assumption 1. In the next steps, we just expand y and distribute the product, and finally, take Expectations on both sides. All we need to notice is how the 3 assumptions make it possible -
a. Without the Linearity and Full rank assumptions, the expression for β-hat shown in the first line of the proof, is not valid, as discussed earlier.
b. Notice the part circled in red. Because of the third assumption of Zero expected value of errors (or zero conditional mean), the encircled part becomes zero, thereby making the expectation of β-hat equal to β.
Final result — the first three assumptions are enough to show that the OLS estimator is an unbiased linear estimator.
However, is that all we need?
Another desirable property of an estimator is “low variance”. The more the estimator varies among samples, the less reliable estimate it provides of the population parameter. Among all the linear unbiased estimators, the one with the lowest variance is called the “best linear unbiased estimator” (BLUE).
So can we show that the OLS estimator is BLUE?
Yes, but only if two more assumptions hold. Let’s see what they are.
4. Homoscedasticity
We just talked about the error term’s conditional mean independence assumption. Now let’s talk about the error term’s conditional variance independence assumption (which is also called ‘homoscedasticity’).
Hopefully, we are already clear on one thing — we do not want the regressors to carry any useful information regarding the errors.
What that means is, whether it is the mean (expected value) of the error; or the variance of the error, it should not differ based on different values of the regressors xᵢ.
Recall the same example of income prediction based on years of experience as mentioned in assumption 3. Do you want the errors for the first group (less than 3 years of experience) to be “more spread out” (or less spread out) than the errors for the two groups?
No. If the errors for one or more groups are more spread out (have more error variance) than other groups, what it essentially means is that your predictions for those groups are less reliable.
Homoscedasticity says that the variance of the error term ϵᵢ should be equal to a constant no matter what the regressor value is. Stated mathematically as follows.
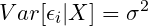
5. Nonautocorrelation
Let’s continue our quest of making the errors as random and independent of other factors as possible.
We already discussed two assumptions — one about the mean of the errors being independent of the regressors and the other about the variance of the errors being independent of the regressors.
Mean Independence and Homoscedasticity ensure that the errors are unrelated to the regressors.
Nonautocorrelation ensures that the errors are unrelated to other errors.
Stated mathematically, the covariance among the errors across observations should be zero.

Although it sounds a bit unintuitive, sometimes, for data observations that are ordered in some manner (for example, time-series data), it is quite common to observe error values having an ‘inertia’ — positive error followed by a positive error or negative errors followed by negative errors, in consecutive observations (called positive autocorrelation). The errors could also have an alternating pattern across observations— positive errors followed by negative errors or vice versa(called negative autocorrelation).
There are several techniques to handle and transform LR models so that autocorrelation does not pose a problem, although it naturally exists in the data.
Minimum Variance Achieved (BLUE)!
With the addition of assumptions 4 and 5 to the first three assumptions, it can be shown that the OLS estimator is BLUE, with the help of the Gauss-Markov Theorem.
What Gauss Markov Theorem’s proof shows is that all Linear Unbiased estimators will have a variance larger than the variance of the OLS estimator.
To make things easy for us, let’s understand this final output of the Gauss Markov theorem symbolically as follows. As per the proof, it can be shown that
Var(Any Linear Unbiased Estimator) = X + A positive quantity
The above equation clearly shows that X is less than LHS.
What’s important is that using the homoscedasticity (Var(ϵᵢ)=σ²) and nonautocorrelation (Cov(ϵᵢ,ϵⱼ)=0 for all i ≠ j) conditions, we can show that X = Variance of OLS estimator.
For the sake of simplicity, we understood the Gauss Markov theorem intuitively. The interested readers can find more about the proof online here or in any standard textbook.
While the five assumptions discussed above are sufficient to make OLS estimator BLUE (without which an estimator is not really as good as it ought to be!), two more assumptions deserve mention.
6. Stochastic or Non-Stochastic Regressors
This assumption is probably the only one you can afford to forget about (once you understand it!).
I included this so that you know what it means when you see it in every textbook.
Non-Stochastic Regressors mean that you fixed certain “x” values (independent variable values) and collected the data on “y” corresponding to those x values only, but collected multiple samples.
Going back to our previous example, let’s say you want to predict annual income based on years of experience. Your manager gave you three lists of employees with their annual income. Each list corresponds to a particular experience level — let’s say 3 years, 6 years, and 10 years of experience respectively. Each list contains data on 50 employees. As you can see, the x-values are fixed(3, 6, 10), but have repeated samples (50 data points per sample). This is what is known as Non-stochastic regressors (In theory, a model adhering to this is also called Classical Linear Regression Model or CLRM).
Instead of giving you three separate lists, your manager might give you a single list of 150 employees with their annual income. This list may contain employees with randomly varying years of experience (e.g. 1,2,3,7,10). Here x-values are not fixed but can take any (realistic) value for years of experience. In this case, we are using Stochastic(random) regressors (In theory, a model adhering to this is called Neo-classical Linear Regression Model or NLRM).
It does not matter which kind of data generation process you used before the creation of your regression model, so long as the 5 assumptions stated earlier hold, all the statistical properties and the goodness of the OLS estimator still hold (which is why you can afford to forget about this one!).
Mathematically, the only difference is — if you are using Non-stochastic regressors, you get a mathematical convenience — to remove all the “given X” part of the assumption expressions, making them unconditional (as we are treating X as known constants and not random variables themselves).
E(ϵᵢ|X) = 0 would simply become, E(ϵᵢ) = 0
Var(ϵᵢ|X) = σ² would become Var(ϵᵢ)= σ²
In most data science investigations, data collection on regressors is usually random, so we usually stick with the conditional expression. In some experimental setups in econometric analysis, sometimes the regressors are set up in a non-stochastic manner and then the response data is collected for those values of regressors.
7. Normality

