https://ift.tt/3Hb68iC Photo by benjamin lehman on Unsplash Whether you’re building out analytics or looking to train a machine learni...

Whether you’re building out analytics or looking to train a machine learning model, the basis of data engineering, analytics, and science is having access to data. Data itself can be gathered from many different sources: web scraping, API calls, flat files; but one of the most common sources of data storage across enterprises is structured databases, which are commonly referred to as SQL databases.
SQL databases are an encompassing term which refer to Relational Database Management Systems (RDBMS) which are interacted with using the Structured Query Language (SQL queries). SQL Databases are capable of rapidly processing and storing large amounts of data, making them a very commonly used application across Enterprises for data storing and management.
While the SQL language is capable of performing standard analytics (GROUP BY / FILTER / etc…) on the database, in practice many enterprises discourage heavy SQL use directly on the database itself as they are either hot databases (live as needed by the software applications they serve) or reporting databases (synchronized from the hot DB for data-pulling use exclusively). Furthermore, due to the limitations of the SQL language, many statistical and machine learning tools are not available, and as such it is common practice within Enterprise environments to ingest the data prior to handling.
Data ingestion is the process of taking data from one storage medium (the source) and dumping it to a different storage medium (the sink) which is much more suited for data manipulation. When it comes to Big Data, the most common sink for data ingestions at scale in enterprise environments is the Data Lake (typically via the Hadoop Ecosystem). Once the data is in the Lake, it can be freely transformed or manipulated by any of the Hadoop Ecosystem tools (Spark, Pig, etc.) or converted to a different form as preferred by the developer. In order to ingest the data from a SQL database to your medium of choice, a connector must be used as part of the developed software application.
ODBC / JDBC Drivers
Open Database Connectivity (ODBC) is an API standard adopted by databases which allow software applications to interface with database management systems (DBMS). In this respect an ODBC Driver or a Java Database Connector (JDBC) Driver are both practical applications of these standards which can be used by a software application to connect to a database as depicted in Fig. 1.
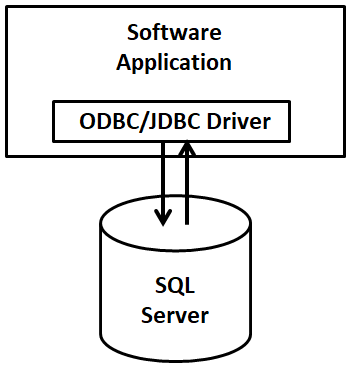
As each database engine (MySQL, Microsoft SQL, PostGreSQL, Oracle, etc…) operates differently internally, each database engine has its own specific ODBC/JDBC Driver used for interaction. These ODBC/JDBC drivers all function similarly however and therefore many programming languages have a standard way of invoking the various ODBC/JDBC Drivers used to connect to these databases. Once the software application loads the ODBC/JDBC Driver, the Driver is then configured to point to and interact with the SQL Database, which requires setting: the host/URL, the database name, and credentials which can access the dataset.
In order to demonstrate the different ways of establishing such connections to ingest or load data from a SQL DB, this tutorial will cover ingestions using: Python (pyodbc package), Spark (both Scala Spark and PySpark), and Sqoop (a data ingestion tool for the Hadoop Ecosystem). Furthermore Docker will be used to containerize the environment, to more closely mimic Enterprise environments and allow for easy replication of the demonstration by the reader.
Docker
Docker is a tool that allows you to easily build and deploy lightweight virtual machines, otherwise known as containers, which can be connected to form a network. In most practical Enterprise circumstances, the software application requiring data from a SQL Server will not run on the same machine as the SQL Server, and as such we can mimic such an Enterprise environment using the Docker architecture shown in Fig. 2.
