https://ift.tt/3cxq9lC By Jules S. Damji , Michael Galarnyk Phases of the Model Development Cycle (image by Jules S. Damji ) A common g...
By Jules S. Damji, Michael Galarnyk
A common grumble among data science or machine learning researchers or practitioners is that putting a model in production is difficult. As a result, some claim that a large percentage, 87%, of models never see the light of the day in production.
“I have a model, I spent considerable time developing it on my laptop. What’s next? How do I get it into our production environment? What should I consider for my ML stack and tooling?”
These questions frequently emerge at meetups or conferences, after talks on machine learning operations (MLOps). There is no singular panacea or silver bullet for this nascent field of MLOps Best Practices that attempts to address and remedy this crucial problem.
However, there are some acceptable and common technical considerations and pitfalls to keep in mind when considering your ML stack and tools. In this first part of a series on putting ML models in production, we’ll discuss some common considerations and common pitfalls for tooling and best practices and ML model serving patterns that are an essential part of your journey from model development to deployment in production.
Developing with Ease
Consider your development environment first. Most data scientists or ML engineers invariably use their laptops for development, testing or debugging code. Because of simplicity, easy to access and install the latest ML libraries, practitioners overwhelmingly prefer laptops over clusters for development. We are spoiled by IDEs and syntax-highlighted editors for good reason.
Python developers like to customize their environments to match their staging environment, with library dependencies using conda or Python virtual environments. Ideally, as a best practice, if the same code developed on their laptop can run with minimal changes on a staging or production environment on the cluster, it immensely improves the end-to-end developer productivity.
Consider your laptop as a preferred choice of development environment, with the possibility of extending or syncing your code to the cluster environment in the cloud.

Consideration Number #1: Use your laptop for development as a best practice
Training at Scale and Tracking Model Experiments
Unlike the traditional software development cycle, the model development cycle paradigm is different. A number of factors influence an ML model’s success in production. First, the outcome of a model is measured by its metrics, such as an acceptable accuracy.
Second, achieving an accuracy that satisfies the business goal means experimentation with not only one model or ML library but many models and many ML libraries while tracking each experiment runs: metrics, parameters, artifacts, etc. As vital as accuracy is, so is a developer’s choice of ML libraries to experiment with.

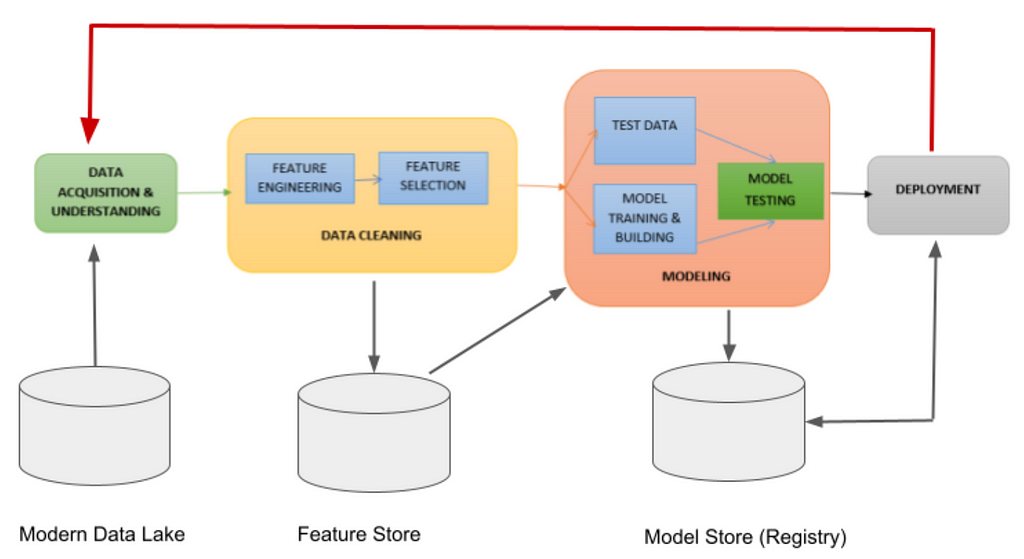
Third, accuracy is directly linked to the quality of acquired data: bad data results in a bad model. As the diagram below shows data preparation — feature extractions, feature selection, standardized or normalized features, data imputations and encoding — are all imperative steps before the cleansed data lands into a feature store, accessible to your model training and testing phase or inference in deployment.