This assumption is pretty straightforward. All it says is that that the errors should be normally distributed. That this distribution should have mean zero (assumption 3)and constant variance σ²( assumption 4) have already been shown earlier.
However, note that this assumption is NOT a necessary condition for achieving nice statistical properties such as “Unbiasedness” and “Minimum Variance” of the OLS estimator. As long as the first 5 assumptions are met, the OLS estimator will be BLUE (Best Linear Unbiased Estimator) even if the errors are not normally distributed.
Why do we need this assumption at all then?
Well, firstly we do not need it if all we need is a BLUE estimator. In fact, for sufficiently large samples, the normality condition is usually met without us having to break any sweat over it (asymptotic normality). For most representative samples of data collected randomly, it is reasonable to expect normal errors.
However, adding this as an explicit assumption makes two interesting things possible -
- When all the other assumptions are met along with the normality assumption, OLS estimates coincide with the Maximum Likelihood estimates (which is quite a biggie among estimators!), giving us certain useful properties to work with. More on this in a future article!
- Coefficient estimates for βᵢ can be shown to be a linear function of errors ϵᵢ. A very cool property to keep in mind— a linear function of a normally distributed random variable is also normally distributed. Therefore assuming ϵᵢ as normally distributed gives us βᵢ estimates as normally distributed as well. This makes it easier for us to calculate confidence intervals and calculate p-values for the estimated β — coefficients (which are commonly seen in R and Python model summaries). If the error normality condition is not satisfied, then all the confidence intervals and p-values of individual t-tests for β — coefficients are unreliable.
To sum it all up!
If you are only interested in a Linear Unbiased Estimator, you just need —
- Linearity
- Full Rank
- Zero Conditional Mean of disturbances (Exogenous regressors)
If you also want the Best (or the Minimum Variance) estimator in addition to the linear estimator being unbiased, then you need additionally —
4. Homoscedasticity
5. Nonautocorrelation
Apart from the estimator being BLUE, if you also want reliable confidence intervals and p-values for individual β coefficients, and the estimator to align with the MLE (Maximum Likelihood) estimator, then in addition to the above five assumptions, you also need to ensure —
7. Normality
Finally, do not forget about assumption 6 (Non-stochastic and Stochastic regressors) if you want to write your next research paper on the subject and want mathematically correct equations.
Conclusion
Now that you have seen every OLS assumption in action, it is really up to you to decide which ones you should validate to make sure your model works correctly.
While some of these assumptions are mathematical conveniences to prove a theory, most of them are a necessary basis for creating concrete and robust models.
A good understanding of these assumptions enabled me as a data practitioner to grasp even more difficult concepts in statistical modeling and machine learning. Hopefully, it will help you too!
Join me on my journey
If you liked this article, I invite you to follow my Medium page for more updates on interesting topics in data science and connect with me on LinkedIn.
Textbook References
- William H. Greene — Econometric Analysis Seventh Edition, Chapter 2 pp 51–65.
- Jeffrey M. Woolridge — Introductory Econometrics Seventh Edition, Chapter 2 pp 40–57.
Assumptions in OLS Regression — Why do they matter? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3JEppuf
via RiYo Analytics








ليست هناك تعليقات