https://ift.tt/3EKvX7w RelevanceAI How to Create a Vector-Based Movie Recommendation System Building a movie recommendation system using ...
RelevanceAI
How to Create a Vector-Based Movie Recommendation System
Building a movie recommendation system using transformers and vector-based technology.
In this post, I am going to show you how to vectorize a movie dataset and at the end of the tutorial, I am going to complete the movie recommendation system using nearest neighbors. Full code available at my repo.
Movie recommendation systems are one of the most in-demand AI applications at the moment. There are several ways of building a movie recommendation system, from simple algorithms that are based on linear algebra equations to complex neural networks that attempt to predict which are the best options for a user.
Because technology has been advancing quite far in the past few years, new complex ways of building movie recommendation systems have been developed to enhance user experience in platforms like Netflix or TaoBao. Companies are only interested in the latest technology because it renders older models obsolete. At the moment, vector-based searches are dominating the recommendation system market.
In this post, I am going to download a movie dataset, clean it, encode it, and finally perform a vector search on it: the software will have one movie as input and will recommend 5 movies as output.
Building the software
This movie recommendation system will be built by following these steps:
- Install libraries
- Download dataset
- Preprocess dataset
- Encode data
- Perform vector search
1. Install libraries
The main library I am going to use to encode data is relevanceai, which puts at your disposal the latest transformers to encode your data:
!pip install -U relevanceai
I am also going to install a second library that will allow us to keep track of the encoding progress while our PC is working. Because the process can be quite long (can take up to 2 hours) if you wish not to use to already encoded dataset I am putting at your disposal, is better to use a progress bar that you can implement with a library called tqdm:
!pip install tqdm>=4.62.2
2. Download movie dataset
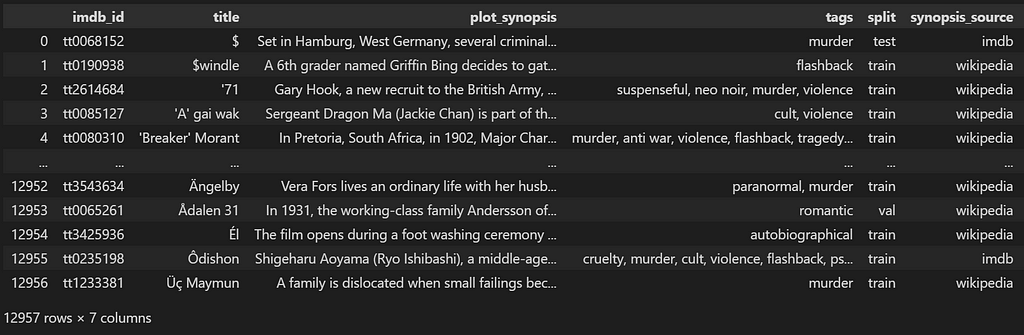
The original dataset has been downloaded from Kaggle (MPST: Movie Plot Synopses with Tags, published by Sudipta Kar). I will be using the pandas library to work with this dataset. The only two kinds of data that we need for the process (I will keep it simple enough) are the movie title and description. The title will be used by users to reference the movie they want to see, while the description of the movie will be encoded in the vector space. After encoding the data, we no longer need the movie description anymore.
import pandas as pd
df = pd.read_csv('mpst_full_data.csv')
3. Preprocess movie dataset
Apart from getting rid of all the other extra features that will not serve in our experiment, the movie dataset also contains duplicates that are not perfectly identical, hence we cannot simply use a drop_duplicates pandas function to get rid of them. For example, I have found the same movie with similar titles: “The Avengers” and “Avengers”.
During the preprocessing phase, I will need to make sure that most of the duplicates are deleted from our data, otherwise, the user experience won’t be the same as a well-functioning recommendation system.
