https://ift.tt/3EloZpl The only re:invent AI/ML launch summary you’ll need Illustration by author It’s the most wonderful time of the y...
The only re:invent AI/ML launch summary you’ll need

It’s the most wonderful time of the year — for machine learning in the cloud that is. AWS announced several exciting services for AI and machine learning this week at re:invent 2021. In this post I’m going to break down all the ML deliciousness for you, service by service. I’ve categorized all the interesting AI/ML launches into 7 different ML use-cases, so you can pick and choose the section that’s most relevant to your interests:
- ML for everyone
- ML training
- ML inference
- ML and data science workflows
- ML data processing and labeling
- ML hardware
- ML for non-developers
Sounds good? Let’s get started!
1. ML for everyone
Amazon SageMaker Studio Lab
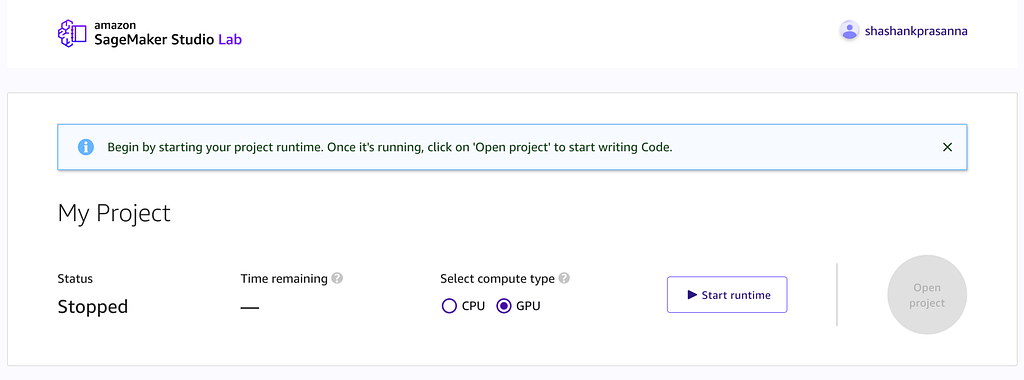
What is it?
Amazon SageMaker Studio Lab a free hosted JupyterLab service where you can run your machine learning (ML) projects without the need for an AWS account, credit card or cloud configuration skills. If you’re a developer, data scientist, student or someone dipping their toes in ML and data science, you’ll need access to CPU and GPU compute resources. SageMaker Studio Lab has got you covered, simply create an account and you get access to a free ML development environment in the cloud. Simple as that.
How does it work?
SageMaker Studio Lab gives you free access to a hosted JupyterLab with a choice of a CPU-only or a GPU backend. If you choose CPU-only backend you get 12 hours of compute time, which is plenty for a lot of data pre-processing with Pandas and classical ML algorithm training with sci-kit learn or XGBoost. For deep learning training, choose the GPU backend to get 4 hours of compute time, which is plenty for training or fine tuning models on smaller datasets. You can restart the Studio lab project immediately after you hit the time limit to start a new session. Your data including training checkpoints will persist between sessions.
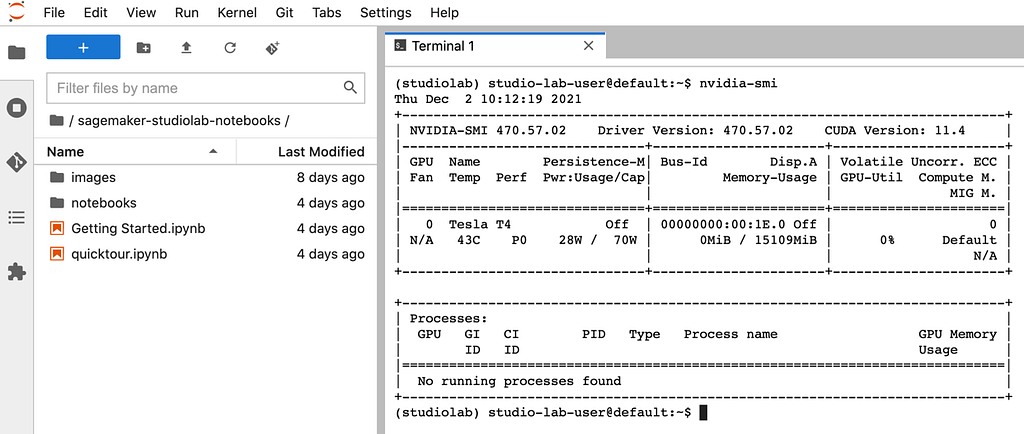
Who is it for? When should you use it?
