https://ift.tt/3EKDu6l A simple recipe to use AWS SageMaker in script mode to train your custom TensorFlow model with all the horsepower yo...
A simple recipe to use AWS SageMaker in script mode to train your custom TensorFlow model with all the horsepower you need.
Entering the 22nd of 150 epochs after 10 hours of training, I realized the 3000 wav file dataset was a bit tough to swallow for my 5 year old MacBook Pro. The Free Spoken Digit Dataset contains recordings from 6 speakers and 50 of each digit per speaker in 8kHz .wav format. As I was following along the outstanding video series on Sound Generation With Neural Networks by Valerio Velardo, I found myself stuck in an endless training phase. The goal is to train a custom-made Variational Auto-Encoder to generate sound digits.

The preprocessing of the FSDD wav files was performed locally and generated a training dataset of 3000 spectrograms in .npy format (the expected input format for my TensorFlow model). While SageMaker now supports various data sources such as Amazon FSx and Amazon EFS, I uploaded the training dataset to S3 in a bucket located in the us-east-1 region (N. Virginia). Pay attention to this particular point as SageMaker needs to be in the same region as your bucket.
My source code consists of 2 files:
- autoencoder.py — the auto-encoder “VAE” class definition: a deep convolutional auto-encoder with mirrored encoder/decoder and latent space. Contains all TensorFlow libraries imports.
- train.py — training initialization: access the training data, instantiate a model, define all parameters (input shape, filters, kernels, strides, latent space dimensions and various hyperparameters). Contains the VAE class import from autoencoder.py
These two files work jointly on my local hard drive upon local training, but how does that transpose into the cloud?
Training with SageMaker
SageMaker mainly offers 5 ways to train a model:
- Built-in algorithms
- Script-mode
- Docker container
- Marketplace
- Notebook instance
In our particular case, script-mode is the way to go, as we provide the source code to be executed in a TensorFlow-compatible container (managed by AWS).
Choose a basic SageMaker Notebook configuration (an ml.t2.medium will do), make sure the attached IAM-execution-role allows access to your S3 bucket and launch the instance from the Management Console (in the same region as the bucket). In script-mode, note that this SageMaker Notebook instance is used for script launching only, not for training.
I uploaded my source code to the working directory of the SageMaker Notebook instance storage, where I also created my own script.ipynb to orchestrate the training procedures. In this script, I included the following imports:
import sagemaker
from sagemaker.tensorflow import TensorFlow
import boto3
Then I defined all useful SageMaker variables as follows:
bucket = 'mytrainingdatabucket'
role = sagemaker.get_execution_role()
numpy_train_s3_prefix = f"{bucket}/spectrograms"
numpy_train_s3_uri = f"s3://{numpy_train_s3_prefix}"
inputs = {'data' : numpy_train_s3_uri}
Most importantly, the estimator handles all end-to-end SageMaker training tasks. Here are the parameters that require specific attention:
- entry_point: path to your training code (in my case train.py)
- source_dir: path to the rest of your source code (dependancies, libraries, etc).
- model_dir: specify where your code is expected to write the model generated by your algorithm in the container, usually ‘opt/ml/model’. At the end of training, SageMaker fetches whatever it finds in ‘opt/ml/model’ and outputs it to S3.
- train_instance_type: go for a powerful one as it will be leveraged for training only.
- output_path: path to S3 to save model artifacts and output files.
- script_mode: boolean, select True in this case.
Here is how I initialized my estimator instance for an AWS-managed TensorFlow-compatible container:
estimator = TensorFlow(entry_point='train.py',
source_dir='.',
model_dir = "/opt/ml/model",
train_instance_type='ml.p2.xlarge',
output_path=f"s3://{bucket}/output",
train_instance_count=1,
role=sagemaker.get_execution_role(),
framework_version='2.0',
py_version='py3',
script_mode=True)
Then training will be launched by calling fit() on the estimator as follows, but before that we need to define all environment variables as described in the next paragraph.
