https://ift.tt/3nPQpxX Data Lineage Explained To a Five-Year-Old And why all data teams are spending $$$ on family trees “Data lineage i...
Data Lineage Explained To a Five-Year-Old
And why all data teams are spending $$$ on family trees

“If I change this field, how can I know I won’t break any tables downstream?”
“The finance dashboard seems wrong. Where can I check what data powers it?”
“If I replace this table with another better-optimized one, what are all the dashboards I need to update with the new data table?”
I can’t say how many times I’ve asked myself these questions. Or how many times I heard those when I talk with data engineers, analytics engineers, or heads of data. In most companies, if you ask those questions, people will answer something like: “check out the source code” or “ask John, he knows”. The problem is that John often is one of the best engineers. And the reason he’s so good is that he doesn’t spend his time answering relentless pings on Slack.
That’s when data lineage comes into play. Let me take you through an introduction to data lineage. I’ll start by explaining what is data lineage, then explain the most common use-cases and I’ll finish with a deeper technical dive for the tech-savvy readers out there.
Important: the further you go in the article, the more technical it gets. Don’t be surprised.
What is data lineage?
‘Data lineage is like a family tree but for data’
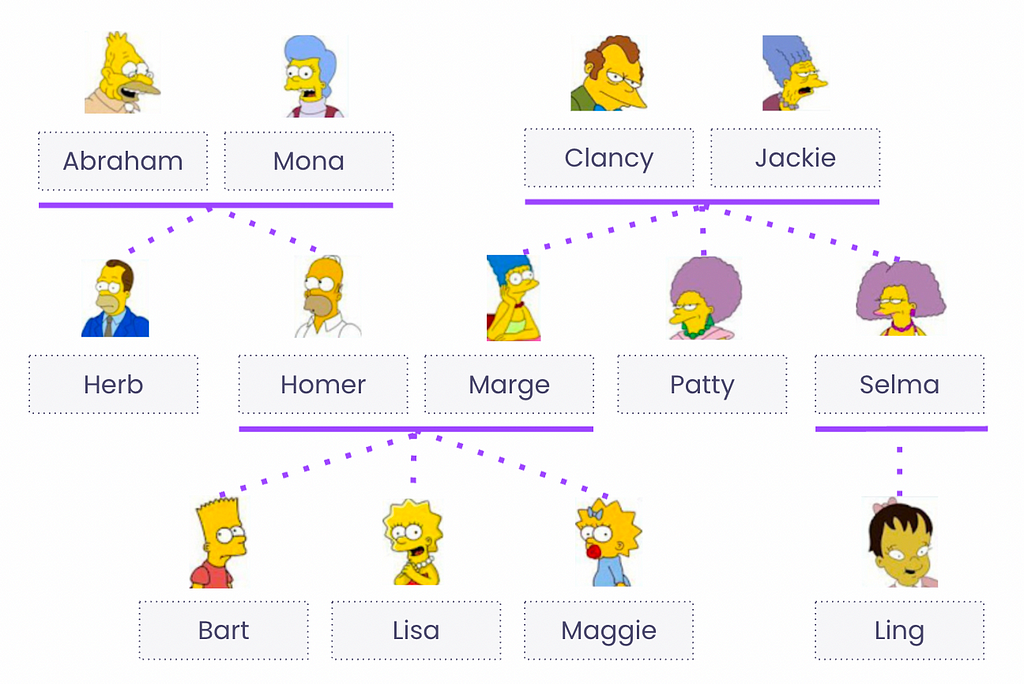
Data lineage is a technology that retraces the relationships between data assets. In the data world, you start by collecting raw data from various sources (logs from your website, payments, etc) and refine this data by applying successive transformations. In order to build one data table (we will call it a “child table”), you have to use one or more other data tables (we call these “parent tables”). The data lineage helps you rebuild the family tree of your data. If you have bad data, you can look for the ‘bad branch’ in that data family tree and cure it to the roots.
What does data lineage look like in reality?