Fourth, a choice of programming language that is not only familiar to your data team — data analysts, data scientists, and ML engineers — but also supported by many ML libraries employed during model experimentation and training phases. Python seems to be the de facto choice.
Alongside a choice of a programming language is the choice of an ML framework for taming compute-intensive ML workloads: deep learning, distributed training, hyperparameter optimization (HPO), and inference — all at horizontal scale — from your laptop, single node multiple cores to multiple nodes, with multiple cores.
And finally, the ability to easily deploy models in diverse environments at scale: part of web applications, inside mobile devices, as a web service in the cloud, etc.
Consideration Number #2: Consider using model life cycle development and management platforms like MLflow, DVC, Weights & Biases, or SageMaker Studio. And Ray, Ray Tune, Ray Train (formerly Ray SGD), PyTorch and TensorFlow for distributed, compute-intensive and deep learning ML workloads.
Managing Machine Learning Features
Feature stores are emerging pivotal components in the modern machine learning development cycle. As more data scientists and engineers work together to successfully put models in production, having a singular store to persist cleaned and featurized data is becoming an increasing necessity as part of the model development cycle shown.
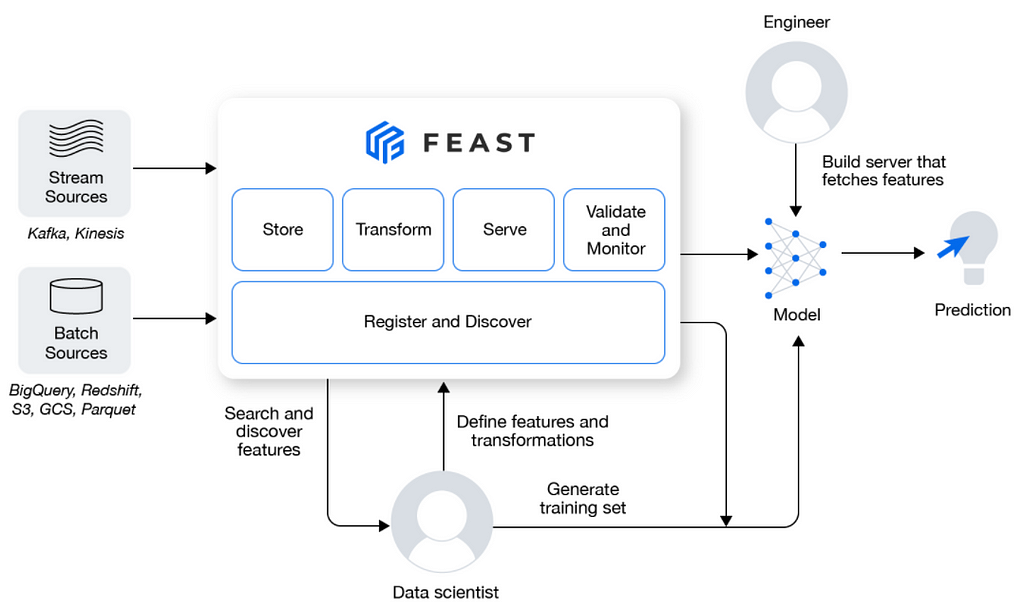
Feature stores address operational challenges. They provide a consistent set of data between training and inference. They avoid any data skew or inadvertent data leakage. They offer both customized capability of writing feature transformations, both on batch and streaming data, during the feature extraction process while training. And they allow request augmentation with historical data at inference, which is common in large fraud and anomaly detection deployed models or recommendation systems.
Aside from challenges and considerations of putting models in production, operationalizing ML data is equally important. Model accuracy depends on good data, and feature stores help manage precomputed and cleansed features for your model training and production inference during model serving.
