https://ift.tt/3mWoqMC How to use a complex network-based semi-supervised method to label your data Photo by Mika Baumeister on Unsplas...
How to use a complex network-based semi-supervised method to label your data

The amount of available data is growing quickly, which, on one hand, is excellent for Machine Learning models and practitioners since will allow for the development of novel solutions in the area. On the other hand, most of this data is not labeled and the labeling process is usually expensive and cumbersome [1].
Dealing with the fact that most of the Machine Learning solutions are restricted to the Supervised Learning paradigm, this poses a big problem: how to deal with that amount of unlabeled data?
To try to solve this problem, the semi-supervised paradigm was created. Its focus is on trying to work with a small set of labeled data and a large amount of unlabeled data to make predictions.
In this post, we will be looking at a semi-supervised learning tool: label propagation. We will learn about how we can use complex networks and the sknet library to propagate labels to our unlabeled data.
Modularity on Complex Networks
To propagate labels using complex networks, we must first understand what is the modularity measure and how it is related to community detection on networks.
A community is a region of the graph that is densely connected inside itself but sparsely connected with other regions of the network. Detecting such communities poses an unsupervised NP-Complete problem and can be seen as a clustering problem from the lens of traditional machine learning.
The modularity measure is a way of quantifying how good a network division is. It basically measures how much the found communities present this dense/sparse connections characteristic when compared with a random network with no community structure.
Using modularity, unsupervised algorithms were made for community detection. The algorithm that will be useful for us is the Modularity Greedy Algorithm.
Modularity Greedy Algorithm
This algorithm tries to find the community structure inside the network by first setting each node as a community itself then merging them up at each step.
The communities chosen to be merged are the ones with will generate the greater increment in modularity. Thus, as we are, for each step, choosing the merge that maximizes on that point, we are dealing with a greedy algorithm.
In order for this algorithm to be used, a matrix known as the modularity increment matrix is defined as follows:
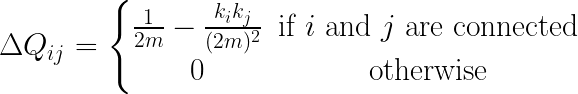
On this matrix, the Delta Qij denotes the increment for the modularity in case the communities i and j are merged.
The label propagation algorithm
The Modularity Label Propagator algorithm depends heavily on the Greedy Modularity algorithm above. The idea here is that we can use it to propagate the labels we have to the unlabeled data in a way that we are generating cohesive groups inside our network.
So, the basic idea behind the algorithm is as follows:
- We start with L labeled nodes in the network
- Each node of the network is defined as a community
- At each step, we merge the communities maximizing the modularity using the modularity increment matrix
- If the merge is not possible (we will see why soon), we go to the second-highest entry on the matrix, and so on
- We repeat until no node on the network is unlabeled
Pretty simple right? Now, let’s see why some merge may not be possible.
Given two nodes, we have four different possibilities related to their labels: both are already labeled but with different labels, both are unlabeled, one is unlabeled or both are labeled with the same label.
For the two first cases, we cannot merge because we are either changing some label, which we cannot do, or not propagating any label. In the latter two cases, the merge can happen since we are propagating a label or just joining a community from the same labels.
With this, is expected that we will end up with all of our instances labeled.
Using the label propagator with sknet
To implement this algorithm we will be using the sknet library which is focused on implementing Machine Learning algorithms in complex networks. To do so, let’s start by installing the library:
pip install scikit-net
Now with the library installed, let’s import the required libraries. Also, we are going to import the Iris dataset which we will use to propagate our labels:
from sklearn.datasets import load_iris
from sknet.network_construction import KNNConstructor
from sknet.semi_supervised import ModularityLabelPropagation
X, y = load_iris(return_X_y = True)
y[10:30] = np.nan
y[70:90] = np.nan
y[110:130] = np.nan
Notice that we are setting some of our Iris instances to NaN, this is how the algorithm will know which labels are missing.
Now, we must tell the algorithm how to transform this tabular data into a complex network. To do so we will use a KNNConstructor which uses a K-Nearest-Neighbors algorithm to create the graph. If you want to know more about it, you can check my previous post or look at the documentation of the library.
knn_c = KNNConstructor(k=5, sep_comp=False)
It is important to notice here that we are using the parameter set_comp to False. This parameter controls whether the labels of the data should be inserted into separate components. Since we want to propagate our labels, we cannot afford not to have edges between different labels because that would connect the NaNs only to themselves.
Finally, we will instantiate the propagator and fit it on the data:
propagator = ModularityLabelPropagation()
propagator.fit(X, y, constructor=knn_c)
One then can access the generated labels with:
propagator.generated_y
If we look at the entire code, we have just:
from sklearn.datasets import load_iris
from sknet.network_construction import KNNConstructor
from sknet.semi_supervised import ModularityLabelPropagation
X, y = load_iris(return_X_y = True)
knn_c = KNNConstructor(k=5, sep_comp=False)
y[10:20] = np.nan
y[70:80] = np.nan
y[110:120] = np.nan
propagator = ModularityLabelPropagation()
propagator.fit(X, y, constructor=knn_c)
propagator.generated_y
Of course that some of these labels will be incorrect. As with every Machine Learning algorithm, there will be no solution with 100% accuracy. However, this method provides a very good starting point for labeling your data.
If you want to know more about this algorithm, please check the reference number [1].
More about the sknet library
The sknet is a library that implements machine learning algorithms in complex networks and allows transforming data from one data type to several others. It aims to help researchers and practitioners to develop new solutions and improve existing machine learning methods.
Hope you enjoy and test the lib!
[1] Silva, T.C., Zhao, L, Semi-Supervised Learning Guided by the Modularity Measure in Complex Networks (2012), Neurocomputing. 78. 30–37. 10.1016/j.neucom.2011.04.042.
Labeling Data with Complex Networks was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3Ha3utt
via RiYo Analytics






ليست هناك تعليقات