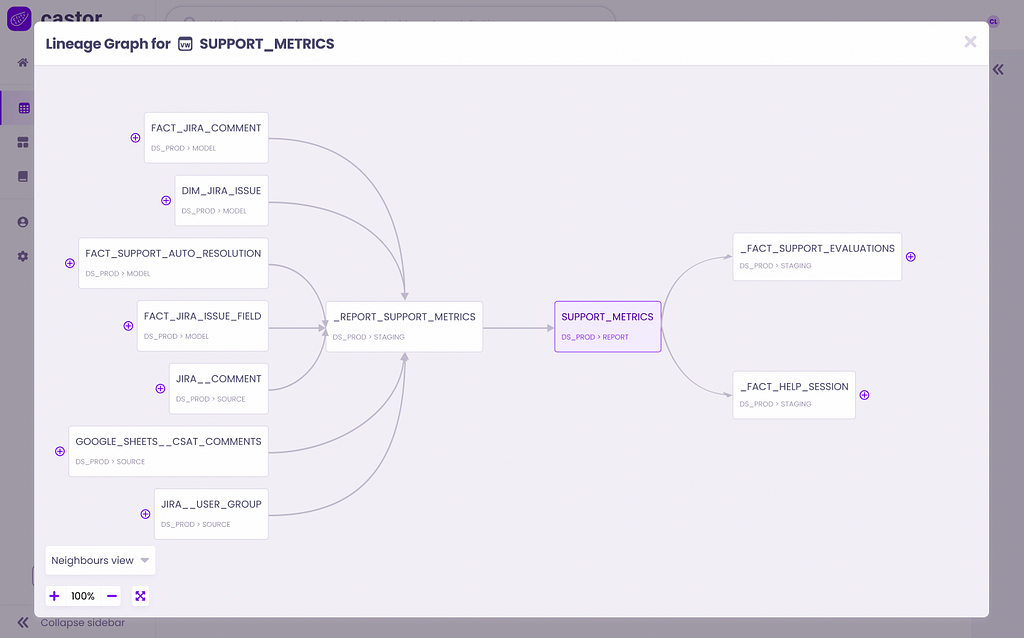
Data lineage can be overwhelming if you don’t know what you are looking at
New interfaces for data lineage tend to be simpler and address one use case per visualization in order to make it easier to understand for business experts. Here’s an example of data lineage in Castor.
Why do we need data lineage?
Data lineage use-cases
First of all, data lineage is a technology more than a product. It is one of the underlying technologies behind a lot of data products (data catalogs, data quality, data management, etc).
The reason data lineage is so popular is that there are a lot of new use-cases, both for business, engineering, leadership, and legal department. Let me try to explain the most common use-cases. Overall, data lineage helps get a bird’s eye view of the data systems.
Data Troubleshooting
“Find the problem at the source”
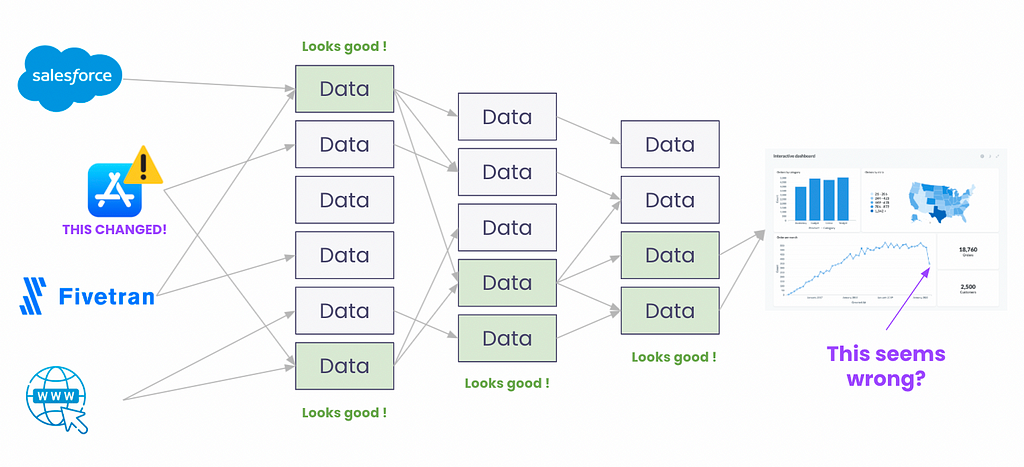
Data users sometimes spot weird behavior in dashboards or data tables. They want to investigate to know if this is due to a technical problem in the data pipelines or a business problem that needs attention right now. There’s nothing more humiliating for a data person to sound the alarm about a business problem (for example, a drop in revenue for the “active users” segment) when it really is a data pipeline that broke.
