https://ift.tt/3G4B4Qa 3 lean validations to make sure you’re on the right path Photo by Pixabay from Pexels What makes AI applicatio...
3 lean validations to make sure you’re on the right path

What makes AI applications special
One of the main differences between AI and general developments is the required evaluation scope. On regular apps by knowing what to do and how, validating the need and keeping it simple, you’re almost safe. But on AI apps you can have the best research, top developers and elite product team and still face failure. The reason is the higher uncertainty which rises in many dimensions. Back in 2015 Sculley et al discussed the uniqueness of ML apps by describing their implicit technical debt; while most people see ML code as their main ingredient, the truth is this is only a small friction of the development needed for AI applications. Using the AI success triangle of importance, feasibility and usability we can format a set of validations to make sure to avoid any hidden caveat in our path to success.
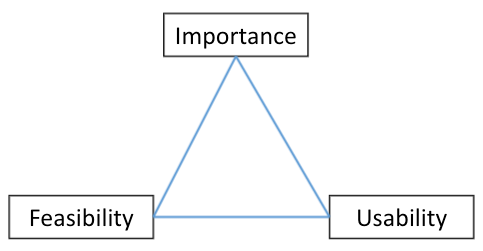
Assessing uncertainty using the success triangle
The AI success triangle helps to map the possible risks by highlighting key factors to look at; the first and immediate one is importance (making sure developments are with high value and are important to the business), next is feasibility (making sure the objective is achievable) and lastly is usability (making sure it can be well utilised). An intuitive example would be trying to guess the lottery numbers — predicting the next numbers is super important (win the first prize) with an easy utilisation (just submit these numbers) but quite not feasible (unless you’re a magician). Predicting the previous numbers is feasible (just search the web) but super hard to utilise (unless you can travel back in time). The evaluation is done at the 3 main phases of the app life cycle; before (ideation), during (development) and after (customers facing). Each has different risk factors but in general all can be mapped using the same success triangle. Successful AI apps must be ready to pivot fast; whether it’s since data is scarce, business changed their mind or the algorithm doesn’t seem to converge. We should constantly make sure we’re on the right path by asking the right questions at the right time. Details of what to verify, when and how are below.
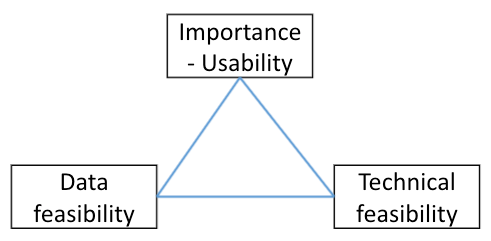
Before — app ideation phase
The initial phase is also the easiest to pivot at (no effort was spent) and therefore it is where most of the validations should be done. Let’s assume our task is to predict customers’ churn likelihood. The importance (money to be saved) is quite clear. For many companies this will be enough to start pursuing that topic. For us, looking at the success triangle, we should ask two more questions — ‘given customer in danger to churn — how will you prevent it?’ (usability) and as churn prediction apps mostly require a holistic data view ‘how easily accessible is the customers’ data and what will it take to make it such?’ (feasibility). The usability evaluation may uncover the fact that even if we manage to develop the app, not sure it will be able to achieve what we planned for. The feasibility evaluation may reveal an implicit higher cost. Considering these factors may convince us to pivot. And even if not, it will enable us to fix it from ahead (for some cases, making sure the app is more actionable will be enough). As this is the cheapest pivot point we should spend much time making sure the validations are set before taking the decision to continue to the next phase — starting to develop the app.
During — app development phase
Once we start developing the app pivot price increases with time (more work to be wasted). Therefore we should pre-identify key internal milestones and validation points. Looking at the success triangle, importance and usability were already verified on the ideation phase and therefore are less in risk. Feasibility is where we should spend most of our validation at — data and technical feasibility. Data can be infeasible due to many factors. We could for example find that an important historical data piece was not collected, that labeling is not available or that the data required for inference is only available at a later phase. There are also many technical issues that can affect the app feasibility. We could for example find that the paper we relied on doesn’t work in real life, that the resources it requires are too high, or that we included a python library which is not supported on edge devices. Many of these issues can be easy to solve as long as they are identified ahead of time. This is why setting internal validation points is so important. Moreover, for many cases once having a minimal MVP it makes sense to jump forward and re-verify the usability assumptions we had — how will it be served, does it fit the software ecosystem we have, etc. Asking these questions may require returning to the previous phase, to better define the need we’re trying to solve. Keep in mind that finding on early phases that an app is not compatible with edge usage is a different story than discovering it on the big release event. Failure in the sketch room is way more convenient than failure on the stage.
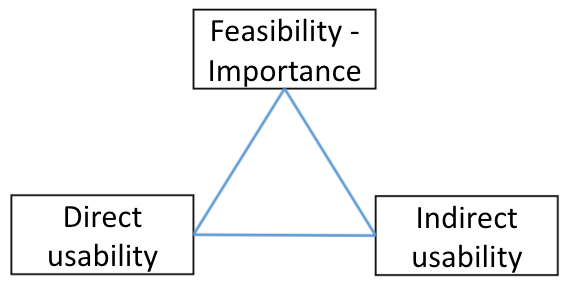
After — app in production phase
Once we start deploying our app to customers, the importance and feasibility are less troubling (as we manage to develop it), and the usability becomes the main obstacle to monitor. General pivot is less relevant (re-developing the app will be super expensive). More relevant are UX/ UI pivots; how to better engage customers, to sharpen the app value, etc. Usability can be divided into two main measures — direct and indirect. Back to the churn prediction example, direct usability measures the main value proposition (number of churned customers should decrease) and indirect usability measures side motivations (like general usage and utilisation). It is important to avoid the temptation to draw fast conclusions following bad direct measure feedback (number of churned customers is the same -> failure). For many cases success requires some users guidance and therefore deep analysis of the indirect measures is also vital. Let’s assume we decided to add a feedback section in order to better measure our churn prediction app. The issue is the wording we choose. Getting negative feedback while asking if the alert was useful can be due to being wrong but can also be due to being too late (which is way different feedback). A simple solution could be to add a free text area on the feedback form. We should not only monitor and collect feedback but do it in a way that will enable us to take actionable insights out of it. To make sure the decisions we take are based on real data.
Finally — keep it simple
It will sound like a mantra, but the most important task to remember is to keep it simple. Looking at fancy architectures, huge datasets and shiny new libraries, it can be too easy to rush into development only to find out later it was a mistake in the first place. Spending an extra minute on evaluations will save tons of minutes by avoiding later pivots.
Pivoting ML Apps to Success was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/317Hqjj
via RiYo Analytics








No comments