https://ift.tt/30s04S5 — a detailed log structure for ETL pipelines! credits- Burst As part of my work, I have been converting some of ...
— a detailed log structure for ETL pipelines!

As part of my work, I have been converting some of my ETL jobs developed on the traditional tool-based framework into a python framework and came across a few challenges. These few challenges are orchestration, code management, logging, version control, etc. For a few of them, there was not much effort required while developing them on a tool. But, in hand-written code like python ETL’s, these are quite a challenge! And this brings to one such challenge, our topic today!
Also instead of describing much on ‘how’, as there are many good articles already on a platform, our main focus today is ‘What’.
Glossary:
- Introduction
- ETL Skeleton
- Structure of Log!!
- Sample ETL job with our log structure.
- Code Location.
Introduction: When we design and develop ETL pipelines on tools we focus on components like sources, target objects, transformation logic, and a few support tasks to handle pipelines. These tools will also generate logs for all jobs that are actively running and can be monitored with their internal interfaces. Basically, I mean to say developing/maintaining logs is not a challenging activity in the tool. whereas on python, it is a separate activity that needs to be handled. Today, In our post we will discuss the basic skeleton of ETL jobs, a rough idea of details we can record in any pipeline, then later we structure them into our ETL code, and finally, we will develop a sample scenario with logs recorded.
ETL Skeleton: As we already know there are different kinds of ETL jobs like Merge/Upsert process, Staging loads, SCD 2 loads, Delta jobs, direct insert loads, etc. all these ETL jobs have a very basic structure(shown below in python) and i.e. the main function to call the modules in the pipeline, extract module, transformation module, and load module, Now, we can take the below Skeleton to also identify what could be our ETL log look like.
def extract():
pass
def transformation():
pass
def load():
pass
def main():
extract()
transformation()
load()
if __name__=="__main__":
main()
Structure of Log: As we outlined the blueprint of the ETL job, let’s try to list down a rough idea of what details we can track from a job.
A list of details we can log —
- display initialized elements/components like folder location, file location, server id, user id details, process details in a job
- display extract stage details, like source file name, source file count if needed, the format of the file, file size, source table name, source DB connection details(except any secret credentials(user/passwords)), any exception or errors if file/source table missing or failed to fetch data messages.
- display transformation stage details — like failed/exception messages if out of memory during data processing, any data/format conversion details if required.
- display load stage details like file/target locations, number of records loaded, failed to load, constraints of any DB loads, load summary details.
- display job summary like process run time, memory usage, CPU usage, these can also be tracked at extract, transform and load level to evenly identify bottlenecks of job.
Now let’s integrate the above details in our ETL skeleton and see how could be our log structure looks like!
##basic config
##logging.config.fileConfig('logging.conf')
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
#job parameters config
config = configparser.ConfigParser()
config.read('etlConfig.ini')
JobConfig = config['ETL_Log_Job']
formatter = logging.Formatter('%(levelname)s: %(asctime)s: %(process)s: %(funcName)s: %(message)s')
##creating handler
stream_handler = logging.StreamHandler()
file_handler = logging.FileHandler(JobConfig['LogName'])
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
def extract(counter):
logger.info('Start Extract Session')
try:
pass
except ValueError as e:
logger.error(e)
logger.info("extract completed!")
def transformation(counter):
logger.info('Start Transformation Session')
pass
logger.info("Transformation completed,data ready to load!")
def load(counter):
logger.info('Start Load Session')
try:
pass
except Exception as e:
logger.error(e)
def main():
start = time.time()
##extract
start1 = time.time()
extract()
end1 = time.time() - start1
logger.info('Extract CPU usage {}%'.format(psutil.cpu_percent()))
logger.info("Extract function took : {} seconds".format(end1))
##transformation
start2 = time.time()
transformation()
end2 = time.time() - start2
logger.info('Transform CPU usage{}%'.format(get_cpu_usage_pct()))
logger.info("Transformation took : {} seconds".format(end2))
##load
start3 = time.time()
load()
end3 = time.time() - start3
logger.info('Load CPU usage {}%'.format(psutil.cpu_percent()))
logger.info("Load took : {} seconds".format(end3))
end = time.time() - start
logger.info("ETL Job took : {} seconds".format(end))
logger.info('Session Summary')
logger.info('RAM memory {}% used:'.format(psutil.virtual_memory().percent))
logger.info('CPU usage {}%'.format(psutil.cpu_percent()))
print("multiple threads took : {} seconds".format(end))
if __name__=="__main__":
logger.info('ETL Process Initialized')
main()
And, if you observe the above code structure, I have created a config file to maintain all job level details. By importing this file into your code you can make use of different parts of the code including for logging.