Consideration Number #3: Consider feature stores as part of your model development process. Look to Feast, Tecton, SageMaker, and Databricks for feature stores.
Deploying, Serving and Inferencing Models at Scale
Once the model is trained and tested, with confidence that it met the business requirements for model accuracy, seven crucial requirements for scalable model serving frameworks to consider are:
Framework agnostic: A model serving-elected framework should be ML framework agnostic. That is, it can deploy any common model built with common ML frameworks. For example, PyTorch, TensorFlow, XGBoost, or Scikit-learn, each with its own algorithms and model architectures.
Business Logic: Model prediction often requires preprocessing, post processing or ability to augment request data by connecting to a feature store or any other data store for validation. Model serving should allow this as part of its inference.
Model Replication: Some models are compute-intensive or network-bound. As such the elected framework can fan out requests over to model replicas, load balancing among replicas to support parallel request handling during peak traffic.
Request Batching: Not all models in production are employed for real-time serving. Often, models are scored in large batches of requests. For example, for deep learning models, parallelizing these image requests to multiple cores, taking advantage of hardware accelerators, to expedite batch scoring and utilize hardware resources is worthy of consideration.
High Concurrency and Low Latency: Models in production require real-time inference with low latency while handling bursts of heavy traffic of requests. The consideration is crucial for best user experience to receive millisecond responses on prediction requests.
Model Deployment CLI and APIs: A ML engineer responsible for deploying a model should be able to use model server’s deployment APIs or command line interfaces (CLI) simply to deploy model artifacts into production. This allows model deployment from within an existing CI/CD pipeline or workflow.
Patterns of Models in Production: As ML applications are increasingly becoming pervasive in all sectors of industry, models trained for these ML applications are complex and composite. They range from computer vision to natural language processing to recommendation systems and reinforcement learning.
That is, models don’t exist in isolation. Nor do they predict results singularly. Instead they operate jointly and often in four model patterns: pipeline, ensemble, business logic, and online learning. Each pattern has its purpose and merit.
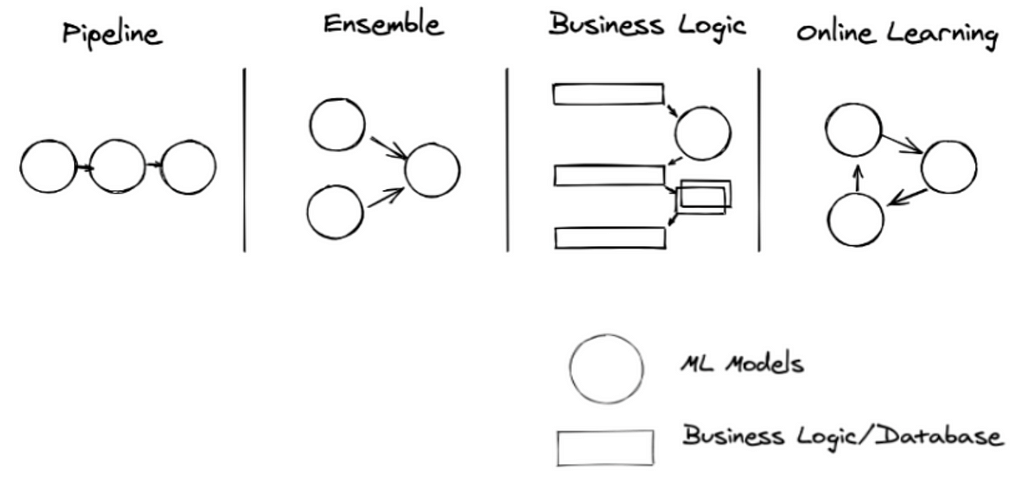
Machine Learning engineers adopt two common approaches to deploy these patterns of models in production. One is to embed models into a web server and the other is to offload to an external service. Each approach has its own pros and cons, with respect to the seven considerations above.
Consideration Number #4: Look to Seldon, KFServing, or Ray Serve for all these seven requirements.
Observing and Monitoring Model in Production
Model monitoring, often an overlooked stage as part of model development lifecycle, is critical to model’s viability in the post deployment production stage. It is often an afterthought, at an ML engineer’s peril.
