https://ift.tt/30aBEwp Learn how to setup a shared external Hive metastore to be used across multiple Databricks workspaces and Synapse Spa...
Learn how to setup a shared external Hive metastore to be used across multiple Databricks workspaces and Synapse Spark Pools (preview)
1 Background
To help structure your data in a data lake you can register and share your data as tables in a Hive metastore. A Hive metastore is a database that holds metadata about our data, such as the paths to the data in the data lake and the format of the data (parquet, delta, CSV, etc).
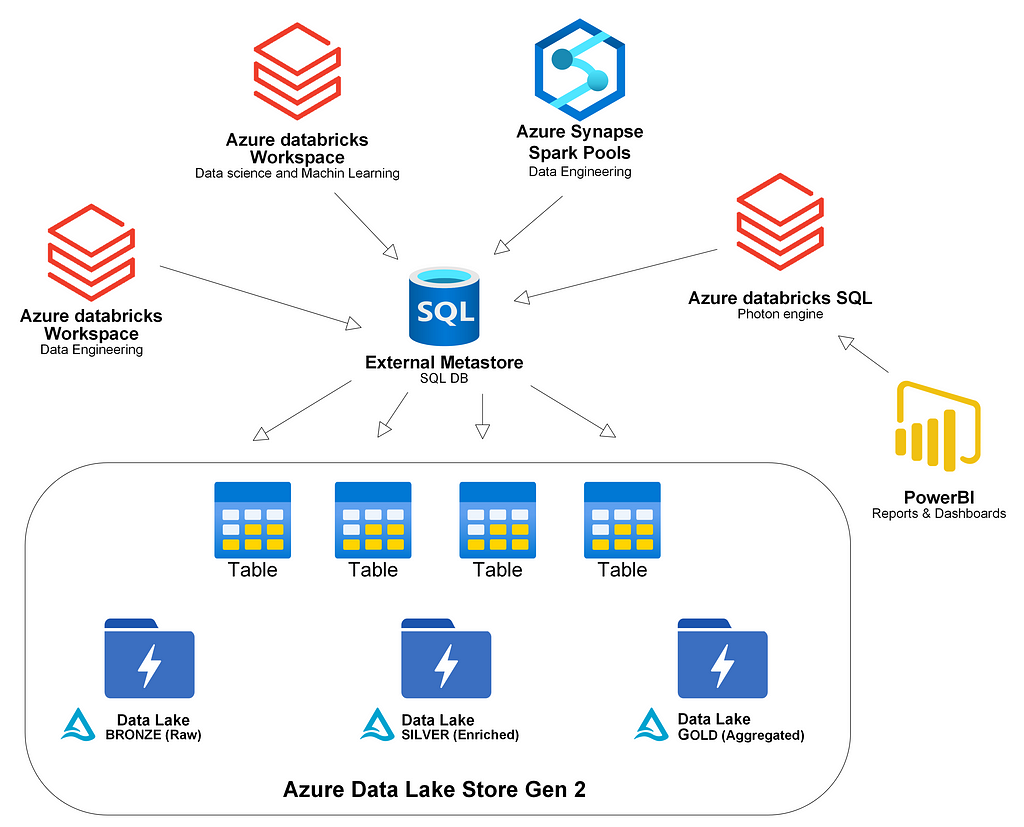
Every workspace in Azure Databricks comes with a managed built-in metastore. After a while, you have new teams or projects that create multiple Databricks workspaces that start to register their tables. Other spark users might use Synapse Spark Pools. Then you realize that you would like to share tables from different workspaces but each metastore is separated and accessible only from within each workspace.
You also might want to use the metastore to share tables across the business combining Databricks SQL with the metastore to serve BI users.
A solution is to create a shared metastore so that different workspaces can register their data into a commonly shared metastore.
2 Shared external metastore
We want to create a shared external metastore. A good start is often to look at the docs: External Apache Hive metastore — Azure Databricks | Microsoft Docs
The documentation has a lot of information. You will have to choose:
- A Hive metastore version
- A database for the metastore
We need the right combination of Databricks runtime, the database to hold our metadata for the external metastore, and the Hive version to make it work.