Like so many, I trained my very first ML model on my laptop purchased on a student’s budget and soon realized I needed access to GPUs to train more complex deep learning models. Studio Lab is anyone who wants a quick, easy and painless way to access compute resources for machine learning. You could use Studio Lab to work on your school assignments, compete in Kaggle competitions or do ML research. Personally, I’m going to use Studio Lab to prototype models first before moving it to Amazon SageMaker to run larger scale experiments or train on larger datasets.
2. ML training
Amazon SageMaker Training Compiler
What is it?
SageMaker Training Compiler is an optimizing compiler for machine learning models designed to speed up training. It accelerates model training by analyzing the model’s computational graph and finding opportunities to better take advantage of GPU resources. The end result is that you can get performance improvements without making any code changes to your training scripts.
How does it work?
A model’s computational graph offers many opportunities for simplifications. For example, when you train your model on GPUs without a training compiler, operation in your model’s computational graph get executed as a separate GPU kernel function call. This adds function call overhead with each additional kernel call you make. An optimizing compiler can identify such inefficiencies because it can look at the complete graph vs. independent functions that a framework interpreter would see. The compiler can then fuse or combine operators resulting in fewer kernel function calls on the GPU. The compiler can also look at the entire graph to make better decisions on memory planning and tensor layout transformations to further speed up training.
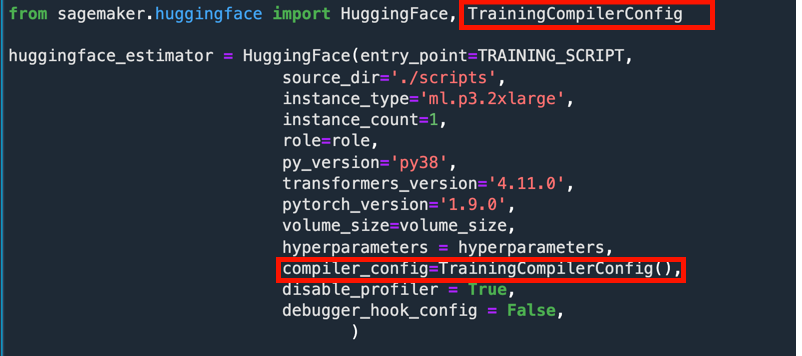
Who is it for? When should you use it?
If you’re training deep learning models, you’ll benefit from SageMaker Training Compiler. Few models are supported at launch including alarge number of HuggingFace models, and you could get some free speedup without making any code changes. The idea of compiling models definately not new and several model compilers exist for inference deployment such as SageMaker Neo, TVM and NVIDIA TensorRT. This is because performing graph optimizations for forward-pass only is relatively simple. During training, you have forward-pass and backward-pass which makes the compiler’s job that much harder. I’m excited to see Training Compiler support in SageMaker and look forward to using it on HuggingFace models today and I’m going to keep any eye out for other models it’ll support in the future.
There were other hardware training related launches at re:invent 2021, which I’ll cover in a dedicated section below called “ML Hardware”. For now, let’s move on to ML Inference services launches.
3. ML inference
Amazon SageMaker Serverless Inference [Preview]
What is it?
Amazon SageMaker Serverless Inference is a model hosting feature that lets you deploy endpoints for inference that automatically starts and scales the compute resources based on traffic. With SageMaker Serverless Inference you don’t have to manage instance types and you only pay for prediction requests and time taken to process those requests.
How does it work?