etlConfig.ini :
##ETL jobs Parameters
[ETL_Log_Job] ##Job name
Job_Name = etl_log_job.py
LogName = etl_log_job.log
TgtConnection = Customers.db
SrcConnection = Customers.db
SrcObject = customer_file.csv
TgtObject = customer
##Add more job details as needed
Sample ETL job with our log structure:
import logging.config
import time
import psutil
import configparser
import pandas as pd
import sqlite3
##basic config
##logging.config.fileConfig('logging.conf')
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
#job parameters config
config = configparser.ConfigParser()
config.read('etlConfig.ini')
JobConfig = config['ETL_Log_Job']
formatter = logging.Formatter('%(levelname)s: %(asctime)s: %(process)s: %(funcName)s: %(message)s')
##creating handler
stream_handler = logging.StreamHandler()
file_handler = logging.FileHandler(JobConfig['LogName'])
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
def extract():
logger.info('Start Extract Session')
logger.info('Source Filename: {}'.format(JobConfig['SrcObject']))
try:
df = pd.read_csv(JobConfig['SrcObject'])
logger.info('Records count in source file: {}'.format(len(df.index)))
except ValueError as e:
logger.error(e)
return
logger.info("Read completed!!")
return df
def transformation(tdf):
try:
tdf = pd.read_csv(JobConfig['SrcObject'])
tdf[['fname', 'lname']] = tdf.NAME.str.split(expand=True)
ndf = tdf[['ID', 'fname', 'lname', 'ADDRESS']]
logger.info('Transformation completed, data ready to load!')
except Exception as e:
logger.error(e)
return
return ndf
def load(ldf):
logger.info('Start Load Session')
try:
conn = sqlite3.connect(JobConfig['TgtConnection'])
cursor = conn.cursor()
logger.info('Connection to {} database established'.format(JobConfig['TgtConnection1']))
except Exception as e:
logger.error(e)
return
#3Load dataframe to table
try:
for index,row in ldf.iterrows():
query = """INSERT OR REPLACE INTO {0}(id,fname,lname,address) VALUES('{1}','{2}','{3}','{4}')""".format(JobConfig['TgtObject'],row['ID'],row['fname'],row['lname'],row['ADDRESS'])
cursor.execute(query)
except Exception as e:
logger.error(e)
return
conn.commit()
logger.info("Data Loaded into target table: {}".format(JobConfig['TgtObject']))
return
def main():
start = time.time()
##extract
start1 = time.time()
tdf = extract()
end1 = time.time() - start1
logger.info('Extract CPU usage {}%'.format(psutil.cpu_percent()))
logger.info("Extract function took : {} seconds".format(end1))
##transformation
start2 = time.time()
ldf = transformation(tdf)
end2 = time.time() - start2
logger.info('Transform CPU usage {}%'.format(psutil.cpu_percent()))
logger.info("Transformation took : {} seconds".format(end2))
##load
start3 = time.time()
load(ldf)
end3 = time.time() - start3
logger.info('Load CPU usage {}%'.format(psutil.cpu_percent()))
logger.info("Load took : {} seconds".format(end3))
end = time.time() - start
logger.info("ETL Job took : {} seconds".format(end))
##p = psutil.Process()
##ls = p.as_dict()
##print(p.as_dict())
logger.info('Session Summary')
logger.info('RAM memory {}% used:'.format(psutil.virtual_memory().percent))
logger.info('CPU usage {}%'.format(psutil.cpu_percent()))
print("multiple threads took : {} seconds".format(end))
if __name__=="__main__":
logger.info('ETL Process Initialized')
main()
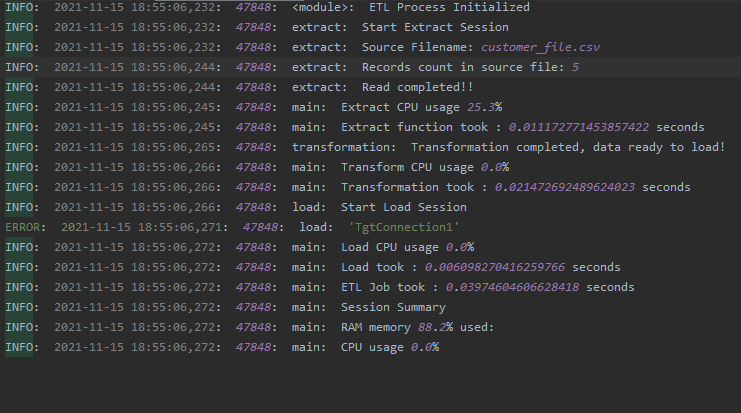
##Log output for above sample job
Few more improvements we can do to our Log:
- By implementing config/parameter files for jobs it would also be easy to maintain job logging.
- We can add system-level summary details to later optimize or identify bottlenecks in our jobs. being able to identify CPU performance/usage of extract, transform and load can help developers more.
- If we are loading in targets, try to keep track of the load summary, which will help to identify the consistency of data loaded.
- The logging module in python is simple and effective to use in ETL jobs.
- also providing process id or thread id details could be helpful later to troubleshoot the process on other platforms.
- and giving server or node details where jobs are running will help dig our root causes.
Sample Code location:
GitHub - Shivakoreddi/ETL-Log-Structure
Thank you for reading this post, future work will involve other challenges while developing python ETL jobs like Orchestration, Code management, version control, etc.
Reference:
- Elliot Forbes, https://tutorialedge.net/python/python-logging-best-practices/ (2017)
What to Log? From Python ETL Pipelines! was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3oGdrq3
via RiYo Analytics








No comments