In the example above, the data in the dashboard drop drastically. The business user wants to understand why this happened. The underlying question is: “do I have a business problem or a data pipeline problem?”. He can check the status of all upstream data. In this case, the problem comes from a data source (the app store) that changed its API. This change broke the ETL job feeding data sources. In a few minutes, the user can understand the data system as a whole.
Impact analysis
“Am I going to break the CEO’s favorite dashboard?”
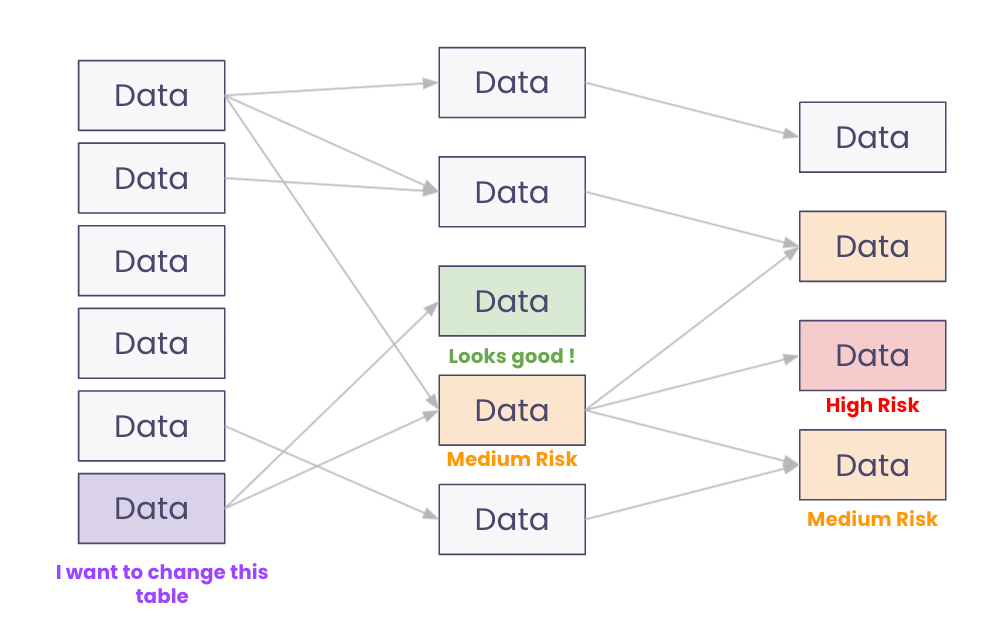
Data users want to know the impact of a change they want to make on the data flow, and on data resources downstream. In most organizations, data reports and dashboards are powered by data tables in the data lake. If an engineer makes a change, this will likely break data pipelines and processes. As a result, overall data quality and trust within the organization will drastically decrease.
Thanks to the lineage, engineers can identify all impacted resources and craft their code to minimize bad impact. If there is an impact, they can identify the data resources affected and send a warning to active users of those resources.
Discovery and Trust
“Garbage in, garbage out. But how do I check what’s goes in?”