If you use other serverless services on AWS such as Lambda, Fargate, SQS, and others, then you should expect similar benefits when using Serverless Inference. With serverless deployments you don’t have to provision Amazon EC2 instances or manage them or scale them based on demand and traffic. SageMaker Serverless Inference will do all of that for you making it easy to deploy and scale ML models for inference.
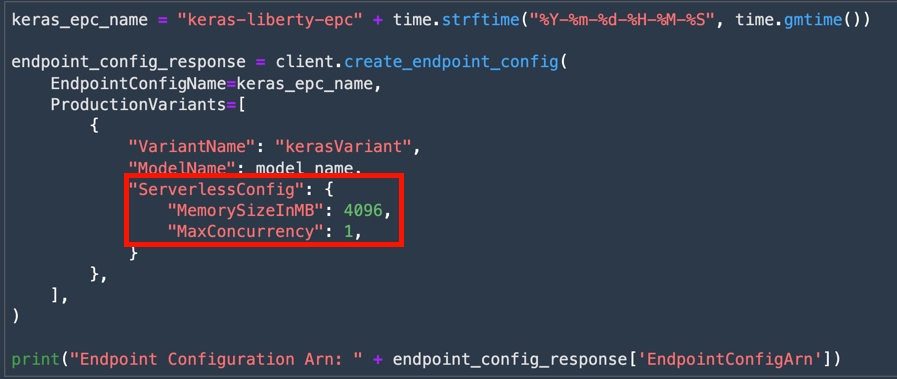
Who is it for? When should you use it?
If you are already using SageMaker to host inference endpoints, it’s easy to switch to Serverless endpoints from realtime endpoints by simply updating your endpoint configuration. If you expect your traffic to be sporadic in nature, such as variable number of requests at different times in the day, and you don’t have strict response latency requirements, then you should start with SageMaker Serverless Inference. Serverless Inference endpoints will experience a cold start period if it’s been idle, so if you have a latency critical application that simply cannot tolerate lower latency at any point in time, you should switch over to realtime endpoints which are backed by a dedicated ml CPU or GPU instance type of your choosing. For everything else, Serverless Inference is a no-brainer option.
Amazon SageMaker Inference Recommender
What is it?
Amazon SageMaker Inference Recommender speeds up the process of finding the right compute instance type for your model deployment that gives you the highest performance at the lowest cost. SageMaker Inference Recommender does this by automating the process of instance type discovery by automatically running performance benchmarking and tuning model performance across SageMaker ML instances.
How does it work?
SageMaker supports over 60 instance types and counting, and selecting the right one to meet your deployment goals can be time consuming. You can use SageMaker Inference Recommender to run a default recommendation job or specify a custom performance benchmark on a selected set of instances to simulate performance for your production deployments. You likely have a target throughput, latency and you can specify those along with a sample payload to run tests on. This process typically takes a couple of hours or longer depending on the model and custom options, and the results can be viewed in SageMaker Studio or analyzed in Studio notebook using popular libraries like Pandas.
Inference Recommender expects your model to be packaged in the model registry. The benefit of registering your model by creating a model package group is that you can include additional metadata such as serving container, model domain (computer vision, NLP etc.), task (classification, regression etc.), framework (TensorFlow, Pytorch), framework version sample payload and others. Once the model is registered, Inference Recommender will handle the rest.
After the benchmarking is complete you can review the results and evaluate tradeoffs of different endpoint configurations across multiple dimensions such as latency, throughput, cost, compute usage, and memory usage.
