https://ift.tt/3rL18Mr Zero-Shot Sentiment Classification of Latin (with the Help of Its Descendants) An NLP approach for dead (and/or low...
Zero-Shot Sentiment Classification of Latin (with the Help of Its Descendants)
An NLP approach for dead (and/or low-resource) languages

Intro
Latin could be considered as “English of the old world”. I made the comparison with English to emphasize the fact that similar to how English is the most popular language in the world now, Latin dominated the ancient western world. It was not only in the sense of popularity but rather due to the influence of Roman expansions especially in Western Europe and the Mediterranean. However, Latin has directly shaped many modern languages (Romance languages) and also it has some influence on other languages as well (such as English). I had the idea to see how Latin would work in a modern-day Natural Language Processing (NLP) setting (using transformer-based pre-trained models) which I bring up in this short article.
Classical Latin is considered a dead language now, which puts it as a low-resource language in the NLP domain as well. The closest relatives to Latin are considered as Sardinian (or Sard) and Italian. Yet, they have mostly evolved from “Vulgar Latin”, a type of non-literary Latin that was popular among commoners. I hypothesized that an NLP task involving Latin (a sentiment classification task) would be helped by one of these languages, although a pre-trained model has not seen Latin during its pre-training phase. This is also known as zero-shot learning where we can transfer the knowledge from a related language to Latin, without being fine-tuned on a Latin corpus.
Method
Being a low-resource language, it is not easy to acquire an annotated corpus in Latin, with a substantial size. I used one accessible dataset[4][5] on the internet, which consists of 45 Latin sentences classified into 3 sentiment classes (POSITIVE, NEGATIVE, NEUTRAL, MIXED) and have been extracted from Horace’s Odes (The creators of the dataset have a soon-to-be-published paper using the same dataset, please check the reference). For simplicity, I removed the MIXED and NEUTRAL sentences. I used transformer-based fine-tuned monolingual models (for sentiment classification) available for Italian (Bert), English (Roberta), Spanish (Bert), German (Bert), and Indonesian (Roberta) on Huggingface. Sardinian is also a low-resource language (or at least sufficient resources do not exist online), hence it was discarded. The Latin dataset consists of sentences as below,
“quis scit an adiciant hodiernae crastina summae tempora di superi ”— negative
“non ego sanius bacchabor Edonis recepto dulce mihi furere est amico” — positive
The rest of the work was easy with Huggingface models and the usual steps were followed for each model (as mentioned in Huggingface as well). The results were obtained by feeding the tokenized Latin sentences directly into the fine-tuned models.
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import pandas
#Read the corpus
lat=pandas.read_csv('latin.tsv',sep='\t')
lat=lat[lat['Value']!='mixed']
lat=lat[lat['Value']!='neutral']
sentences=lat.loc[:,'Text']
labels=lat.loc[:,'Value']
true_val=map(lambda x:1 if x=='positive' else 0,labels)
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(“MilaNLProc/feel-it-italian-sentiment”)
model = utoModelForSequenceClassification.from_pretrained(“MilaNLProc/feel-it-italian-sentiment”)
#tokenize the sentences
inputs = tokenizer(list(sentences),padding=True, return_tensors="pt")
#first 4 lines can slightly change with the model, e.g.- for spanish model, outputs = model(**inputs),logits = outputs.logits
proba = torch.nn.functional.softmax(logits, dim=0)
labels = torch.tensor([0]*len(list(sentences)).unsqueeze(0)
outputs = model(**inputs, labels=labels)
loss, logits = outputs[:2]
logits = logits.squeeze(0)
prob = torch.nn.functional.softmax(logits, dim=0)
result=[]
for i in prob:
result.append(list(i.detach().numpy()).index(np.max(i.detach().numpy ())))
from sklearn.metrics import accuracy_score
accuracy_score(list(true_val),result)
#for some models, their output further needs to be processed in order to have numerical value
result=[]
for i in sentences:
result.append(1 if sentiment_analysis(i)[0]['label']=='POSITIVE' else 0)
For models including a pipeline for the task,
from transformers import pipeline
#Here the pytorch models are not created explicitly like in the previous snippet. Yet, the models gives an output similar to previous
sentiment_analysis = pipeline(“sentiment-analysis”,model=”siebert/sentiment-roberta-large-english”)
result=[]
for i in sentences:
result.append(1 if sentiment_analysis(i)[0]['label']=='POSITIVE' else 0)
accuracy_score(list(true_val),result)
Results
Genetic proximity is a measure used in Linguistics to measure the similarity or relatedness between a pair of languages. The higher its value, the more the distance between the pair of languages!. I used an online tool to measure the similarities between Latin and each of the other languages mentioned above. It shows the relationships as below.
