https://ift.tt/3r80usc Results from training a GPT2 model on chess notation Image: www.pexels.com In a previous article (Chess2Vec), I...
Results from training a GPT2 model on chess notation

In a previous article (Chess2Vec), I analyzed which moves in a game of chess are close, in the sense that they often occur in similar situations in games. If two or more moves follow or precede one another, they are considered to be related in some way. The source for my analyses were files of games played on the internet chess server Lichess.
In this article, I would like to go a step further and investigate whether it is possible to learn the rules of chess only from recorded games in the form of text files? For this purpose, I use machine learning models that are actually designed for the analysis of natural language — Language Models.
Are Language Models suitable for Chess?
Natural language processing is applied for a variety of purposes that are not, or not directly, linked to NLP tasks, and data is processed in forms other than text. Computer vision, for example, and protein fold prediction are examples of processes that utilize natural language processing principles.
We investigate state-of-the-art language modeling techniques in a domain that at first appears to be outside their scope, computer chess. Because the rules are explicit rather than vague or ambiguous, this is because clear rules govern what happens here, not because there are many different ways for people to interpret language.
The GPT3 paper, for example, showed that by training a language model with the data of crawled websites, one may develop arithmetic abilities to some extent. In the process, simple operations were learned in a given number space but not beyond. Is this a result of the model’s lack of capacity, insufficient training time, or simply insufficient data?
We utilize the popularly concerned field of “computer chess” as an example to evaluate language models’ learning abilities and the impact of model size, training time, and accessible training data.
Because chess games were recorded on the growing internet chess servers, the testing area is ideal for studying language model training. Another advantage is that the language model’s quality may be tested not just using typical evaluation metrics for language models, such as perplexity, but also by testing whether good games are produced according to chess rules.
For decades, chess has been a popular AI testing ground, and it’s been especially hot in the past few years thanks to Deepmind’s efforts. There, a chess engine was created that surpassed everything that had previously existed in terms of playing strength by utilizing only the rules with fresh reinforcement learning methods (“AlphaZero “).
As a follow-up to the previous study, rules knowledge is no longer required. The new algorithm MuZero exceeded AlphaZero’s superhuman performance in the prior study without knowing the rules of the game.
To construct a system that could discover the chess rules from scratch, I started with a completely different methodology. Only game transcripts were used to train language models. We’ll then go over the models to see how the system has learned chess’s rules.
Data and Pre-Processing
We’ll need a lot of game data to teach the language model. We might get these from the internet chess server Lichess, for example. All games hosted on the server since 2013 are arranged by month in a single list. Each month’s compressed PGN file is available. Overall, there are over 400 GB of compressed data, with more than 1.7 billion games played.
Although the amount of data will be reduced significantly after pre-processing (e.g. removing metadata), it is still quite large at this point. We have plenty of room to experiment with different quantities of data during training, given that the original GPT2 language model was trained on 40GB of internet text.
The game’s quality plays a minor role in this study since it is concerned with simply learning the rules. However, the impact of the ELO ratings of players on their playing strength may be evaluated by filtering games based on their metadata. However, in order to avoid games that were abandoned early on due to a lack of play activity on the server, we will utilize a minimal length for filtering. A command-line program called “pgnextract” converts the PGN files to a format that PCs can read, and then processes them with chess engine software. This program handles almost all of the required operations by pre-processing the batch of data using a command-line application for manipulating PGN files. pgnextract can perform the required transformations in a reasonable time even with large amounts of data.