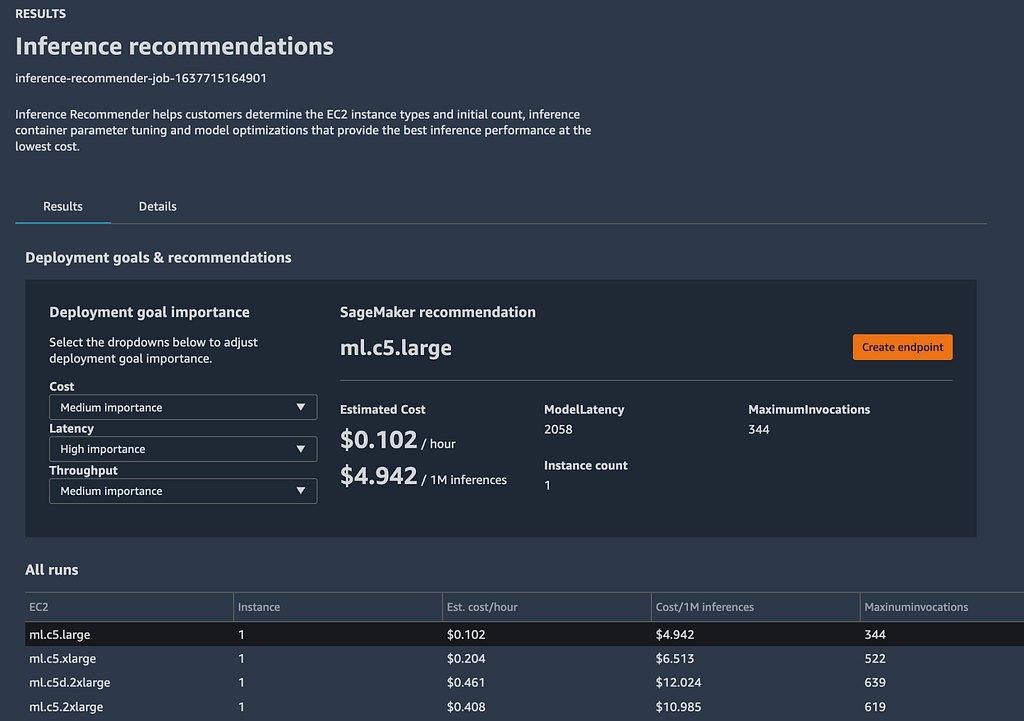
Who is it for? When should you use it?
If you currently have models in production, chances are that you’ve been manually benchmarking multiple CPU and GPU instance sizes to determine the right instance that meets your target latency and throughput requirements and calculate costs of deployment on each instance to pick the most performant instance type for your budget. If this person is you, then Amazon SageMaker Inference Recommender will save you days if not weeks worth of effort by automating the process. If this person is not you, then you don’t have to become that person. Use Amazon SageMaker Inference recommender and save yourself precious time.
4. ML and data science workflows
Amazon SageMaker Studio integration with Amazon EMR
What is it?
Amazon SageMaker Studio introduces deeper integration with Amazon EMR enabling you to not only view existing EMR clusters but also create, monitor and debug Spark jobs running on EMR without leaving your SageMaker Studio interface. With this integration, you can spin up an Amazon EMR cluster within the SageMaker Studio interface, perform data preprocessing using the SageMaker spark library and then train and host your models in SageMaker. What you get is an end-to-end data pre-processing to deployment workflow under one SageMaker Studio user interface.
How does it work?
A typical setup is to use AWS Service Catalog to define and roll out preconfigured templates that allow SageMaker Studio users to create EMR clusters right from Studio. After this initial setup process typically performed by your DevOps administrator, or a highly talented data scientist, your Studio environment is ready to create EMR clusters, connect to it, monitor and debug Spark jobs using Spark UI. To run Spark jobs you can use Sparkmagic which allows you to run Spark code within Jupyter Notebook against the remote EMR cluster that you created within Studio. Sparkmagic also creates an automatic SparkContext and HiveContext.
