https://ift.tt/3qhpwEV Building a decay function in SQL is not trivial, but fun. The best answer so far uses window functions, but can we d...
Building a decay function in SQL is not trivial, but fun. The best answer so far uses window functions, but can we do better with a JS UDTF in Snowflake? Find the results here
Brittany Bennett and Claire Carroll snipped data-twitter with a fun SQL puzzle. Hours later Benn Eifert had a great solution with SQL window functions. Then TJ Murphy tested it in Snowflake and explained why window functions are better than joins. And now, it’s my turn to play. Can I do better with a JavaScript UDTF? Find the results below.
— @teej_m
Why use a UDTF?
Let’s look first at the windowed pure SQL solution:
with t as (
select *
, row_number() over (
partition by name order by week desc
) as week_count
from decay_puzzle_10m
),
select *
, points_this_week * power(0.9, week_count - 1) as decayed_points
, sum(decayed_points) over (
partition by name order by week rows between unbounded preceding and current row
) as decayed_points_cumulative
, decayed_points_cumulative / power(0.9, week_count - 1) as score_this_week_calc
from t
;
Pros: It’s smart and pretty efficient.
Cons: It’s hard to understand, parse, modify and re-use.
Meanwhile a JS tabular UDF can do exactly what this problem needs:
- As a table UDF it will ingest a whole table and look at it row-by-row.
- As it can have memory of the rows it has seen before, it can accumulate data for the required decay math.
- As it allows partitioning, the memory of previous rows can be split for each segment.
- As each row is processed, it can output the correct results for each row.
A naive JS UDTF
This is the original Python logic that Claire & Brittany posted for the problem:
for n in range(number_of_weeks):
sum = 0
for i in range(n+1):
sum += points[i] * pow(0.9, n-i)
print(f"Score: {sum}")
Let’s translate it into a JS UDF:
create or replace function decay_udtf_v1(points float)
returns table (output_col float)
language javascript
as $$
{
processRow: function f(row, rowWriter, context){
this.pointarr.unshift(row.POINTS); // store history
sum = 0;
this.pointarr.forEach(function (item, index) {
sum += item * Math.pow(0.9, index);
})
rowWriter.writeRow({OUTPUT_COL: sum});
}
, initialize: function(argumentInfo, context) {
this.pointarr = [];
this.counter = 0;
}
}
$$;
This basically processes each row with processRow, storing the previous rows values into the array pointarr. It does a forEach to sum the decayed values and outputs that result.
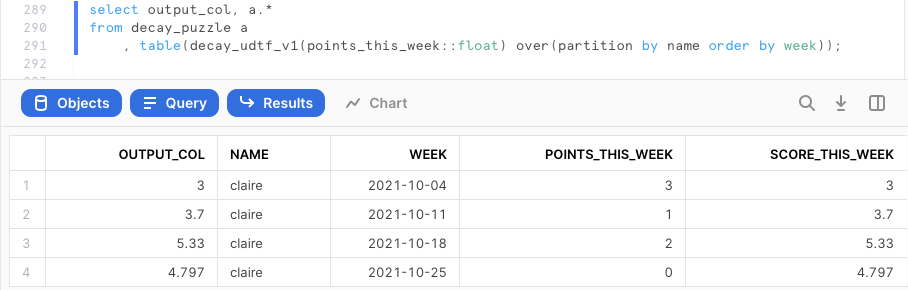
Using it is easy and clean:
select output_col, a.*
from decay_puzzle_10m a
, table(decay_udtf_v1(points_this_week::float) over(partition by name order by week));
But is this faster than the window function? Let’s test.
Benchmarking the naive JS UDTF vs Window Functions
First, let’s create a 10 million row table out of the 4 sample rows that Claire & Brittany gave us:
create table decay_puzzle as
select 'claire' as name, '2021-10-04'::date as week, 3 as points_this_week, 3.00 as score_this_week
union all select 'claire', '2021-10-11'::date, 1, 3.70
union all select 'claire', '2021-10-18'::date, 2, 5.33
union all select 'claire', '2021-10-25'::date, 0, 4.797
;
create or replace table decay_puzzle_10m as
select name || seq8() % 25000 name, week+seq8()%100 week, points_this_week, score_this_week
from decay_puzzle, table(generator(rowcount => 100000)) g1, table(generator(rowcount => 25)) g2
;
This creates 10 million rows with 25,000 different names, with 400 weeks for each name. The dates need some cleaning, but that’s irrelevant for our purposes.
