https://ift.tt/3sruv6S Two labeled opossums, image from Pexels Data labeling, one of the most critical tasks in the lifecycle of a mach...

Data labeling, one of the most critical tasks in the lifecycle of a machine learning project, is currently also one of the hardest to manage, scale, and monitor — and not for the right reasons
Andrew Ng, an AI pioneer, is on a mission to change the AI ecosystem to be more data-centric. Ng is basing his research on data (well, you should’ve seen it coming) collected throughout the years on how ML practitioners improve their model’s performances. Data, as Ng claims, is the most significant factor in the improvement rate, where good labeling is the number one cause.
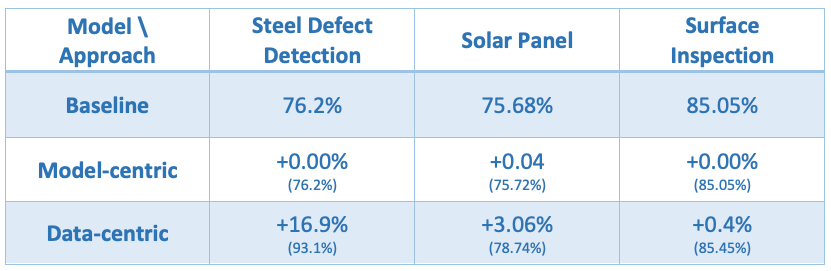
Moreover, basing the success of the model on the number of data points it’s trained on and not on their quality, will lower the potential improvement rate. Accurate and consistent labeled data increases the likelihood of our model to learn patterns that will help it predict events successfully.
What are the challenges in labeling unstructured data
Knowing that labeling is an essential factor in the project lifecycle — why is it still such a hard task to manage, scale and monitor? At DagsHub, we’ve interviewed ML professionals from hundreds of companies, trying to get to the bottom of their workflow problems. When examining the labeling phase, we encountered 5 main challenges:
- Managing data labeling.
- Annotation version control.
- Communicating throughout the labeling process.
- Workforce management.
- Domain knowledge required.
Managing data labeling
The vast majority of labeling tools require moving the data to their workspace. If we have a DevOps team at our disposal, they might help us stream or pull a version of the data, while in most cases, we will have to copy it. When we gradually add new raw data or modify it, we need to also update the data hosed on the labeling tool workspace. For that, we need to curate what is missing, create a copy and move it to the labeling workspace — a tedious task in itself. But what happens when we have multiple versions of the data that differ from each other? It will require even more work to the extent of writing automations that synchronizes the storage and the labeling tool.
On top of that, when moving the data to the workspace, we lose its structure in the context of the project. It will only keep the name of the file without its path in the original project. Some tools even require modifying the data structure, to the extent that would have us abandon the directory structure and use a flat directory. Losing or modifying the data structure makes it even more complex to manage the labeling task and control the versions of the data.
Annotation Version Control
Labeling is a difficult task to master. It depends on a variety of parameters that are hard to predefine and, in most cases, will require multiple iterations. Same as any experiment we have in a data science project, we’d like a way to easily modify the annotations, test, analyze, and in some cases, retrieve and reproduce previous results. However, most labeling tools don’t support data lineage, making the iteration process ambiguous, which will likely result in stone age versioning (data_annotation1, data_annotation-11–02–2020, data_annotation_backup, etc.).
Communicating Throughout the Labeling Process
Labeling is an abstract task that doesn’t have a golden metric that can be tested easily. For example, “Use bounding boxes to indicate the position of the opossum.”

Can result in any one of the following outcomes:

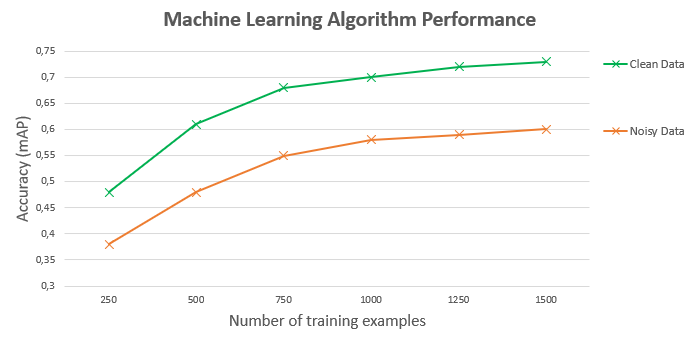
As Andrew Ng showed, one of the most significant factors on the model’s performances is the noisiness of the data, or in other words, the consistency of the labels. Combining the ambiguousness of the task with the importance of its accurate outcome leads to the conclusion that the review process should be meticulous. However, most tools don’t support a communication channel between the reviewer and the labeler with the context of the labels. Thus, many organizations complete the reviewing process on a third-party platform, or worse, on a call, making it hard to track and manage the changes over time.
Workforce management
Because labeling can be a tedious and time-consuming task, many companies try to scale it by using outsourcing solutions or hiring a designated in-house expert team. Both options are valid and can help us move faster, but they do have some blind spots.
The challenges when outsourcing the labeling task
- Conflict of interest — usually, data labelers are paid by the quantity of the labeled data they provide. Therefore, it’s in their best interest to label as much data in as little time as possible, regardless of its noisiness. However, as the data consumers, we’d like to receive the best quality of data labels knowing how it affects the model’s performance. Since it’s hard to monitor the quality of the labeler’s work, this conflict can become a genuine concern when thinking of outsourcing the task.
- High upfront investment — Training data labelers can be an arduous journey, especially if unique domain knowledge is required. It demands a significant upfront time investment, where its outcomes are unknown and might fail to actually be worth it.
The challenges when hiring a designated in-house labeling team
- Scale-down — in many cases, labeling is not an ongoing task. We’ll put a lot of effort into labeling the required data at the start of the project, and then scale down to only work on improving the noisy samples. When hiring an in-house team, the scaling margin narrows down dramatically, and we’ll have to provide them with consistent work.
- Resources — hiring and training an in-house labeling team require a lot of resources — on the financial, time, and staffing fronts. Further, it will require more of our daily attention for managing the team and quality-control their product.
Domain knowledge required
Many projects demand prior knowledge to label their data. For example, labeling X-rays chest images and classifying them for Pneumonia will require a medical background that very few labelers have. Therefore, many projects are halted or require very large fundings due to the low pool of labelers and their high cost or the long training process required.
Summary
In recent years the AI domain has rapidly grown and evolved due to the enormous amount of data within reach of ML practitioners. However, the data-centric paradigm has proven that having a large amount of data just doesn’t cut it; we need high-quality labeled data to achieve SOTA results. Mastering the labeling task is still a work in progress, and once we’ll be able to easily scale and manage it, achieving those results will no longer be a MI.
If you’re facing challenges I didn’t mention here or can think of what can help us overcome them — I’d love to hear about it!
Why is labeling unstructured data still hard? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3eaCwF0
via RiYo Analytics







No comments