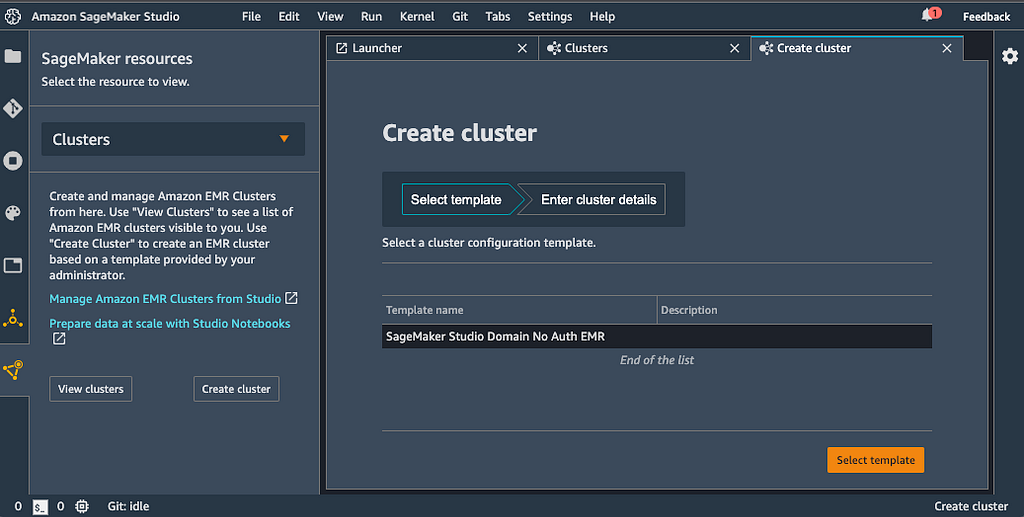
After you’re done using the cluster, you can also terminate it within the Studio interface.
Who is it for? When should you use it?
If you’re a data engineer or data scientist who uses Apache Spark, Hive, or Presto running on Amazon EMR to do data preparation, and also need to develop models, train, tune and deploy them in Amazon SageMaker, then this integration between SageMaker Studio and Amazon EMR will make your life much easier. I see this is one step closer to an ideal fully integrated development environment that you never have to leave, whether you’re performing data pre-processing or model deployment.
5. ML data labeling
Amazon SageMaker Ground Truth Plus
What is it?
Amazon SageMaker Ground Truth Plus a data labeling service that that uses an AWS-managed workforce to deliver high-quality annotations without the need for you to build labeling applications and manage a labeling workforce. Initiating an Amazon SageMaker Ground Truth Plus project puts you in touch with AWS teams who’ll work with you to understand your use case, label volume, and timeline requirements. On project approval, your datasets will be labeled by a highly-trained AWS-managed workforce using already available SageMaker Ground Truth features. This means you don’t have to engage multiple labeling vendors or build a labeling workforce in-house, you can use Ground Truth Plus service only when you need data to be labeled, freeing the time of your data scientists and ML experts allowing them to focus on model development and deployment.
How does it work?
As a user of SageMaker Ground Truth Plus, you are responsible for defining your project goals and providing the dataset, and the output is high-quality data labels in your S3 bucket which you can use to build, train, and deploy machine learning (ML) models using services such as Amazon SageMaker. Behind the scenes, SageMaker Ground Truth Plus combines ML assisted pre-labeling, human expert labeling and ML assisted validation of human labels to detect human errors and low-quality labels. SageMaker Ground Truth Plus also provides you with a window into the data labeling operations for quality control. You can monitor progress, view labeling metrics on a dashboard and provide feedback on the output dataset.
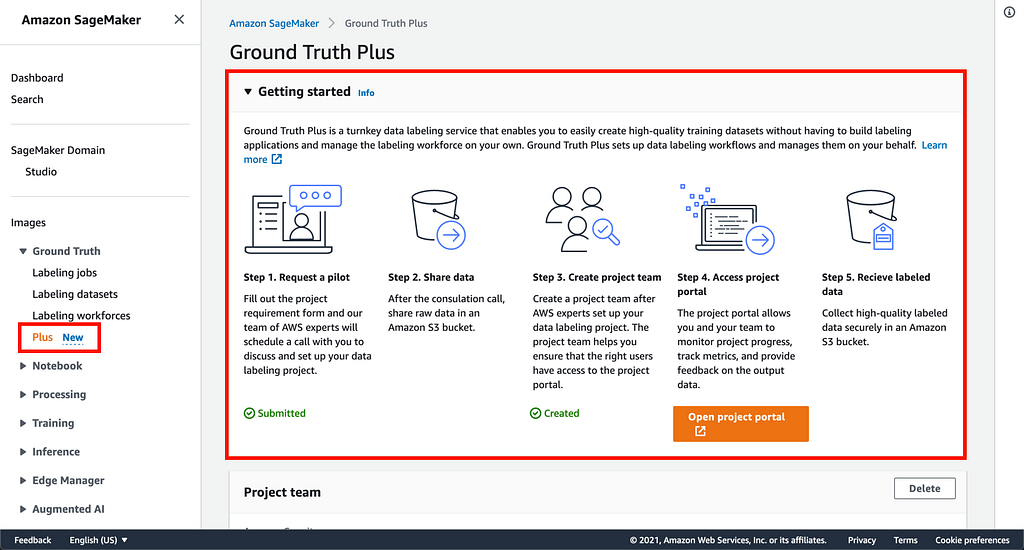
Who is it for? When should you use it?