Now it’s time to benchmark our 10 million rows sample, pitting the window function solution agains the JS UDTF naive solution within an XL warehouse. And the winner is…
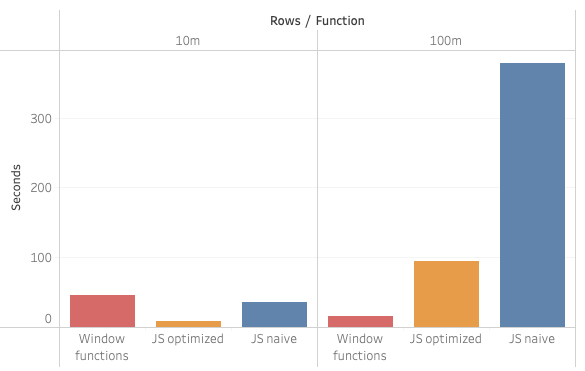
- Window function: 46s
- JS naive UDTF: 36s
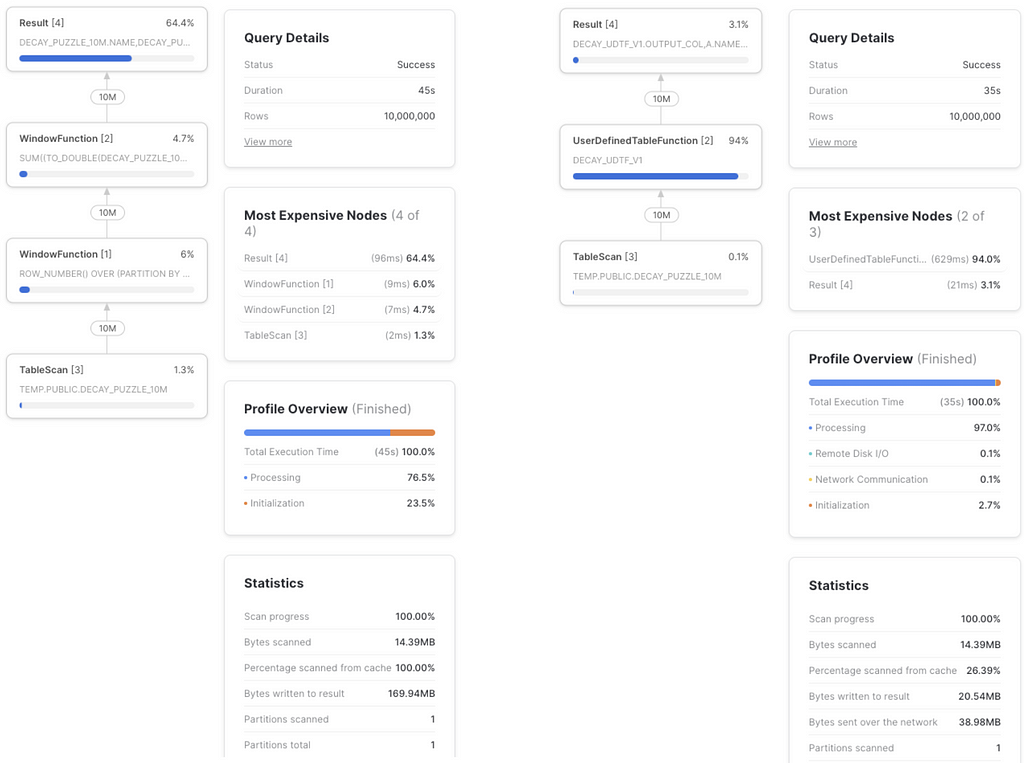
We have a winner! But that’s not all. You might have noticed that I keep calling that UDTF ‘naive’. Turns out that if we optimize the JS within it, the results get even better:
- Window function: 46s
- JS naive UDTF: 36s
- JS optimized UDTF: 9s
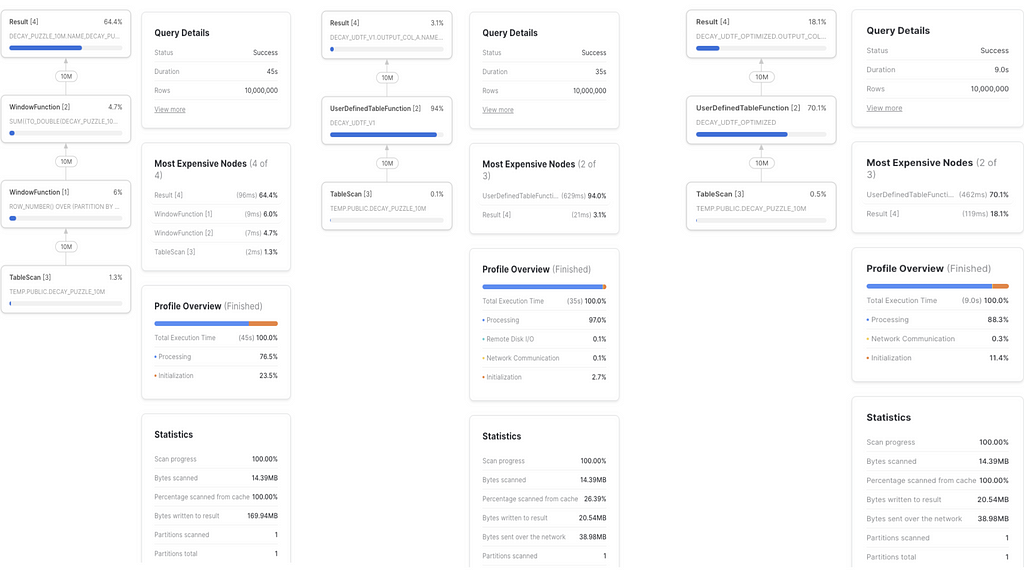
Optimizing the JS code was a huge win — turns out our original code was pretty inefficient. I’ll share the code for it later here, but first I’d like to see something even more interesting: What happens when we go from 10M rows to 100M rows?
Benchmarking the naive JS UDTF vs Window Functions with 100M rows
To generate 100M rows we can use similar SQL:
create or replace table decay_puzzle_100m
as
select name || seq8() % 25000 name, week+seq8()%100 week, points_this_week, score_this_week
from decay_puzzle, table(generator(rowcount => 1000000)) g1, table(generator(rowcount => 25)) g2
;
That’s still 25,000 different names, but now with 4,000 weeks each (instead of 400).
If we try our 3 solutions again, the results are surprising:
- Window function: 16s
- JS naive: 378s
- JS optimized: 95s
That’s interesting! With 10x the number of observations per name, time in the JS solutions went 10x too. But the SQL window function got faster! This is 10x rows in 1/3 of the time.