2.1 Databricks spark config settings and external metastore
Before we run into the details of matching Hive versions and back-end databases we look at how to tell the Databricks cluster which metastore to use. We provide our settings in the spark config of the cluster:

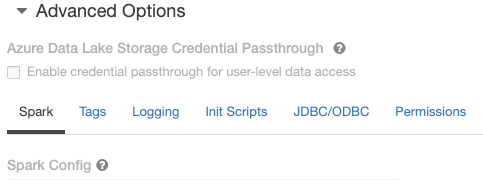
We need to provide:
- A version of the Hive schema to use
spark.sql.hive.metastore.version X.Y.Z
- A driver and a URI for the database that is our back-end for our metastore. The example below uses the “org.mariadb.jdbc.Driver” for MySql.
javax.jdo.option.ConnectionDriverName org.mariadb.jdbc.Driver
javax.jdo.option.ConnectionURL jdbc:mysql://mysqlserveruri.mysql.database.azure.com:3306/myextmetadb013?useSSL=true&requireSSL=false
- Credentials to connect to the database
javax.jdo.option.ConnectionPassword
javax.jdo.option.ConnectionUserName
Note that we use placeholders for the credentials that are stored in Azure KeyVault. You can reference secrets in the Azure KeyVault directly in the spark config. The syntax is:
Where scope is the scope name you registered and secretname is the name of the secret in Azure KeyVault. If you have forgotten or have not registered a scope with a key vault you can look here: https://docs.microsoft.com/en-us/azure/databricks/security/secrets/secret-scopes to learn how.
If you have forgotten the scope name and the secrets you can always use dbutils to take a look:
dbutils.secrets.listScopes()
dbutils.secrets.list(scope="myscopename")
Make sure you create Hive schema for Hive version less than 2 (first time):
datanucleus.autoCreateSchema true
datanucleus.schema.autoCreateTables true
Note: Auto creation of schema does not work for Hive version 2 and upwards
- Any jars that we need (not needed for 0.13)
- Some other optional settings not to validate schema (first time) as we create the schema and can’t validate it.
datanucleus.fixedDatastore false
hive.metastore.schema.verification.record.version false hive.metastore.schema.verification false
When you have created your schema for the metastore you can set back the property:
datanucleus.fixedDatastore true
which prevents any accidental structural changes to the metastore databases.
2.2 Selecting Hive version and learnings
Depending on the Hive version you chose Hive will behave differently. Some difference are:
- Not all databases are supported as a back-end
- Hive can/cannot create the schema by itself.
- Some bug fixes and features. See all releases and the change logs here: Downloads (apache.org)
Learnings with Hive 0.13
I first tried to use Hive 0.13 (the default built-in version in the workspace). Using 0.13 has some benefits. Version 0.13 can generate the schema for the metastore by setting the property “datanucleus.autoCreateSchema true”. Also, the jars needed are provided by databricks.
Don’ t use Hive 0.13 with Azure SQL DB. In my tests, this combination did not work due to a bug in Datanucleus when dropping tables registered in the metastore. Although the documentation said it should work, it did not.
Azure MySql DB 5.7 works fine with Hive 0.13, but make sure that you set the server parameter change lower_case_table_names to 2. Do this before you create the database and the tables for the metastore.
This can be done in the Azure Portal:
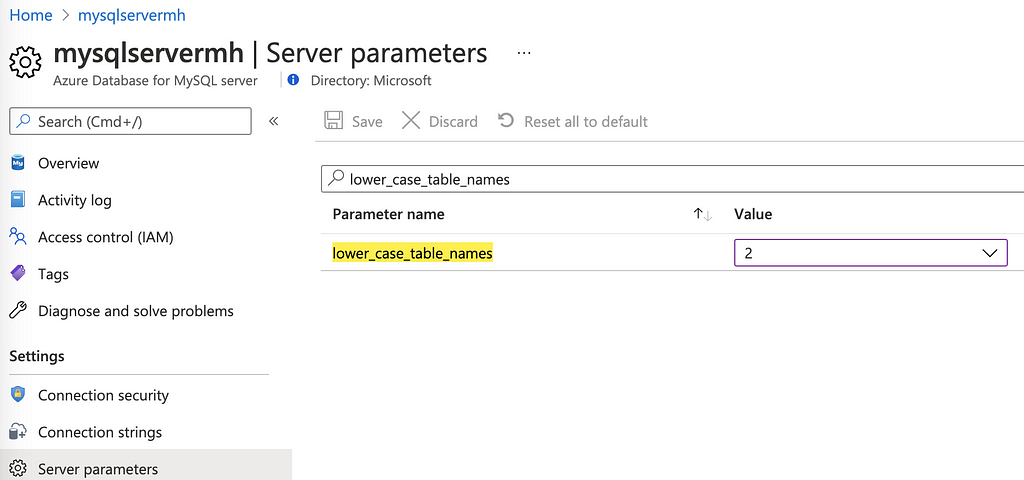
Then create a database in MySql Server. We need to create the database before connecting Databricks to the database with the JDBC connection string.