SageMaker Ground Truth Plus is for the person in your organization that is responsible for producing high-quality labeled datasets used by the ML teams. This person is an expert on the data domain and business problem, and needs an end-to-end labeling solution. In smaller teams or organizations this could be you the data scientist, or in larger teams or organizations it could be a dedicated Data Operations manager. Regardless of what your role is, you don’t want to manage labeling workforces for the varying labeling demands throughout the year, but want quality labeled data delivered in a timely manner to your AI/ML teams.
6. ML Hardware
Amazon EC2 G5g instances powered by AWS Graviton2 processors
What is it?
Amazon EC2 G5g is the latest addition to the wide list of GPUs instances available on AWS today. G5g is the first instance to pair an NVIDIA GPU with AWS Graviton2 CPU.
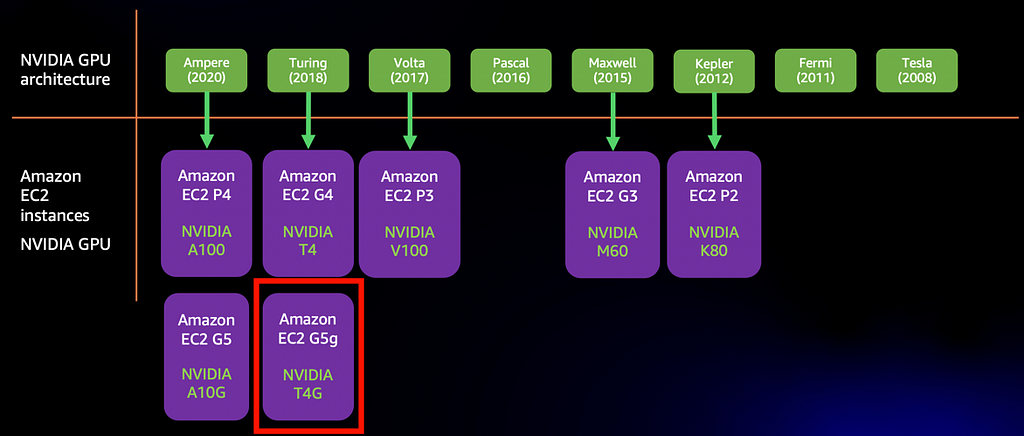
Who is it for? When should you use it?
EC2 G5g instance is a cost effective option for machine learning inference deployments making it an alternative to EC2 G4 and EC2 G5 which are based on Intel CPUs. NVIDIA offers Deep Learning Amazon Machine Image on AWS Marketplace which comes preconfigured with all the necessary NVIDIA drivers, libraries, and dependencies to run Arm-enabled software on EC2 G5g.
Amazon EC2 Trn1 instances [Preview]
What is it?
Amazon EC2 Trn1 instances are powered by AWS Trainium, a high-performance ML training chip designed by AWS to accelerate training workloads. Trn1 instances are the first EC2 instances with up to 800 Gbps of network throughput, 2x the networking throughput of GPU-based EC2 instances. They also support ultra-high-speed interconnect between accelerators to deliver the fastest ML training in the cloud.
Who is it for? When should you use it?