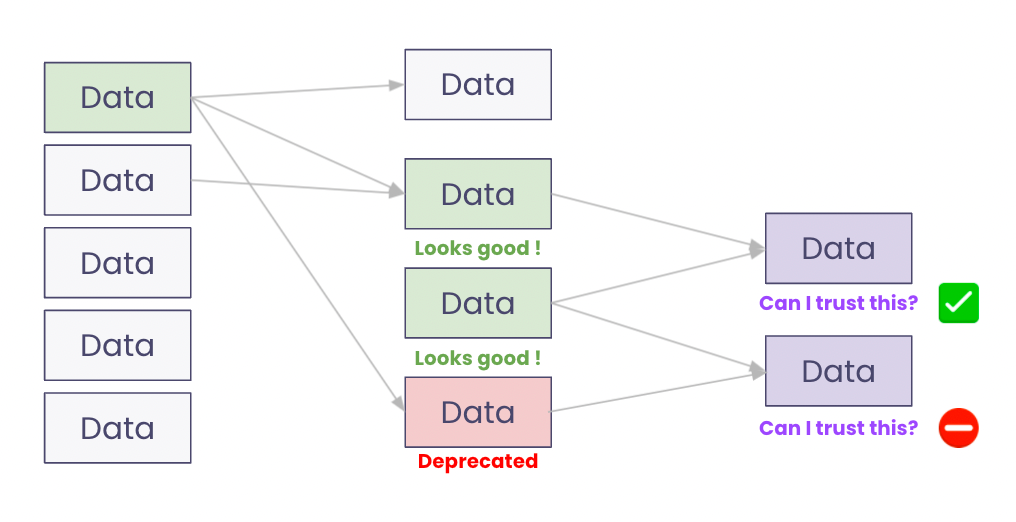
Users want to identify, understand and trust data resources (tables, reports, and dashboards) that they want to consume. When a user looks at data resources, knowing where it comes from helps to trust it. A saying says “garbage in, garbage out”. Knowing what is the data powering the dashboard on “active users” will give you information on how to read it and if you can trust it. Lineage will let you know that it is plugged to an “Approved by BI” table, with a Gold rating, and help you trust it faster.
Definition Propagation
“I am lazy. If only I could write documentation once and propagate it”
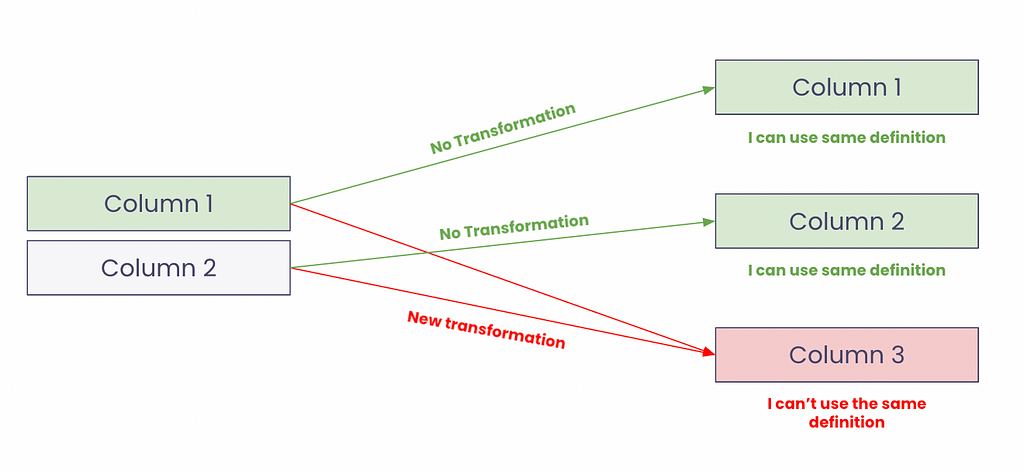
From a governance perspective, data lineage proved extremely powerful to propagate metadata. Users can easily propagate a definition across the data systems.
If a column is used in another table, without ongoing any transformation than it is fair to assume that in 99% of the cases the definition will be the same. Now, imagine your data catalog is connected to the column-level lineage metadata, you can be 10x more efficient in definition governance by documenting only the sources. If a popular column is used across hundreds of tables without any transformation, you can safely propagate the definition and attributes in a click.
Data lineage helps data governance teams from big data or enterprise companies deploy metadata management efforts in a scalable way. Indeed, in an environment with big data resources and numerous databases, understanding how the data flows and its provenance can be challenging. There is a lot of repetitive tasks.