What we are witnessing here is the power of parallelization, and the assumptions that the SQL optimizer makes as it decides a path depending on the size of the input and available resources.
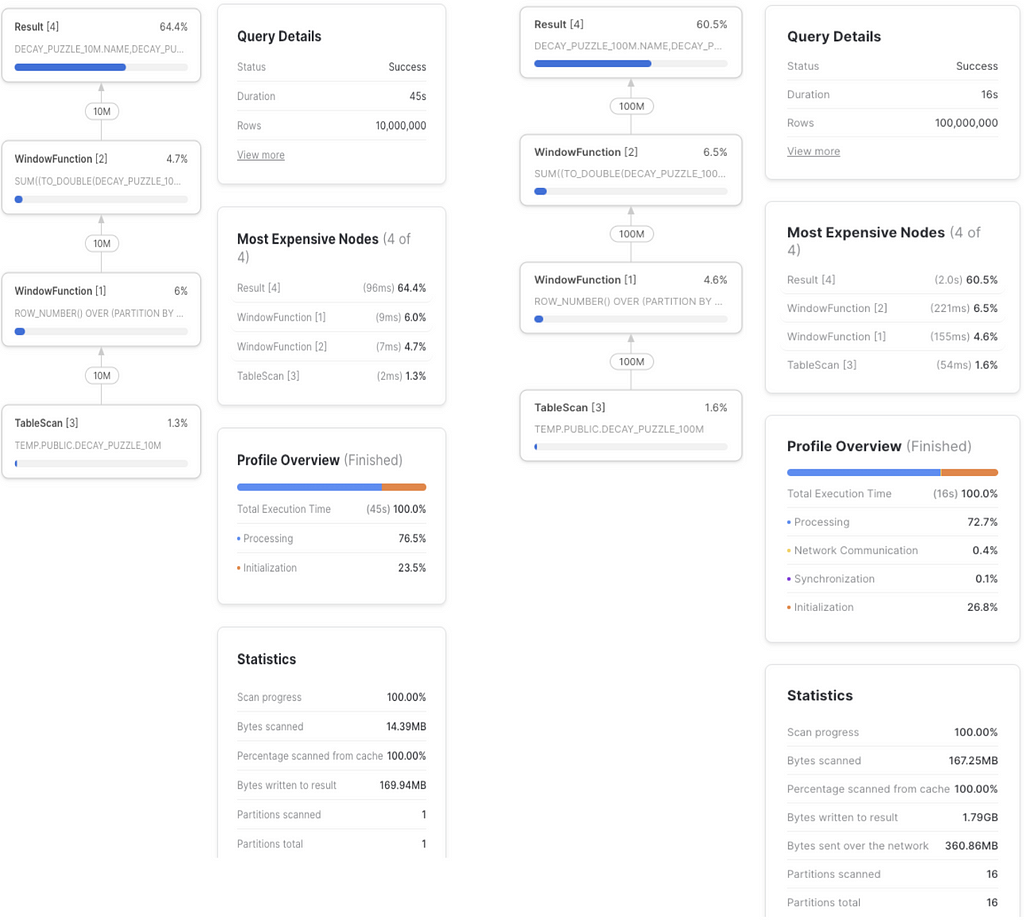
The optimized JS UDTF code
Let’s go back to the JS code and why it can be optimized to run in 1/4th of the time:
- Array.push() requires growing the memory assigned to an array. If we know the size of the input, we can pre-assign a block of contiguous memory.
- reduce() seems to run faster than foreach()
- power(0.9, week_count — 1) runs too many times, we can pre-compute it — especially if we know the size of the input. If we don’t, we could do some lazy evaluation anyways.
Optimized JS UDTF:
create or replace function decay_udtf_optimized(points float)
returns table (output_col float)
language javascript
as $$
{
processRow: function f(row, rowWriter, context){
this.pointarr[this.counter]=row.POINTS;
reduce_func = function(prev, curr, idx, arr) {
return prev + curr * this.precalc[this.counter - idx];
};
sum = this.pointarr.reduce(
reduce_func.bind({precalc: this.precalc, counter: this.counter}), 0
);
rowWriter.writeRow({OUTPUT_COL: sum});
this.counter++;
}
, initialize: function(argumentInfo, context) {
var preoptimized = 4000 // testing for 400|4000
this.pointarr = Array(preoptimized);
this.precalc = Array(preoptimized);
this.precalc[0]=1;
for (let i = 1; i < preoptimized; i++) {
this.precalc[i] = this.precalc[i-1]*0.9;
}
this.counter = 0;
}
}
$$;