estimator.fit(inputs)
Environment variables
I implemented the parse_args() function in my train.py file to collect all essential SageMaker environment variables such as paths and hyperparameters:
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=150)
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--learning_rate', type=float, default=0.0005)
# data directories
parser.add_argument('--data', type=str,
default=os.environ.get('SM_CHANNEL_DATA'))
parser.add_argument('--output', type=str,
default=os.environ.get('SM_CHANNEL_OUTPUT'))
parser.add_argument('--train', type=str,
default=os.environ.get('SM_CHANNEL_TRAIN'))
parser.add_argument('--model_dir', type=str,
default=os.environ.get('SM_MODEL_DIR'))
return parser.parse_known_args()
Consequently, I can load the training data:
x_train = get_train_data(args.data)
Then I can instantiate the VAE class and call the training method accordingly:
autoencoder = train(x_train, args.learning_rate, args.batch_size, args.epochs)
Finally, once the model is trained, I can call the save() method from the VAE class to store my model artifacts (parameters.pkl and weights.h5) in ‘opt/ml/model’. This step is essential as SageMaker will not save your model automatically but rather simply fetch whatever is in that container folder. Therefore, take this action explicitly:
autoencoder.save(args.model_dir)
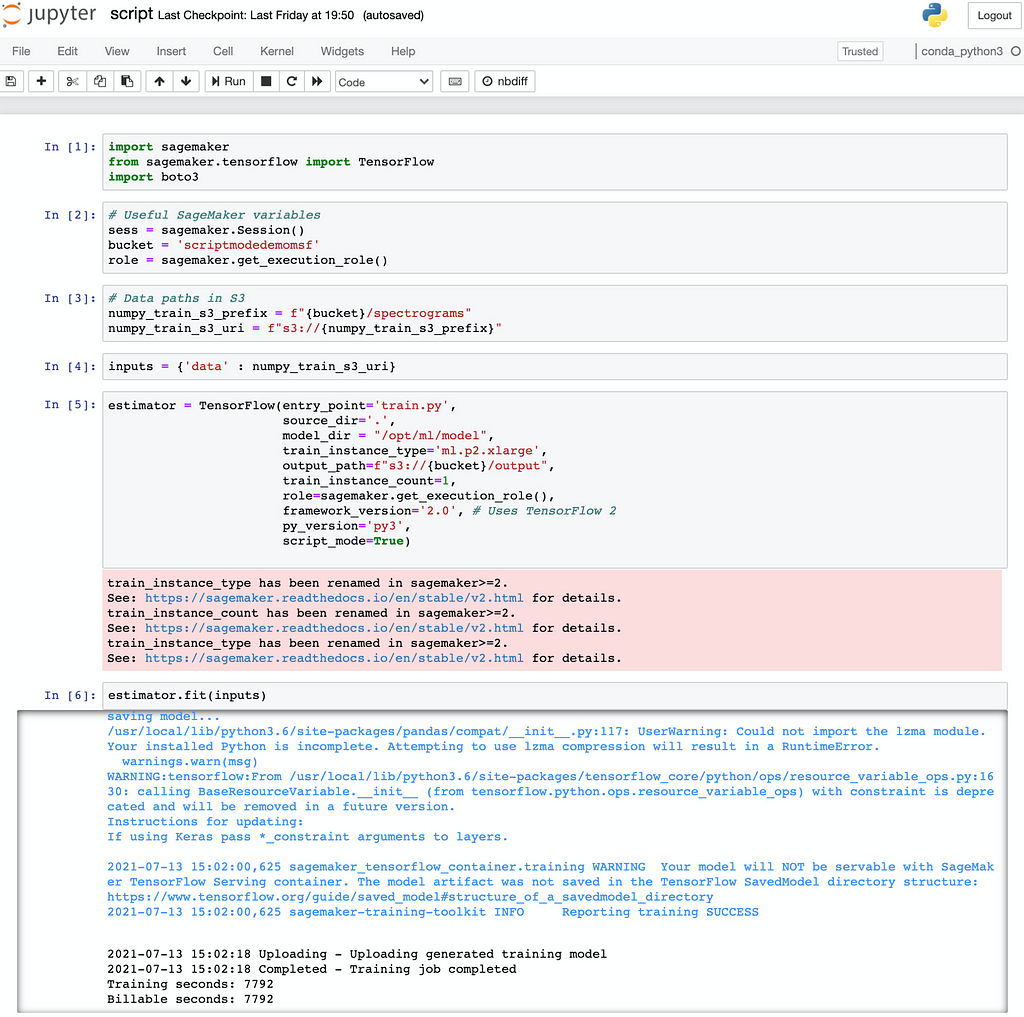
That’s it! Here is a snapshot of the execution of my script.ipynb:
Conclusion
As seen above, the training job took about 2 hours to complete, the cost incurred was approx. $3.20 (computing + storage) as per my AWS billing dashboard on a free-tier account.
The model generated is stored in my S3 bucket in the ‘output/’ folder and comes as a 8.4MB model.tar.gz archive. After downloading and unziping it, I was able to use the load() method of the VAE class and succesfully made inferences to generate sounds. Here is an example of a “zero” sound digit generated by my model :
Check out my GitHub repository for this project, thank you for reading!
Train Your Own Variational Auto-Encoder for Sound Generation with AWS SageMaker was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3lTA9dX
via RiYo Analytics








No comments