EC2 Trn1 is based on AWS Trainium accelerator which is the 3rd accelerator type on AWS for ML training, after NVIDIA GPUs and Intel’s Habana Gaudi. If you’re using GPUs today, and are pushing the limits of the P4d.24xlarge GPU instance, then Trn1 should be on your radar when it comes out of preview. Trn1 is also the second instance type to include a chip designed by AWS, the first being Inf1 instances with Inferentia accelerators designed for inference. To accelerate your models on Inf1 you need to use AWS Neuron SDK, and the same SDK will not also support Trn1 instances for training workflows.
Overall I’m happy to see so many accelerator choices for ML practitioners. I’m excited to test this out when it becomes available, and you can bet that I’ll have a deep dive blog post ready for you to read soon after it’s available.
7. ML for non-developers
Amazon SageMaker Canvas
What is it?
Amazon SageMaker Canvas provides a visual point and click interface to create machine learning models and generate predictions without writing any code. It’s UI provides you with options to access datasets, create joins, select target variable column. Then it trains multiple models automatically and lets you visually analyze model performance, generate predictions.
How does it work?
Canvas supports CSV file types from Amazon S3 or local upload. You can also import from Amazon Redshift, or SnowFlake with the option to perform Joins and SQL queries for more control over the importing process. After you’ve imported your dataset, you can combine datasets with left, right, inner and outer joins. When you’re happy with your dataset, you can select your target column that you want to predict. SageMaker Canvas will automatically determine the type problem type — binary or multi-class classification or regression. When you initiate training it will build up to 250 models and choose the one that performs the best. Best is subjective, so you can preview the model, take a look at it’s estimated accuracy and use it to generate predictions on new datasets.
Note: As an ML educator and practitioner, it behooves me to tell you to use your trained models responsibly. Models can be biased, datasets can be biased. To quote the famous statistician George Box “All models are wrong, some are useful”. Use your best judgement on how useful your trained models are regardless of how easy it is to train them.
Who is it for? When should you use it?
After reading this post, if your first instinct is to test SageMaker Training Compiler, it may be safe to assume SageMaker Canvas is not for you. SageMaker Canvas can simplify model development for data analysis and other statistics oriented job roles who have a need to build predictive models, but don’t necessarily have the skills to code in python or use SageMaker Studio. If you have the skills to interpret datasets, understand data distributions, and data imbalances, and recognize good and poor datasets, and how missing data can impact predictions, SageMaker Canvas can fill in the model development gaps, so you can focus on being the data and domain expert.
Re:cap
I found this to be one of the most exciting re:invents as far as AI/ML launches were concerned, here’s why.
We got a service that is really easy to use with SageMaker Canvas, and we got a service that is free and accessible to everyone including students with SageMaker Studio Lab. We got a service that expert data scientists can rely on to speed up training with SageMaker Training Compiler, and we got a service to help data scientists figure out the best instance to host their model with SageMaker Inference Recommender. And we got a service to host models without managing instances with SageMaker Serverless Inference. We got a service for data labeling project managers to get high-quality labeled datasets with SageMaker Ground Truth Plus. Finally we got new accelerators for training and inference with Trn1 and G5g which only means more choice for developers. We got an AI/ML service for everyone!
- ML for everyone: Amazon SageMaker Studio Lab
- ML training: Amazon SageMaker Training Compiler
- ML inference: Amazon SageMaker Serverless Inference, Amazon SageMaker Inference Recommender
- ML and data science workflows: Amazon SageMaker Studio integration with Amazon EMR
- ML data processing and labeling: Amazon SageMaker Ground Truth Plus
- ML hardware: Amazon EC2 G5g, Amazon EC2 Trn1
- ML for non-developers: Amazon SageMaker Canvas
That’s everything folks! If you enjoyed reading this summary, feel free to follow me here on medium, twitter and LinkedIn. I’ll be busy the next few weeks doing deeper dive content on each of these services, and you wouldn’t want to miss that. See you in the next blog post!
AWS re:invent 2021 AI & Machine Learning Launches: 7 Things You Should Know was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3diYXHm
via RiYo Analytics






ليست هناك تعليقات