To avoid duplicate names I am only going to focus on the movie titles. There are several ways to address this problem, I have been building an algorithm out-of-the-box for this specific purpose: I am going to sort the titles alphabetically, then see if consecutive titles are similar (by employing the Levenshtein distance) and if they are I will delete the consecutive one.
df = df.sort_values('title').reset_index(drop=True)
df['lev'] = None
df
from Levenshtein import distance
for a in range(len(df)-1):
if distance(df.iloc[a].title, df.iloc[a+1].title) <= 3:
print(a, df.iloc[a].title, df.iloc[a+1].title)
df.at[a, 'lev'] = distance(df.iloc[a].title, df.iloc[a+1].title)
df
#we filter similar movies
df = df[df['lev'].isnull()].reset_index(drop=True)
df
For some very renowned movies, I am going to perform a manual check myself to avoid any issue: the first movie I am going to try this software with is obviously Avengers:
#find Avengers duplicates
for a in range(len(df)):
if df.iloc[a]['title'].find('Avengers') != -1:
pass
#print(a)
#drop extra
df = df.drop([9572]).reset_index(drop=True) #i can do 1, 2, 3... to drop multiple
df
df.to_csv('mpst_no_duplicates.csv')
4. Encode data
If you wish to know more in detail what transformers are and what are other viable choices to encode your data, you can follow my post with technical explanations. There are several models you can choose from: the fastest one (the one I'm going to use) is called all-MiniLM-L6-v2. There are also more complex models like all-mpnet-base-v2, they are much more precise, but they require a lot of computing power. For example, by using this last model, instead of 2 hours our computer may need 10.
In this code, I am going to use the relevanceai API to encode the movie descriptions into vectors. I am used to using this library as it is a much more flexible wrapper than many of its alternatives. Because it does not directly accept pandas DataFrame as inputs, I will need to convert my data into a list of dictionaries:
json_files = df[['title', 'plot_synopsis']]
json_files = json_files.reset_index()
json_files.columns = ['_id', 'title', 'plot_synopsis']
json_files=json_files.to_dict(orient='records')
json_files
This is how the files will look like:
{'_id': 0,
'title': '$',
'plot_synopsis': 'Set in Hamburg, West Germany, sev...
{'_id': 1,
'title': '$windle',
'plot_synopsis': 'A 6th grader named...
{'_id': 2,
'title': "'71",
'plot_synopsis': "Gary Hook, a new recruit to the British Army, takes leave of ...
Now we can begin the encoding process by choosing one of the available models.
#encode on local
from vectorhub.encoders.text.sentence_transformers import SentenceTransformer2Vec
model = SentenceTransformer2Vec("bert-base-uncased")
df_json = model.encode_documents(documents=json_files, fields=['plot_synopsis'])
df_json
Once encoded, instead of replacing the original field, plot_synopsis, the relevanceai library is creating another field with the sentence_transformers_vector_ suffix.
[{'_id': 0,
'title': '$',
'plot_synopsis': 'Set in Hamburg, West Germany, several criminals take...
'plot_synopsis_sentence_transformers_vector_': [-0.25144392251968384,
-0.03958860784769058,
0.15455105900764465,
-0.08302052319049835,
0.5842940807342529,
0.07232926040887833,
0.28563958406448364
4. Encode data with pandas
Alternatively, if you wish to proceed with pandas you can still use the sentence-transformers library. Choosing different formats depends on which use you wish to make of your data: in the previous format, for example, I can use the relevanceAI API to upload my data online, so that is scalable and can be used by thousands of users.
Because the process may require more than one hour to complete (some encoding models may require up to 12 hours, so be careful in which one you pick), I am keeping track of the progress by using a progress bar (for more information to implement it, I wrote this fun guide):
from tqdm import tqdm
from sentence_transformers import SentenceTransformer
import numpy as np
tqdm.pandas()
model = SentenceTransformer('all-MiniLM-L6-v2') #all-MiniLM-L6-v2 #all-mpnet-base-v2
df_ = df.copy()
df_['plot_synopsis'] = df_['plot_synopsis'].progress_apply(lambda x : model.encode(x))
df_index = df_.pop('title')
df_ = df_[['plot_synopsis']]
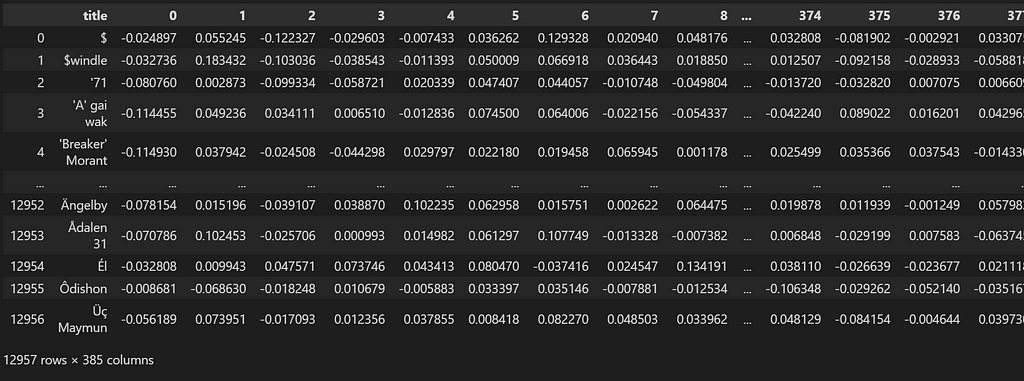
df_ = pd.DataFrame(np.column_stack(list(zip(*df_.values))))
df_.index = df_index
df_
Let’s not forget to save your data into a .csv file when we are done!