All the move numbers, results, comments, variations, and other information from the games are deleted in these cleansings to reveal only the pure string with the SAN notation. Every game is recorded to a file in one line. All games with less than 20 moves are excluded.
Training of the Models
The training was conducted on a Kubernetes cluster with NVIDIA RTX 3090 GPUs, each of which had 24 GB of video RAM and 256 GB of main memory. For the implementation, the Transformers package from HuggingFace based on Pytorch was used.
Under the same conditions, if a sequence of words is generated by language models, it will repeat itself unless the most likely word is chosen next time. Furthermore, the models frequently repeat phrases. This also affects the production of chess games here. As a result, random processes such as top-k sampling and top-p sampling are utilized to generate the games. These methods help to minimize repetition, although it can still occur.
Evaluation of the Models
To examine the models, various methods are used to produce games:
- From a list of typical opening positions after two moves.
- From positions of games from a game data set after a given number of moves.
- From randomly-generated positions after a given number of moves
For each of these games, the total number of correct moves generated is tracked. The language model will have to tackle three chess-specific metrics for assessing the generated moves. It is easiest to develop legal moves for the first evaluation criterion since all test situations were present in a big number of the training data games, thus it is enough for the model to remember the data. A generalization in the form that rules of chess were actually learned is only required for extremely lengthy generated move sequences.
The second approach is more difficult as the length of the given number of moves increases. Because the game data set used in the study is not included in the training data, as the length of the provided sequences grows, increasingly more positions will appear that have never been seen by the model. As a result, the model has to learn the rules in order to generate legitimate moves.
The third measure entails starting positions produced by a random sequence of chess moves. Because of this high degree of unpredictability, most of these steps have never previously appeared in human games or the test data set. It is therefore very difficult for the model to generate regular moves for these sequences. Even for humans, handling such random positions is very difficult. In experiments with chess grandmasters and amateurs it was found that while good chess players can easily remember typical positions, they have problems with random positions.
Results
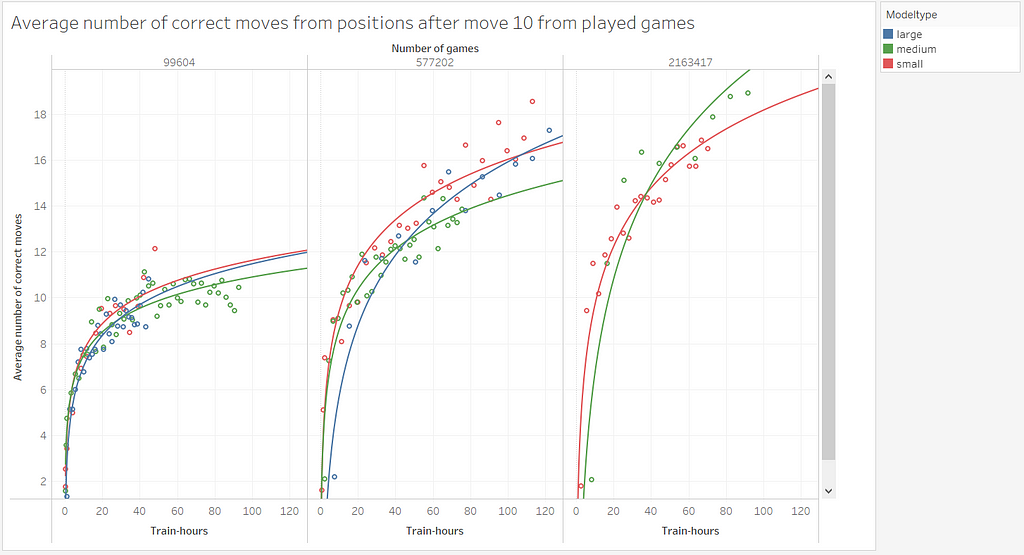
To see how the two variables affected the learning process, we trained different model sizes of GPT2 (small, medium, and large) with various numbers of games (99,604; 577,202; 2,163,417 games). The models were each subjected to an evaluation after a few epochs, using the evaluation metrics described in the previous section, to evaluate the outcomes.
With these statistics, we see that when more games in the researched range are utilized for training, better results can be obtained with the same amount of time. However, model complexity does not have this strong an impact. It’s also worth noting that the typical evaluation metrics for language models, predictive accuracy and perplexity, provide no information about this here.
How Is Chess Knowledge Stored in the Model?
We’ve seen how having more parameters in the model and more training data helps language models learn chess rules better. Now we’ll look for any patterns in how the chess rules’ information is represented in the model’s parameters. We will use different visualizations for this purpose.
When properly visualized and studied, neuron activations can reveal the roles played by individual neurons and groups of neurons. We use the Ecco library for analysis.
Let’s take a look at the inner workings of a trained model for moves from various sample situations. The first position is from the opening phase, and it’s a one-time occurrence when only one legal option exists.