Data Privacy Regulation (GDPR and PII mapping)
“I can’t protect what I don’t know I have”
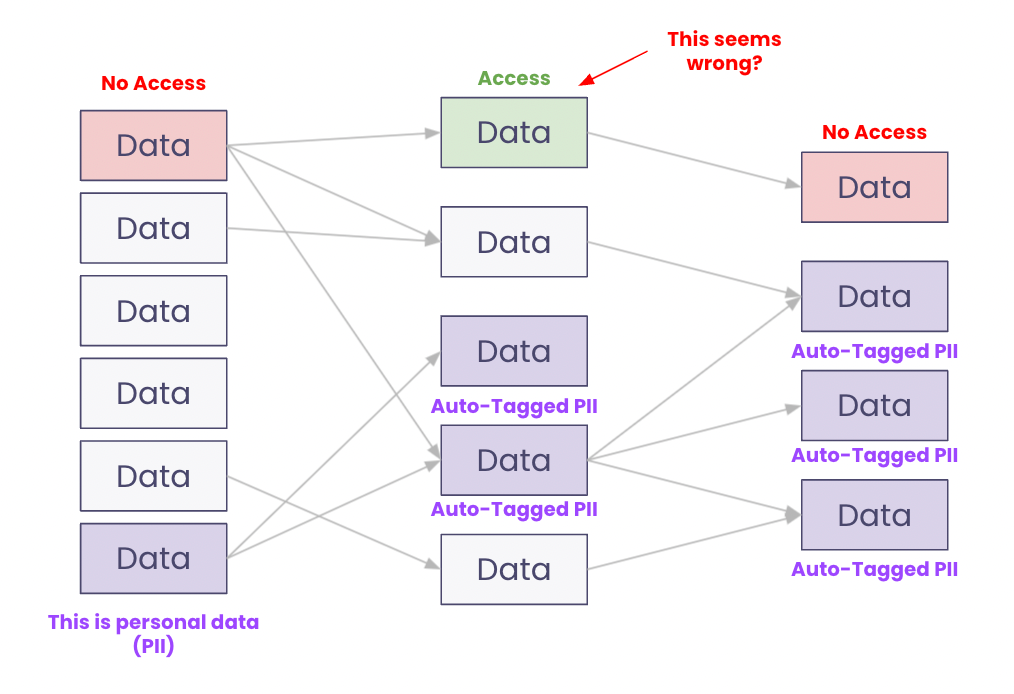
The logic is really similar to the logic above. Tagging personal or sensitive information can be a real pain. Today, it is a time-consuming task. Thanks to the lineage you can understand and track access rights along with dependence. Often you realize, you have some weakness in your roles policy. You have don’t have access to a child table or a parent table, but you have access to the middle table. This can be right, but it can also be dangerous as you can reconstruct/trace back the sensitive data.
Data lineage is really powerful to improve data governance, access rights management, and comply with GDPR regulation.
Data assets clean up or technology migration
“Please tell me! What should I keep?”
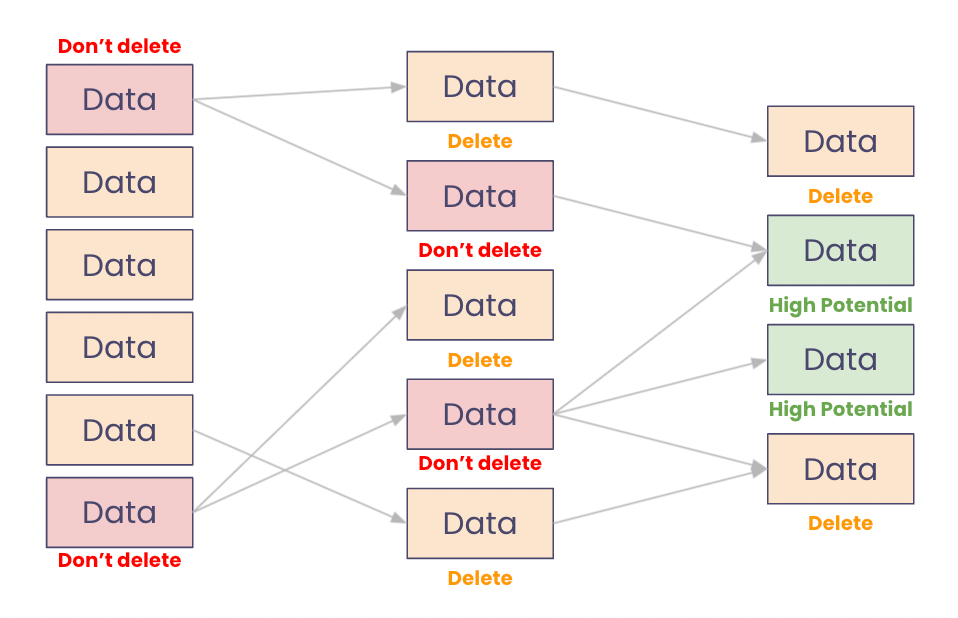
Data teams sometimes want to switch technologies. For example, an enterprise company moving from an old on-premise Oracle database to a cloud data warehouse like Snowflake or BigQuery. These big migrations are really expensive as everything is connected to everything. Tracing back dependence is a business-critical process before even starting such a project.
