https://ift.tt/3EiQSP7 An overview and getting-started guide for the SageMaker Training Compiler Introduction Deep neural networks have b...
An overview and getting-started guide for the SageMaker Training Compiler
Introduction
Deep neural networks have been steadily becoming larger every year, as hardware and algorithmic advancements have allowed for neural networks composed of hundreds of billions of parameters. Transformer models in particular, often used for Natural Language Processing (NLP) tasks, have seen the number of parameters used soar in recent years. For example, Bidirectional Encoder Representations from Transformers (BERT) large proposed in 2018 has over 340 million parameters, and the Switch Transformer proposed in 2021 has 1.6 trillion parameters.
Despite recent technological advancements the cost and time to train these models is becoming prohibitive. At AWS we have a track-record of inventing on behalf of our customers to reduce the cost and time to run training jobs for the most common deep learning frameworks (TensorFlow and PyTorch). Two of these innovations include SageMaker libraries for data parallelism and model parallelism, which reduce training times for specific tasks through advancements in distributed training techniques. If you want to dive deeper on our distributed training techniques, I highly recommend reading our publication on SageMaker Data Parallel.
In 2021, we have introduced our newest innovation for deep learning model training: the SageMaker Training Compiler. Available as part of the SageMaker SDK, and requiring minimal changes to existing code that leverages TensorFlow or PyTorch, the SageMaker Training Compiler optimizes your training code to run more efficiently and consume less compute and memory, speeding up GPU powered training jobs by up to 50%. This advancement will democratize state-of-the-art deep learning models to a wider audience, and provide performance improvements to our customers using these frameworks on AWS.
In this post, I will walk you through the high-level design of the SageMaker Training Compiler, and show you how to integrate the SageMaker Training Compiler with the Hugging Face Transformers library. Hugging Face is a company that offers easy-to-use tools and libraries for developing and deploying state-of-the-art open-source NLP models.
SageMaker Training Compiler
Compilers are responsible for converting the code you specify in a high-level programming language (such as Python or Java) into machine code that is executed on hardware. In translating high-level programming languages to machine code, compiler designers must make decisions regarding this translation that have implications for the performance of the compiled code that is executed. At AWS, our compiler designers went to work to create a compiler optimized specifically for large-scale deep learning training, and the result was the SageMaker Training Compiler.
Neural networks built with TensorFlow and PyTorch are represented visually and logically as graphs. The SageMaker Training Compiler uses graph level optimizations such as operator fusion, memory planning, and algebraic simplification to optimize that graph for execution on the underlying hardware. In addition, the SageMaker Training Compiler provides backend optimizations (memory latency hiding, loop oriented optimizations) and data-flow optimizations (layout transformation, common sub-expression elimination) to efficiently orchestrate the training execution.
Real-time operator fusion is one of the main techniques that underlies the time savings the SageMaker Training Compiler provides, and thus warrants a slightly deeper dive. One of the main bottlenecks in training a deep learning model, is the latency cost of round trips to memory to retrieve and execute operators. By fusing together multiple operators, the SageMaker Training Compiler requires the training job to make fewer trips to memory and can execute a larger set of operators directly within the hardware registers of the backend device. This results in performance gains versus traditional approaches to operator execution.
High-level Architecture
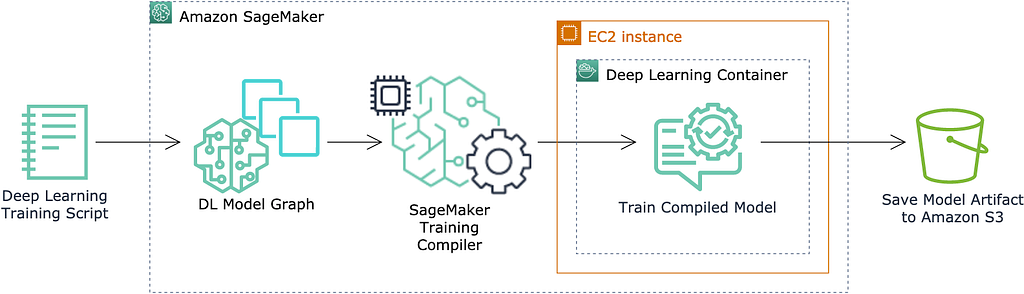
The SageMaker Training Compiler is available directly within select AWS Deep Learning Containers (DLCs). Specifying the appropriate frameworks and estimator parameter arguments will enable the SageMaker Training Compiler, and if you are bringing your own model, there might be additional changes required for your training script. The SageMaker Training Compiler will then analyze your training script, and automatically make optimizations during compilation, allowing your model training job to execute faster. The model artifact produced by the training job is then outputted to Amazon Simple Storage Service (S3).
Getting Started with the SageMaker Training Compiler using Hugging Face Transformers
The SageMaker Training Compiler currently supports PyTorch and TensorFlow. To quickly get hands-on with the SageMaker Training Compiler, I will show a straightforward way for you to integrate the SageMaker Training Compiler with the Hugging Face Trainer API and PyTorch, a method which requires minimal code changes if you need to refactor existing work.
Prerequisites
- If this is your first time using Amazon SageMaker you will need to set up SageMaker
- Configure SageMaker Studio or feel free to adapt the instructions for SageMaker Notebook Instances or another development environment
- Make sure to review the SageMaker Training Compiler tested instance types and if necessary, request a quota increase if your account-level service limit does not have your desired instance type and number of needed instances available
Walkthrough
For a completed example of this technique for performing model tuning for a sentiment classification task using BERT-base-cased you can visit our AWS GitHub Examples page. This example assumes the use of a single p3.2xlarge instance. In addition, the example assumes PyTorch v1.9.0 and Transformers v.4.11.0.
