https://ift.tt/3HtEOfJ Machine Learning Model Deployment — A Simple Checklist Necessary things to check before, during, and after deployin...
Machine Learning Model Deployment — A Simple Checklist
Necessary things to check before, during, and after deploying your machine learning models to production
There are many things that can go wrong when moving your machine learning model from a research environment to a production environment. Data scientists/ML Engineers often underestimate how easy it is to break an ML model and make the results irreproducible
Intended Audience:
- Data scientists who want to make sure their code/model can be readily deployed without any circumstances that would make the model results irreproducible
- Machine Learning Engineers who want a quick list of things that could go wrong when moving a model between environments/platforms
These checks are better done in sequence to confirm issue from the previous scenario doesn’t carry over to the next step
Keyword to remember for convenience:
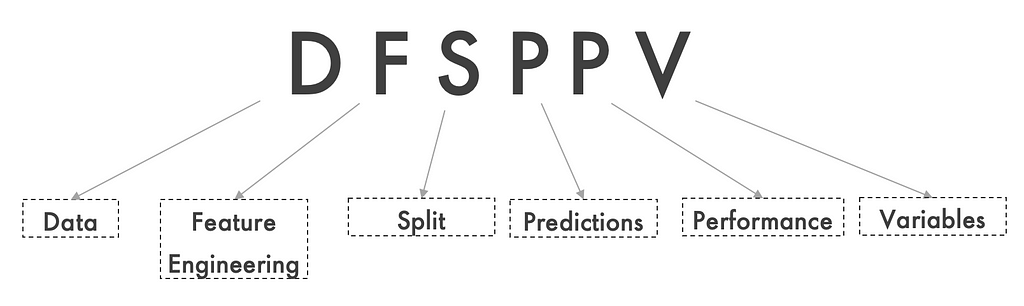
Scenario — 1:
Data irreproducibility
- Machine learning models work on data. If the underlying data is not the same as the research environment, it is impossible for the model to generate the same results
- You might think this is common sense. But practically, one of the underestimated issues often overlooked by data scientists and ML engineers (I’m guilty of it too) is small changes to underlying data and their impact on the hypothesis inferred by the model
- The underlying raw data coming into the system before pre-processing/engineering must match the research environment. No amount of feature engineering will compensate for incorrect/irreproducible raw data
- People who work on big data often find it convenient to say it is impossible to match such large volumes of data. It’d be impossible to match row by row. But a set of statistical measures must be set forth in order to make sensible comparisons
- The ETL process set to load data into an environment should be compared and each output of the process must be checked. Do not overlook precision and its impact when doing large aggregations
- Check for potential packet/data loss during the transfer of data to the environment
- If you have multiple data sources feeding data into the model, checks must be carried out on each of these
Scenario — 2:
Different outcomes of feature engineering steps
- Once you’ve validated that the raw data is reproducible, the next step would be to check reproducibility post feature engineering
- One of the common mistakes is not setting seed when using feature engineering involving sampling of data
- Check for pre-processing logic mismatches (handling of nulls, NANs, extreme values, etc.), aggregation mismatches, data precision
- Check for Python version and underlying library versions in both environments and if defaults in the libraries have changed
- Similar to the previous step, have statistical measures/KPIs to compare engineered/processed data between environments
Scenario — 3:
Different train-test split
- The horrors of irreproducible split know no bounds. The step just before loading data into any ML model, we split the data into training, validation, test datasets. It is necessary to make sure these datasets are reproducible within and across environments
- Most commonly, data scientists forget to set seed while making the splits
- If you are doing cross-validation, it is particularly important to set seed in case of RepeatedKFold, ShuffleSplit, GroupShuffleSplit
- If you’re using RDBMS, make sure the correct order of data is maintained and make sure a logic to sort or keep the ordering of data is set
Scenario — 4:
Prediction Mismatches
If the model generates NaNs or infinite as predictions:
- The environment data may contain null data not handled in the code
- Data (particularly testing or streaming data) may contain categories not observed previously
- Bad data while streaming/testing
These issues can be handled by covering these scenarios in code. Although SME input might be required on the data and handling
If model predictions don’t match or partially match:
- No seed set during research/production environment for the underlying algorithm or sampling
- Different Python or library versions could’ve modified how the algorithm processes the data
Scenario — 5:
Performance below expectation:
- As KPIs and expectations change rapidly in certain scenarios, it is likely that by the time your model is put into production, your model might not meet the expectations
- We should do checks to make sure the distribution between training and live predictions is not very different. Data and concept drifts can rapidly evolve over time for a few use cases
- In the case of supervised learning, we must also check if the target remains the true expectation of the outcome. If the target is unreliable or changes over time, the model performance will also deteriorate/become unreliable over time
Scenario — 6:
Variable unavailability or non-frequent features
- In a real-life scenario, variables get outdated and replaced quite often. We can either try to replace it with the most similar variable or remove the variable and retrain and re-evaluate the model performance
- Variables could also be non-frequent in nature. We should confirm that if a particular value doesn’t arrive for long period, it doesn’t drastically impact the inference made by the machine learning model
These are some of the most frequent scenarios practically observed and often overlooked by data scientists and machine learning engineers while developing and deploying models to production. Deploying and maintaining ML models are as hard (if not harder) than developing them. Hope this quick article helped you avoid common pitfalls in your workplace. Is there a scenario you feel must be covered? Please feel free to drop a comment. I’d be happy to learn from your experience.
Machine Learning Model Deployment — A Simplistic Checklist was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3Coz5nR
via RiYo Analytics







ليست هناك تعليقات