Additional note: If we get rid of the multiplication, replacing prev + curr * this.precalc[this.counter — idx] with just a prev + curr, then processing 100M rows goes down from 95s to 75s. That’s not what we want to calculate, but it shows how much time can be shaved by optimizing the math inside our JS.
What did we learn
- UDTFs are a natural way to implement logic like the one required in the puzzle posed Claire & Brittany
- This UDTF is not only more elegant to use, it was also faster than pure SQL when benchmarking with 10M rows.
- Optimizing math inside a JS UDF can bring massive performance improvements.
- SQL window functions are cool and optimized natively by the SQL optimizer.
- Scalability works in weird ways: Sometimes adding 10x the data makes the whole thing take 3 times less time.
Next steps
- Would a Java UDTF perform better? A lot is happening in Snowflake, including UDFs. Stay tuned.
The most popular languages on Reddit, analyzed with Snowflake and a Java UDTF
- Check the real use cases for a decay scoring function, as seen in the Orbit model.

Want more?
- Try this out with a Snowflake free trial account — you only need an email address to get started.
I’m Felipe Hoffa, Data Cloud Advocate for Snowflake. Thanks for joining me on this adventure. You can follow me on Twitter and LinkedIn. Check reddit.com/r/snowflake for the most interesting Snowflake news.
SQL Puzzle Optimization: The UDTF Approach for a Decay Function was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3o0iOQF
via RiYo Analytics

No comments