df_.to_csv('mpst_encoded_no_duplicates.csv')
5. Perform a vector search: test your movie recommendation system
By performing a vector search, I will input one movie into the dataset. As a result, the software will find what the closest 5 points in space are, each one representing a similar movie: this is what we call a recommendation system.
The solution that I am providing will perfectly work on your local machine. However, the issue when deploying vectors-based products is scaling. One of the best solutions I found is the relevanceai API, which you can use to transform your vector database into an API call.
To perform the vector search on your local, instead, I can use the sklearn API that provides me with the nearest neighbor algorithm. The first thing I am going to do is load the dataset again (you do not need to, but is a good practice to separate each code section with an import and an export of the same dataset):
import pandas as pd
df_movies_encoded = pd.read_csv('mpst_encoded_no_duplicates.csv')
df_movies_encoded.index = df_movies_encoded.pop('title')
df_movies_encoded
We can now train the algorithm on a Nearest Neighbor sklearn class: we will store the trained model in a variable called nbrs, this will allow us to retrieve two points given one input (the coordinates of the initial point plus the coordinates of its closest neighbor).
from Levenshtein import distance
from sklearn.neighbors import NearestNeighbors
import numpy as np
import pandas as pd
nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(df_movies_encoded)
#string-searching algorithm
def closest_title(title):
m = pd.DataFrame(df_movies_encoded.index)
m['lev'] = m['title'].apply(lambda x : distance(x, 'Prince of Egypt'))
return m.sort_values('lev', ascending=True)['title'].iloc[0]
The main issue with the current dataset is in the case of searching a movie that is not in the dataset, or if you make a typo. For example, if you search for “The Avengers”, because the dataset only has the word “Avengers” in it, it will not be able to search for your keyword and will throw an error. This is quite inconvenient, especially because we are assuming that many users are going to quickly type the search, even committing typos. The solution to this problem is using a string-search algorithm that no matter what we type in, will find the best possible answer. I created a custom one using the Levenshtein distance:
def find_similar_movies(df, nbrs, title):
#if title not in df it will choose the best search
title = closest_title(title)
distances, indices = nbrs.kneighbors([df.loc[title]])
#print(indices)
#we print df data, no longer df_
for index in indices[0][1:]:
print('index', index)
print(title, '->', df.iloc[index].name)
The algorithm will receive the name of a movie as an input and will output the name of the closest neighbor:
find_similar_movies(df_movies_encoded, nbrs, 'Prince of Egypt')
index 11440
The Prince of Egypt -> The Ten Commandments: The Musical
Wonderful: seems to be working!
Conclusion
In this post, I have shown you how to build a simplified recommendation system. Have we reached the peak of complexity for this category of tasks? Not even close. In this tutorial, we are using a single vector space that contains the relationships of all movies in a dataset, but we are ignoring the individual user history.
To provide an enhanced experience for every user on the platform we should collect its choice history and create a unique recommendation for every user. The only models capable of reaching this level of complexity are called multi-modal embeddings, and they will be analyzed in further articles. With its limitations, a vector-spaced movie recommendation system like this one is still able to perform very well and provide a satisfactory user experience.
How to create a Vector-Based Movie Recommendation System was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/31CdqfD
via RiYo Analytics








No comments