https://ift.tt/32kC6Jx To .apply or Not to .apply In this post we’ll show you how to speed up your pandas code for date related calculatio...
To .apply or Not to .apply
In this post we’ll show you how to speed up your pandas code for date related calculation by more than 10,000 times!
This post is in collaboration with Sam Mourad
pandas sucks
if you don’t use it correctly
it’s a million bucks
worth more than a Bentley
Intro
And we’re not talking about these pandas (adorable), but the python library we all data scientists out there use on a daily basis to do anything data-related.
Pandas look familiar to new users coming from many different backgrounds.
If you’re an Excel user, operations such as finding the sum or the cumulative sum of all columns in an array can be done in pandas by calling the DataFrame.sum or DataFrame.cumsum methods.
import pandas as pd
df = pd.DataFrame({"a": [1,2,3], "b": [4,5,6]})
print(df.sum())
print(df.cumsum())
If you’re a SQL user, operations like select or join statements can be done by calling the DataFrame.query or DataFrame.merge methods.
import pandas as pd
df = pd.DataFrame({"a": [1,2,3], "b": [4,5,6]})
bf = pd.DataFrame({"a": [6,5,4], "b": [3,2,1]})
print(df.query("a == 1"))
print(df.merge(bf, how="inner", left_on='a', right_on='b'))
If you’re an R, Stata, SAS, SPSS, or other statistical language user, operations like finding the correlation, standard deviation, or even an exponential weighted function can be done by calling the DataFrame.corr, DataFrame.std, or DataFrame.ewm methods.
import pandas as pd
df = pd.DataFrame({"a": [1,2,3], "b": [4,5,6]})
print(df.ewm(com=0.8))
Last but not least, matrix multiplication can be done by using the [DataFrame.dot](<https://ift.tt/3CAwhnx) method.
import pandas as pd
df = pd.DataFrame({"a": [1,2], "b": [3,4]})
bf = pd.DataFrame({"a": [5,6], "b": [7,8]})
print(df.dot(bf.T))
Or really any of NumPy’s universal functions a.k.a ufunc can be used by pandas to make use of vectorized operations as much as possible.
Though you’re on a roll and you want to use pandas for everything.
Such as date-time operations
A common operation is calculating the interval between 2 dates, let’s say in years. First, let’s create a simple function and some global variables:
import pandas as pd
from datetime import date, timedeltadef calc_age_function(start_date: date, end_date: date):
"""Calculate difference between 2 dates in years."""
return (end_date - start_date)/timedelta(days=365.25)
And now let’s define some example dates and calculate the age between them:
[In]:
start = date(
year=1930,
day=10,
month=5
)
end = date(
year=2020,
day=10,
month=8
)
print(calc_age_function(start, end))[Out]: 90.2532511978097
In practice though, it’s likely you have a list of more than one date that needs this operation done. Let’s create a series with the number of examples listed above to use for timing, as well as a DataFrame:
from datetime import datetime, timedelta
from random import randint, seedimport pandas as pdseed(42)
N_SAMPLES = 1_000_000
start_date_list = [
datetime.fromisoformat("2019-01-01") + timedelta(days=randint(0,365))
for _ in range(N_SAMPLES )
]
end_date_list = [
datetime.fromisoformat("2020-01-01") + timedelta(days=randint(0,365))
for _ in range(N_SAMPLES )
]
start_dates = pd.Series(start_date_list, name="start", dtype="datetime64[ns]")
end_dates = pd.Series(end_date_list, name="end", dtype="datetime64[ns]")age_df = pd.DataFrame(
{
"start_date":start_dates,
"end_date": end_dates
}
)
Now let’s calculate the age using our function on the columns in the DataFrame using apply with a lambda function (not best)
%%timeit
# slow, for loop apply
age_df["age"] = age_df.apply(
lambda x: calc_age_function(x["start_date"], x["end_date"]),
axis=1,
)20.6 s ± 63.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
As a python newbie, apply might be an easy thing to use. All you need to remember is an apply method and how to write a python function.
This works, though is not fast enough for us.
With pandas we can use arithmetic operations on Series objects which are significantly faster than for loops (usually what apply does, with exceptions which we’ll get to later).
What if we passed the series through our function instead?
%%timeit
# with date series, vectorized
ages = calc_age_function(start_dates, end_dates)10.3 ms ± 104 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Running the calculation directly on the series made this operation 2,000x faster!
But can we make it even faster?
In the code snippets above we’re using pandas date-time operations to get the number of days between two dates and divide it by a timedelta object representing the number of days in a year.
What if we try the same calculation using integer operations by representing the start and end dates as epoch integers rather than DateTime objects?
%%timeit
SECONDS_TO_YEARS = 60*60*24*365.25*1_000_000_000
(end_dates.astype(int) - start_dates.astype(int))/SECONDS_TO_YEARS2.22 ms ± 32.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Did that make our calculation 10,000x times faster than apply?
You bet it did!