As part of this process, you want to identify data resources that you can delete versus those you want to migrate. This bird’s eye view helps lead architecture thinking.
Dive deeper into the technical aspect of data lineage
BEWARE —Data Lineage Experts Only.
What is the difference between Table and Column-level lineage?
Data lineage flow can exist under different formats. You can either trace parent-child relationships between data tables or columns in a specific table. Indeed, each column is created with other columns from other tables, sometimes even from the same table.
Column lineage is a subset of table lineage. If there is a link between two columns from different tables, then there is a link between the two tables. The opposite isn’t always true. Column lineage is providing the parent-child relationship at a column level without taking into account the tables underneath. It is a really powerful kind of lineage but can quickly be extremely hard to visualize as the number of connections grows. Column-level lineage system is also particularly hard to compute. Processing column-lineage is more expensive, takes longer, and requires a finer version of the parsing algorithm to understand the changes.
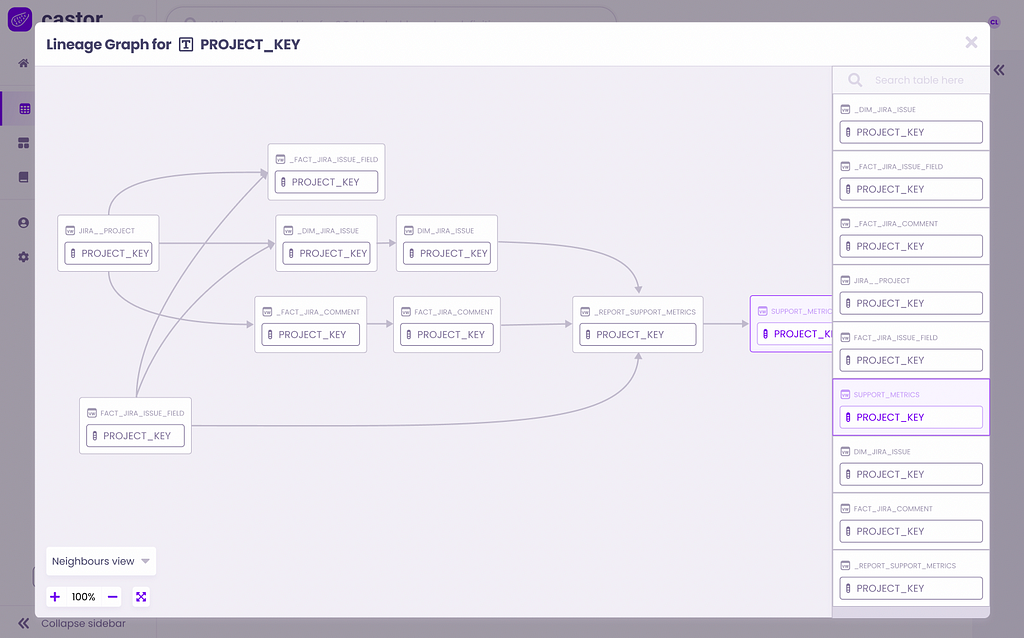
Table-level approach
In the SELECT SQL statement below, we are building a table child_table_1 with two other tables parent_table_1 (FROM clause) and parent_table_2 (JOIN clause). That means that if there is a change or a problem in one of the two “parent tables”, the child table might be affected by the change or the bug.