Login to MySQL Server using your preferred tool and create a database for the metastore with your chosen name. Example:
CREATE DATABASE extmetadb013;
Add the following to the Spark Config for the Databricks Cluster you want to use, replacing:
xxxscope, xxxsecretname, xxxserverurl, xxxdatabasename, xxxuser
with your DB URL and credentials:
spark.sql.hive.metastore.version 0.13
javax.jdo.option.ConnectionDriverName org.mariadb.jdbc.Driver
javax.jdo.option.ConnectionURL jdbc:mysql://xxxserverurl.mysql.database.azure.com:3306/xxxdatabasename?useSSL=true&requireSSL=false
javax.jdo.option.ConnectionUserName xxxuser
javax.jdo.option.ConnectionPassword
datanucleus.fixedDatastore false
hive.metastore.schema.verification false
datanucleus.schema.autoCreateTables truehive.metastore.schema.verification.record.version false
datanucleus.autoCreateSchema true
Restart the Cluster in Databricks to create the tables in the metastore store DB.
After this, you should be able to see your new database and the schema created.
Learnings with Hive 2.3.7
Hive 2.3.7 works with Azure SQL DB as the back-end.
Synapse
If you want to share the same external metastore between Databricks and Synapse Spark Pools you can use Hive version 2.3.7 that is supported by both Databricks and Synapse Spark. You link the metastore DB under the manage tab and then set one spark property:
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name HIVEMetaStoreLinkedName
Note that this is still in preview (and a bit unstable in my tests) so not for production workloads yet. See: Use external Hive Metastore for Synapse Spark Pool (Preview) for a step by step guide.
Databricks
Hive version 2.3.7 requires you to set a property in spark.config in Databricks to tell spark what jars to use:
spark.sql.hive.metastore.jars builtin
The jars are provided/built-in so you don’t have to download the jars yourself. Note: For Hive 1.x and 3.x you will have to provide a folder with the jars or you can use Maven to download the jars on cluster startup, but the downloading of the jars takes quite some time so it will improve startup time if you download the jars once before.
Creating metastore tables manually
Hive version 2.3.7 (version 2.x and up) will not create the metastore tables for you and the documentation does not clearly tell you how to create the tables. I tried two ways that worked:
- Using the Hive schematool
- Using a Hive SQL script
Create metastore tables using Hive schematool
To use the Hive schematool binary (/apache-hive-2.3.9-bin/bin/schematool) you need to download Hive and, download and have Hadoop Core on PATH and set the connection properties in the hive-site.xml (you can use proto-hive-site.xml as template). Then run the schematool which will connect to your database and create the tables. I will not go into the details here even if it did work. I suggest using a SQL script described below instead.
Create metastore tables using Hive SQL script
There is an easier way to create the tables/schema for a specific Hive version. You can download and run a SQL script.
Download and extract the latest 2.3.x HIVE release from here: https://hive.apache.org/downloads.html
You will see a folder containing the scripts for different Hive versions and different databases:

If we select e.g. mssql folder (if we use that database otherwise select your database) we will find the scripts for different schema versions:

In our case, we will run Hive 2.3.7 and we want to create the schema version 2.3.0. Run or paste the script in your favorite SQL editor:
hive-schema-2.3.0.mssql.sql
to create the tables.
We need to set the spark config for the cluster to use Hive 2.3.7 and our Azure SqlDB:
Replace: XXXDNSXXX, XXXDATABASEXXX, XXXUSERXXX and XXXPASSORDXXX with your values, preferably using Azure KeyVault as explained above to avoid clear text secrets, in the Spark config.
spark.sql.hive.metastore.jars builtin
javax.jdo.option.ConnectionURL jdbc:sqlserver://XXXDNSXXX.database.windows.net:1433;database=XXXDATABASEXXX;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;
javax.jdo.option.ConnectionUserName XXXUSERXXX
javax.jdo.option.ConnectionPassword XXXPASSORDXXX
javax.jdo.option.ConnectionDriverName com.microsoft.sqlserver.jdbc.SQLServerDriver
hive.metastore.schema.verification.record.version true
hive.metastore.schema.verification true
spark.sql.hive.metastore.version 2.3.7
If you want you can move the spark config settings for your metastore into a shared init script so it can be used by many clusters.