Models have an afterlife of viability. That viable life in production needs a constant watchful or sentinel eye. In fact, monitoring as a phase is simply a continuation of the model serving, as depicted in the diagram below.
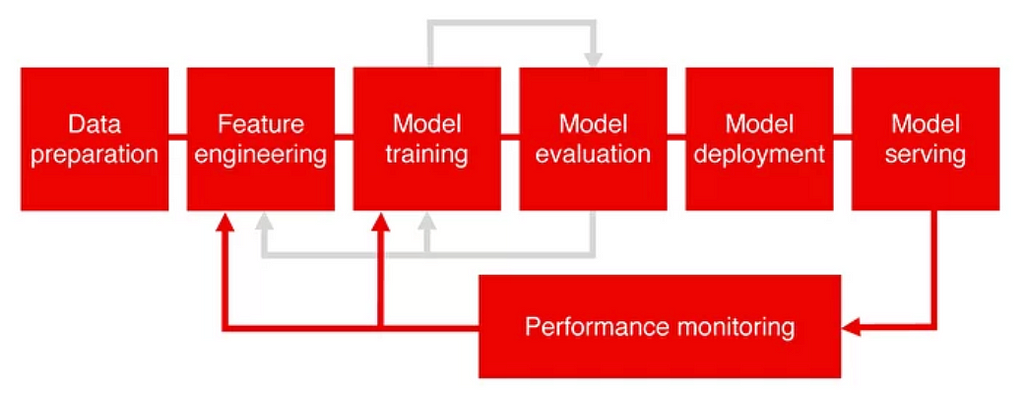
Why consider model monitoring? For a number of practical reasons, this stage is pivotal. Let’s briefly discuss them.
Data drifts over time: As we mentioned above, our quality and accuracy of the model depends on the quality of the data. Data is complex and never static, meaning what the original model was trained with the extracted features may not be as important over time. Some new features may emerge that need to be taken into account. For example, seasonal data changes. Such features drifts in data require retraining and redeploying the model, because the distribution of the variables is no longer relevant.
Model concept changes over time: Many practitioners refer to this as model decay or model staleness. When the patterns of trained models no longer hold with the drifting data, the model is no longer valid because the relationships of its input features may not necessarily produce the model’s expected prediction. Hence, its accuracy degrades.
Models fail over time: Models fail for inexplicable reasons: a system failure or bad network connection; an overloaded system; a bad input or corrupted request. Detecting these failures’ root causes early or its frequency mitigates user bad experience or deters mistrust in the service if the user receives wrong or bogus outcomes.
Systems degrade over load: Constantly being vigilant of the health of your dedicated model servers or services deployed is just as important as monitoring the health of your data pipelines that transform data or your entire data infrastructure’s key components: data stores, web servers, routers, cluster nodes’ system health, etc.
Collectively, these aforementioned monitoring model concepts are called model observability. This step is now an acceptable imperative in MLOps best practices. Monitoring the health of your data and models should never be an afterthought. Rather, it ought to be part and parcel of your model development cycle.
Consideration Number #5: For model observability look to Evidently.ai, Arize.ai, Arthur.ai, Fiddler.ai, Valohai.com, or whylabs.ai.
Conclusion
Let’s recap. To avoid the common grumble of models not making it to production or having your model see the light of the day in production, take into account all the above considerations at heart if you want your models to journey to their desired destination — and have a viable afterlife too.
Each consideration has its merits. Each consideration has either an open source solution addressing each problem or a managed solution from a vendor. Evaluate how each best fits and meets all the considerations into your existing machine learning tooling stack.
But making it part and parcel of your ML model development tooling stack is crucial; it will significantly improve your end-to-end success in putting your models into production.
In future blogs, we will examine how you can implement consideration #1 and #2, focusing on some of the tools we suggested.
Originally published at https://www.anyscale.com.
Considerations for Deploying Machine Learning Models in Production was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3FAUDzk
via RiYo Analytics






ليست هناك تعليقات