Column-level approach
In the SELECT SQL statement above, we are building three columns child_1, child_2, and child_3 in the child_table_1. The two first “child columns” are the same as the “parent columns” from parent_table_1 and parent_table_2. There is a direct lineage dependence.
The child_3 column is a sum of parent_table_1.parent_column1 and parent_table_1.parent_column1. There’s a lineage dependence here as well.
Data lineage gives a bird’s eye view of a data flow
It helps trace back relationships across data systems
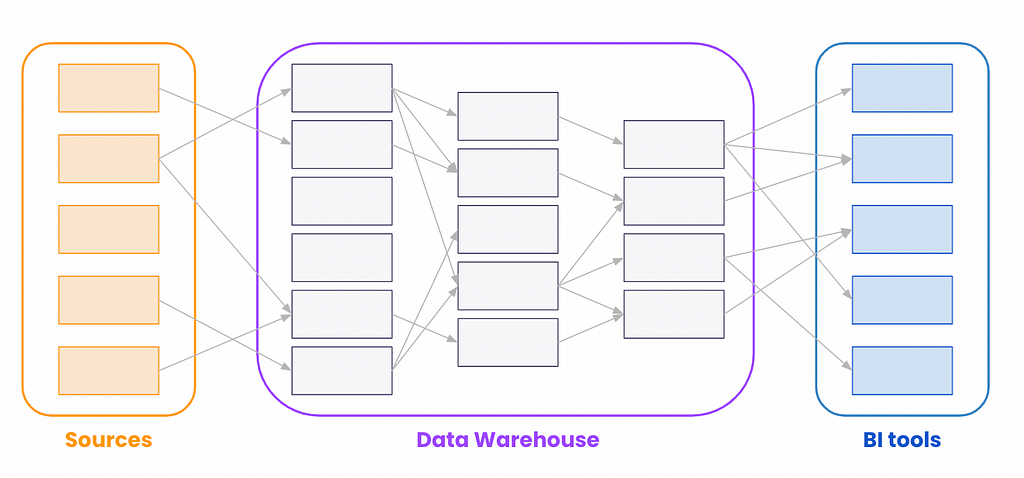
A few years ago, lineage was mostly about tracing relationships in the data lake or the data warehouse. This means a system tracking relationships between data tables. Now data lineage is cross-system.
Those tables are often powering BI tools such as Looker, Tableau, Mode, Metabase, PowerBI, etc. Mapping this flow proved really powerful for business users as well as engineers. Indeed, business users can fact-check the provenance and flow of the data easily while engineers can check the impact of a change on the business.
End-to-end lineage, from data sources (ETL) to business reports, is possible now that most BI tools have APIs, and that BI tools perform SQL queries on the data warehouse in a standardized way. When data catalog providers had to build as many versions of their lineage parser for each new tool, language, and integration, they can now build a lineage engine and wait to customize the last mile connector.
When and why did data lineage become so popular?
Data lineage recently gained traction. There are several reasons for that. The first one is that enterprises have more data, sooner than 10 years ago. There’s an increased need for metadata management tools. The second is that the data industry structured itself with tools and processes. This makes computing lineage for cloud technologies and companies much more easy and reliable. The last reason is the emergence of harsh data regulations across the continents (GDPR, HIPAA, etc) that makes lineage a must-have.
Those three structural changes are compounding trends. They will grow drastically over time. Companies will continue to gather more data and recruit more people to analyze it. The data industry will continue to structure itself and bring standard processes. Compliance with data regulation is today more a problem for enterprise companies but will soon arrive for mid-market and SMBs as tooling will make it easier to assess it.
For all these reasons, data lineage is entering the space for good and you might want to start investing in such a tool sooner than later.
More modern data stack analysis?
We write about all the processes involved when leveraging data assets: from the modern data stack to data teams composition, to data governance. Our blog covers the technical and the less technical aspects of creating tangible value from data.
If you’re a data leader and would like to discuss these topics in more depth, join the community we’ve created for that!
Originally published at https://www.castordoc.com.
Data Lineage Explained To My Grandmother was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3CK47qt
via RiYo Analytics








No comments