3 Access to Data with a shared metastore
Now we have a shared metastore that we can use to go from a table name to read data in the data lake.
Using the metastore to query a table in Databricks:
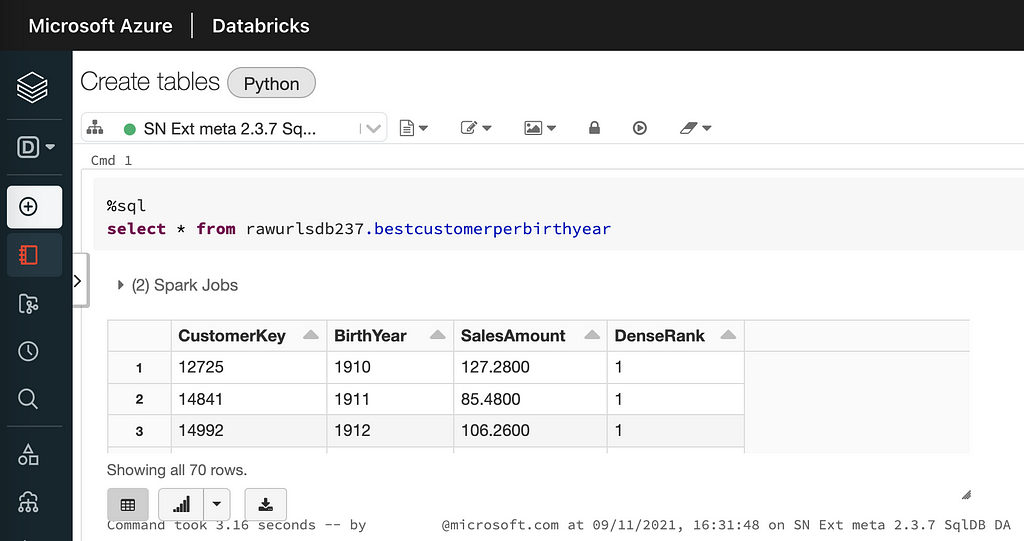
Using the same metastore to query the same table in a Synapse Spark Pool:
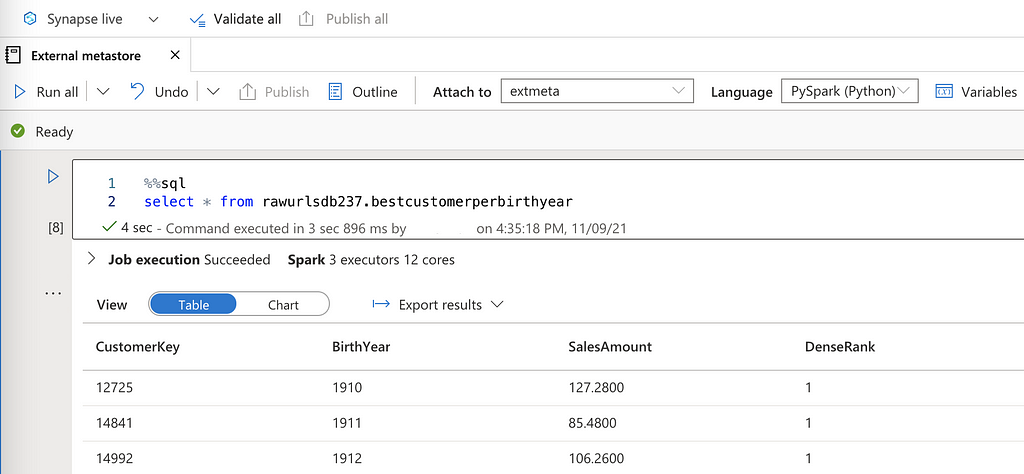
This requires that the different workspaces and the clusters have read access to the data. When working with a shared metastore we should use direct access to the data lake i.e. not using mounts to access the data as mounts can differ from workspace to workspace. If we query info about a table registered in the metastore we can look at the location for the data behind the table (direct access URL):
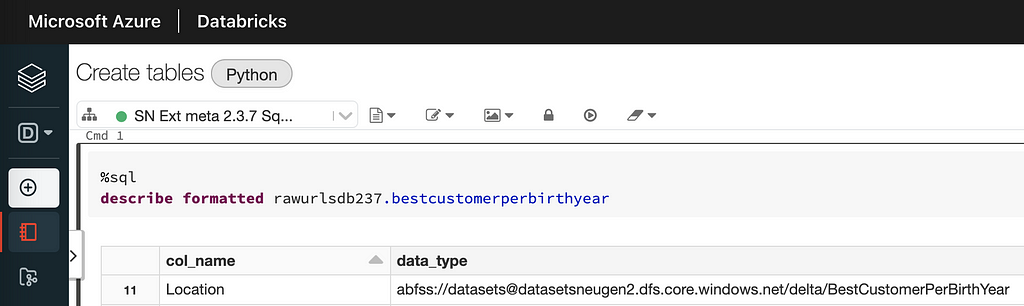
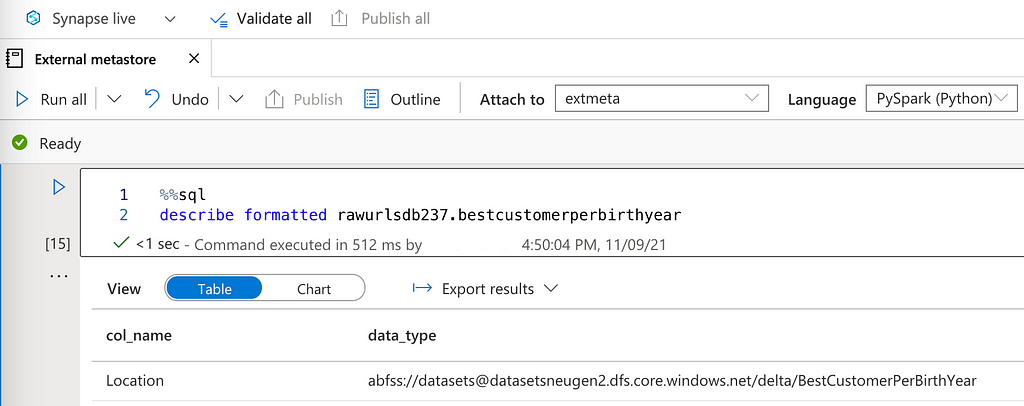
We can see that both Databricks and Synapse use the direct access URL registered in the metastore.
The location must be understood by all readers. If the location is the direct URL it will work across all technologies used to read the data (as long as the reader has access). Mounting folders in the data lake will not work as that will put a requirement on the reader to have the exact same mount points across workspaces. Also, other tools, like Synapse Spark Pools, that might want to use the metastore might not be able to mount data.
4 Always Create External tables
When creating tables in Databricks with:
df.write.saveAsTable("MyManagedTableName")
the default location is to store the data in the local DBFS folder under:
/dbfs/user/hive/warehouse/MyManagedTableName
in the Databricks workspace.
The DBFS belongs to the workspace and is not your data lake. Also, the general recommendation is to not write any sensitive data at all to DBFS. We should make sure to only create tables that are external by giving the location of the data when creating tables. We should use the direct URL to the data of the table and not and mounted path. A simple example can be seen below giving the location of the data when creating a table on top of existing data (in delta format) in the data lake:

We have to tell the format of the data (delta in the example above) and point to the folder where the data is located in the lake to create our table on top of the already existing data.
If you want more info about managed and unmanaged tables there is another article here: 3 Ways To Create Tables With Apache Spark | by AnBento | Towards Data Science that goes through different options. Also, the official documentation is here: Databases and tables — Azure Databricks | Microsoft Docs.
5 Giving the cluster direct access to data
You might have noticed that we have not talked about how we can give direct access to the data we need in the data lake. This can be done in the spark config using Azure KeyVault to store the secrets. How to access the Data Lake using keys or service principals is another story, but here are links to the documentation:
Access Azure Data Lake Storage Gen2 using OAuth 2.0 with an Azure service principal
and specifically, you don’t want to mount, but to use direct access:
Access ADLS Gen2 directly
In a synapse workspace you can link a storage account under the manage tab by adding a storage account as a linked service, using keys, service principal, managed identity or user assigned managed identity (preview).
6 What’s next
As always there is much more to cover but in this post, I wanted to share some learnings when it comes to setting up a shared external metastore, to be used in e.g. Azure Databricks and in Synapse Spark Pools. I hope that you got some new insights with you on your way to your next external metastore.
Shared External Hive Metastore with Azure Databricks and Synapse Spark Pools was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3BXEiCJ
via RiYo Analytics






ليست هناك تعليقات