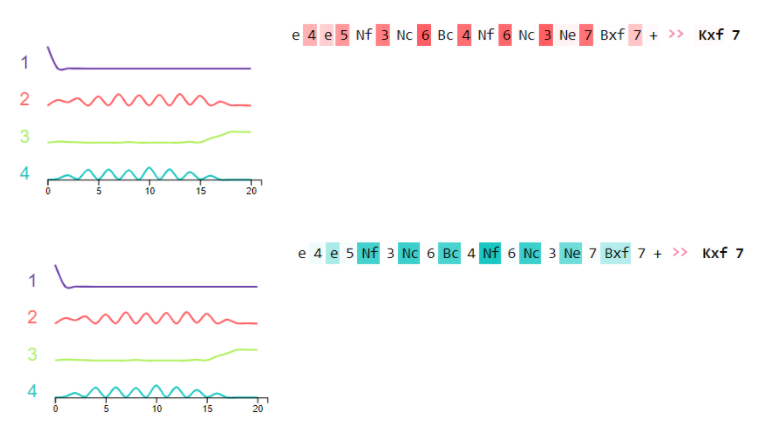
If we look at the influence of the individual parts of the sequence on the new move, we see that the last parts have the strongest influence, but otherwise, the entire sequence also influences the output.

The color code shows the strength of the influence, and alternatively, we can also show the influence of the individual parts as a percentage.
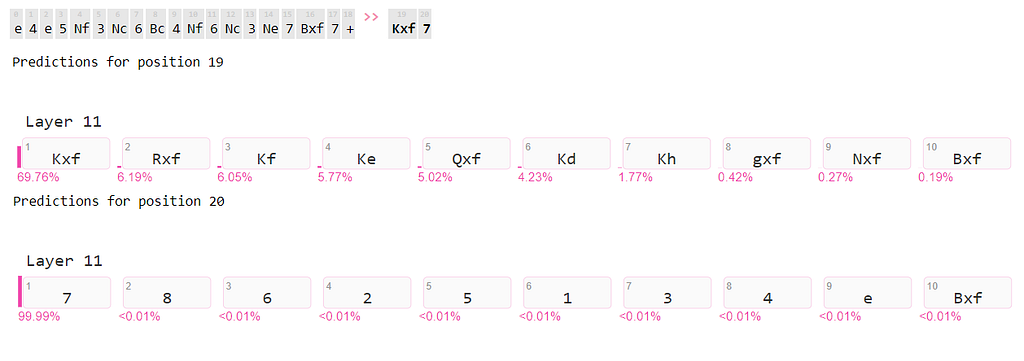
How certain is the model that the generated move is a correct one?
At the end of the last layer of the generator component, we evaluate the model’s chances for each possible token. The move is produced in two phases, and both parts have a high probability of being created, however, only one part has a 100 percent likelihood.
Let’s take a look at the neurons’ activations to see how the model keeps track of the chessboard based on move sequences. In order to generate admissible moves, the language model needs a representation of the chessboard and its pieces.
By examining the activation of groups of neurons, we see that one group (red) is active on the chessboard’s row information and another (blue) on the chessboard’s column and piece information. The other two are activated at either end of the string.
Let us now look at another position, which comes from the so-called “Game of the Century”. In the complicated middle position with a large number of options, the model reaches its limits.
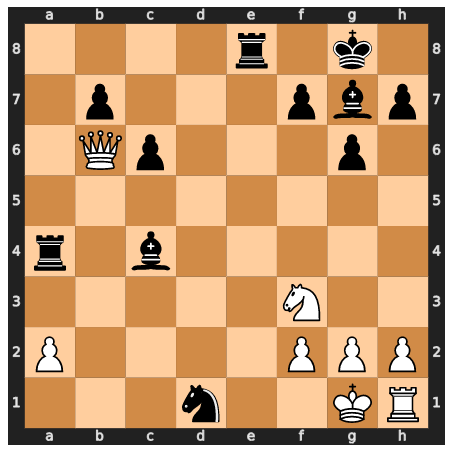
It recognizes that a piece on the d-file was captured last and wants to capture it back with Rxd or Qxd. However, there is no valid move for this in this position. The board was incorrectly represented in the neurons, so no viable moves are created.
Many potential next tokens are spread across multiple candidates in the network’s last layer.

In the second position, virtually the whole sequence of previous moves has an influence on the new move to be generated, as can be seen.

The specialization of groups of neurons on the row information and the figure and column information is obvious in this example. The activations, on the other hand, are less at the start of the sequence.

In the two example positions, it can be seen that the whole sequence has an influence on the generated move, which is necessary to generate correct moves. By looking at the activation of neurons, we could see that the information about the row, column, and type of figure is stored in different groups of neurons. Thus, the model seems to organize the storage of the information necessary to represent the state of the board.
The paper was published in the Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021). All the details can be found there.
Watching a Language Model Learning play Chess was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3HTxB8U
via RiYo Analytics








No comments