Important: The SageMaker Training Compiler has been tested on a select number of models. Although you can experiment with the SageMaker Training Compiler on models outside of those listed on the AWS documentation page, performance of the SageMaker Training Compiler on other models has not been tested. There are also recommended batch size settings within the supported model table. If you deviate from the tested models and recommended batch size settings, you will need to retune parameters before unlocking any training speed up.
In the following walkthrough, I will show you how to use a Hugging Face code generation feature to quickly generate training code to be used with Amazon SageMaker. I will then walk you through the steps needed to build-out the code generated by Hugging Face to integrate with the SageMaker Training Compiler. In the walkthrough, I select the “Text Classification” task as the model task I want to fine-tune my pre-trained model on.
- Select one of our tested models that is also available as a Hugging Face Pretrained Model.
- Now, let’s generate our starter code. Navigate to the Hugging Face model page for your selected model (for example, here is the page for roberta-large).
- Near the top of the page click “Train” > “Amazon SageMaker”.
4. Select the task you want to fine-tune the model on and select AWS for the Configuration.

5. Copy the displayed code to your clipboard, create a Jupyter notebook running in your Amazon SageMaker development environment, and paste the code into your notebook.
6. Prepare your training data, splitting into training, validation, and test datasets as desired and upload the data to S3. Store the S3 paths in variables defined in your Jupyter notebook. In preparing your data, you might find the Hugging Face datasets library helpful.
training_input_path=‘s3://example_bucket/s3_prefix_example/train’
test_input_path=‘s3://example_bucket/s3_prefix_example/test’
7. Write your training script, and store the training script at the location specified in the source_dir parameter of your Hugging Face Estimator. For example training scripts see the Hugging Face GitHub repository or reference the BERT Base Cased example above. For this example your training script must use the transformers library’s Trainer class.
from transformers import Trainer, TrainingArguments
training_args=TrainingArguments(**kwargs)
trainer=Trainer(args=training_args, **kwargs)
8. To ensure you are taking advantage of the SageMaker Training Compiler’s ability to fit a larger batch size in memory, reference the Batch size for native and Batch size for Training Compiler numbers. Using the acquired batch size numbers, update the batch size and scale your learning rate based on the new batch size at the top of your Jupyter notebook.
# the original max batch size that can fit into GPU memory without compiler
batch_size_native=12
learning_rate_native=float(‘5e-5’)
# an updated max batch size that can fit into GPU memory with compiler
batch_size=64
# update learning rate
learning_rate=learning_rate_native/batch_size_native*batch_size
9. Update your HuggingFace estimator to specify the correct parameters for enabling the SageMaker Training Compiler, it is currently recommended to disable Debugger to ensure no impact on performance, but please refer to the SageMaker Training Compiler documentation for the latest guidance on Debugger and SageMaker Training Compiler.
In this step, note that we are instantiating an instance of the TrainingCompilerConfig class and passing it to the compiler_config parameter. This class gives you the ability to configure the SageMaker Training Compiler for your training job. The TrainingCompilerConfig class accepts two boolean arguments for the enabled and debug parameters. For more information on these parameters see the documentation. By not specifying the compiler_config parameter in your estimator, you are explicitly disabling the SageMaker Training Compiler.
pytorch_huggingface_estimator=HuggingFace(
source_dir=’./scripts’,
entry_point=’train.py’,
instance_count=1,
instance_type=’ml.p3.2xlarge’,
transformers_version=’4.11.0',
pytorch_version=’1.9.0',
hyperparameters=hyperparameters,
compiler_config=TrainingCompilerConfig(),
disable_profiler=True,
debugger_hook_config=False
)
10. To launch your training job, call the fit method on the Estimator object, passing in your data locations specified in step 6.
huggingface_estimator.fit({‘train’: training_input_path, ‘test’: test_input_path}, wait=False)
Congratulations! You have now launched your first training job using the new SageMaker Training Compiler. You can track the progress of your training job from the SageMaker Service Console under “Training > Training Jobs”, and when training is complete your model will be output to S3, and ready for deployment. To see a completed example using the above techniques to fine-tune BERT-base-cased you can visit our AWS GitHub Examples page.
Conclusion
In this blog post, you learned about the new SageMaker Training Compiler, and how it can help you reduce the time it takes to train your deep learning models. We then walked through how you can get started with the new SageMaker Training Compiler using PyTorch and Hugging Face.
I encourage you to take what you heave learned here, and apply the SageMaker Training Compiler to your own use-cases. It is likely that you are already optimizing performance gains by using multi-GPU or even multi-node training methods. You will be pleased to know that the SageMaker Training Compiler can be adapted to these use-cases as well (see distributed training guidance in documentation, and find a multi-node multi-GPU example in our AWS GitHub Examples repository). You might also have use-cases that require using a different method than the Hugging Face Trainer API, and for these use-cases check-out how you can easily adapt your training scripts to continue leveraging the performance benefits of the SageMaker Training Compiler.
Speed up Hugging Face Training Jobs on AWS by Up to 50% with SageMaker Training Compiler was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3rwTYeQ
via RiYo Analytics






ليست هناك تعليقات