Stress testing
Using sample sizes: 100, 1,000, 10,000, 100,000, 500,000, 1,000,000
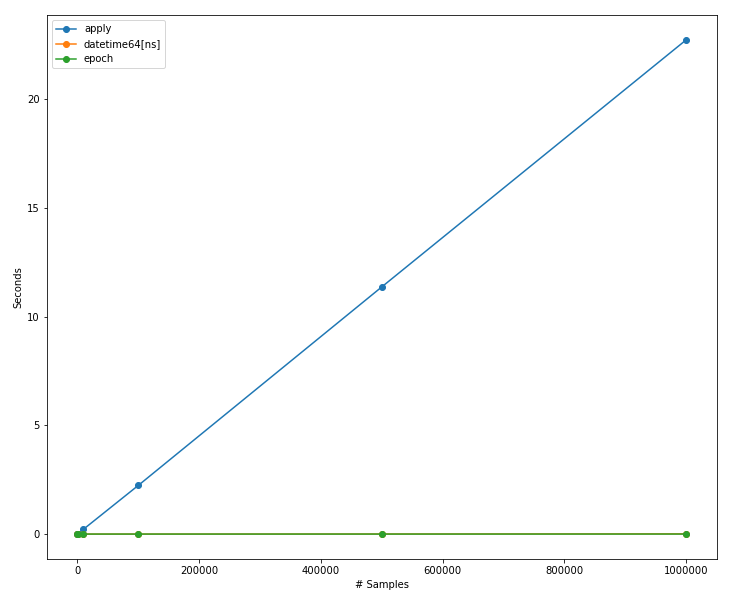
What is (and isn’t surprising) is how linear is the performance of the apply method relative to the data size, which appears to be O(n) in the graph above. Also, it’s on a much higher scale than the datetime64[ns] and epoch vectorized calculations. We can’t really compare the performance of all three calculations. Let’s zoom into the datetime64[ns] and epoch (vectorized) calculations here:
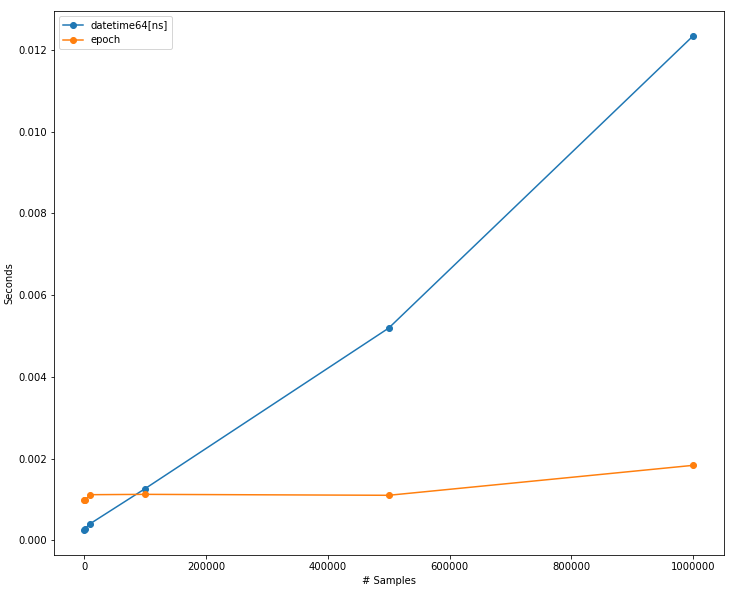
The Benefits of using epochs really kick in at 100k samples or so, as the datetime64[ns] performance is O(log n) while the epoch calculation is almost O(1).
Note on Series instantiation with DateTime dtype
%%timeit
# format series WITHOUT numpy dates
start_dates = pd.Series([start]*N_SAMPLES, name="start")
end_dates = pd.Series([end]*N_SAMPLES, name="end")1.59 s ± 6.91 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
With specifying Numpy datetime64:
%%timeit
# format series WITH numpy datetime
start_dates = pd.Series([start]*N_SAMPLES, name="start", dtype="datetime64[ns]")
end_dates = pd.Series([end]*N_SAMPLES, name="end", dtype="datetime64[ns]")1.73 s ± 4.04 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Difference of 140 ms, but these costs are especially worth it if you are going to be doing more than one operation with these columns.
You can also use pandas’ built-in to_datetime function if you prefer, with similar performance:
%%timeit
# format series WITH pandas datetime
start_dates = pd.to_datetime(pd.Series([start]*N_SAMPLES, name="start"))
end_dates = pd.to_datetime(pd.Series([end]*N_SAMPLES, name="end"))1.76 s ± 4.57 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Conclusion
- Running arithmetic operations on pandas series (or dataframes) makes use of vectorization when available in pandas, and is significantly faster than a row-wise apply of that same operation
- Using pandas native dtypes (in this case datetime64[ns]) could make your operations go significantly faster
- Arithmetic operations on epoch date-time are less expensive than DateTime objects
- This is true for the case of 1,000,000 data points. The gains do not scale linearly with the number of data points so don’t expect them to do so. The performance gains of pandas’ vectorized operations start at 10,000 points as pointed by Travis Oliphant in this podcast with Lex Friedman
- Pandas gains are not limited by its performance. The ease of use for data pipelines is a tremendous plus for using pandas. If performance is not highly important for your production processes, using pandas at any capacity would save you days or weeks of development of your data pipelines, analysis, or manipulation
What’s next
Look out for our next pandas’ blog post. We’ll be looking deeper into NumPy’s ufunc and analyzing Andrej Karpathy’s infamous tweet about NumPy’s sqrt function!
to .apply or not to .apply.. was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3kT1D2Q
via RiYo Analytics






ليست هناك تعليقات