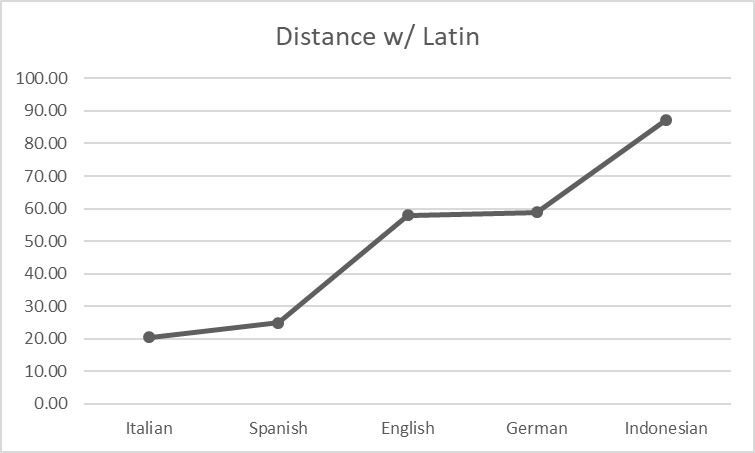
Romance languages like Italian and Spanish are closest to Latin while Germanic languages like English and German are placed a bit further. Indonesian is not related to Latin but Indonesian has adopted the Latin script in its Orthography. Let’s see how each model for the selected languages performed zero-shot classification. For the model with 3 class outputs (German), the few neutral/mixed predictions were changed to negative and positive separately, and the highest accuracy score among them was considered.
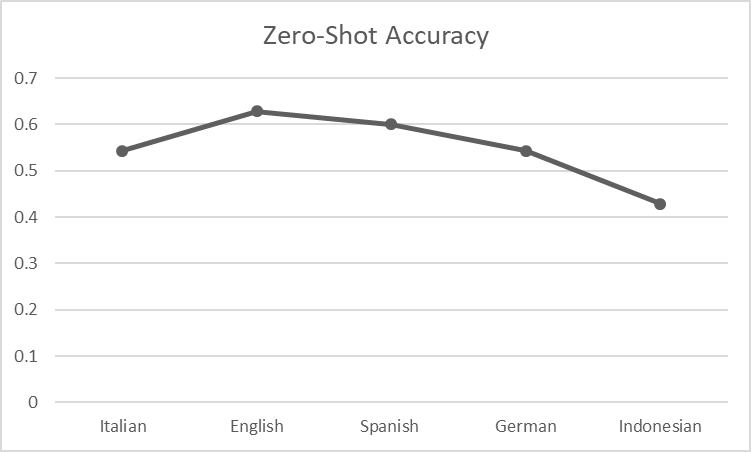
Surprisingly, the pattern of the relationships between languages does not appear here. The accuracy is >0.5 for every instance (except Indonesian) and Spanish shows the highest accuracy score for the Romance language. English shows the highest performance and while the closest language to Latin; Italian is behind it. Even though a language is distant from Latin, it doesn’t always imply performance degradation.
One possible reason for the outcome could be the model’s capabilities (which depend on the number of parameters in the model, pre-training objectives & corpora used to pre-train the model). Another main reason would be the size of the pre-trained/fine-tuned dataset used in each language model. The Italian model[1] was fine-tuned with an emotion dataset comprised of 2k tweets while the English model[2] has been fine-tuned on multiple datasets belonging to different domains as well (tweets, reviews, etc.). Spanish model[3] has utilized ~5k tweets for fine-tuning.
One could argue that the quality/size of the training corpora used for a model, directly affects its zero-shot performance, regardless of the source language. Furthermore, the model might be able to learn of the underlying representation of sentiments of sentences, irrespective of the language and the learned knowledge could be used during the zero-shot task for the target language. What do you think? Mention in the comments!!! This is not an extensive/complete set of experiments and analysis hence a firm conclusion cannot be made about the factors causing the result. Even the other available and untested models could unveil a new result. However, it was observed that language relatedness did not solely decide the zero-shot performance for sentiment classification in Latin. I believe that this is an interesting area of research.
Thank you for reading!
Reference
[1] — “FEEL-IT: Emotion and Sentiment Classification for the Italian Language, Bianchi et al.”, https://aclanthology.org/2021.wassa-1.8/
[2] — “More than a Feeling: Benchmarks for Sentiment Analysis Accuracy, Heitmann et al.”, https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3489963
[3] — https://github.com/finiteautomata/pysentimiento/
[4] — https://github.com/CIRCSE/Latin_Sentiment_Analysis
[5] — “Sentiment Analysis of Latin Poetry: First Experiments on the Odes of Horace., Mambrini et al.”, CLiC-it, 202, https://clic2021.disco.unimib.it/
Sentiments of Rome was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3lEWcoH
via RiYo Analytics








No comments