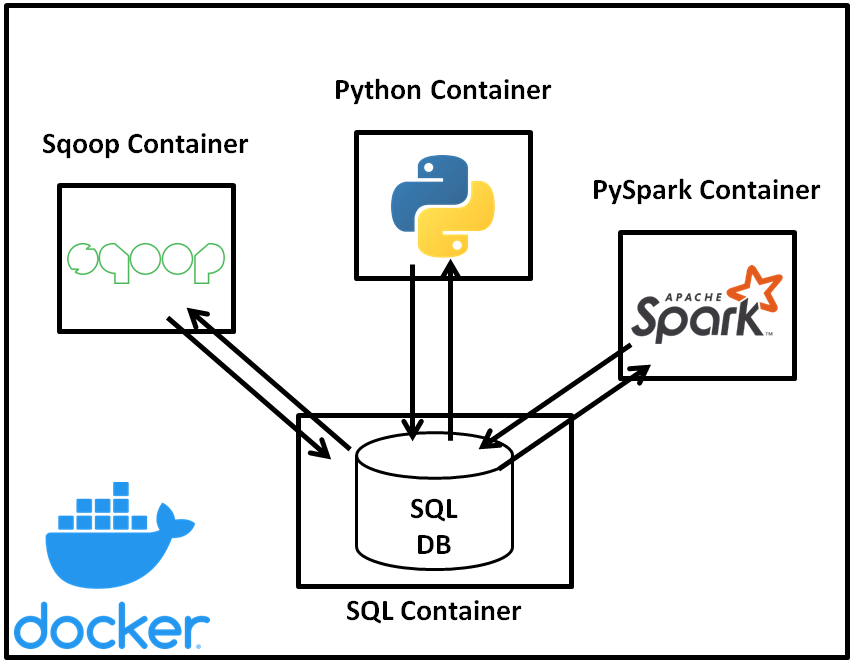
For ease of following along with the tutorial, the above Docker environment and all scripts used to connect to the MySQL database are available on GitHub [1].
Setting Up the SQL Database Using MySQL
MySQL is a common database engine used for storing and managing structured data which is common in Enterprise architectures, and represents an Open Source (and easily available) SQL DB for local deployment to build our sandbox Enterprise environment.
MySQL offers a base Docker image, mysql/mysql-server [2], which launches a pre-installed instance of MySQL in a container that will act as the SQL Server in our mock Enterprise environment.
This Docker image accepts .sql scripts as commands to run when the container initializes, which we can use (with the .sql script below) to configure the database and create fake data for our connection test.
-- Create database
CREATE DATABASE test_db;
USE test_db;
-- Create table
CREATE TABLE test_table(
row_id INT AUTO_INCREMENT PRIMARY KEY,
test_value VARCHAR(255) NOT NULL
);
-- Fill table with values
INSERT INTO test_table(test_value) VALUES ("A");
INSERT INTO test_table(test_value) VALUES ("b");
INSERT INTO test_table(test_value) VALUES ("C");
INSERT INTO test_table(test_value) VALUES ("4");
-- Add user with remote access priveleges
CREATE USER "remote_connect_user"@"%" IDENTIFIED BY "remote_connect_password";
GRANT ALL PRIVILEGES ON * . * TO "remote_connect_user"@"%" WITH GRANT OPTION;
FLUSH PRIVILEGES;
The code above performs two main functions:
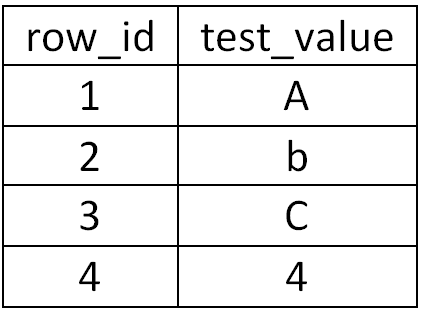
- The MySQL server creates a database (named test_db), creates a table (named test_table) within the database, and fills test_table with a handful of records (see table I below) which we can verify on the receiving end when we attempt to pull data
- The MySQL server creates a user account (name: remote_connect_user, password: remote_connect_password) with privileges to access the database remotely
Table I: test_db.test_table values
With our MySQL database set up, we can then focus on how to pull the data through various software applications, starting with Python (and the pyodbc package) in this tutorial.
MySQL DB Connection Using Python (via pyodbc)
Connecting to SQL DB’s using Python is easily performed by invoking one of many ODBC packages available using pip install. In this tutorial, we will focus on connecting to the MySQL DB with Python using the pyodbc [3] package, which comes out-of-the-box as a Docker Image, laudio/pyodbc [4], and includes the MySQL ODBC 8.0 Driver.
In order to connect to the container to establish a python connection, we can run the command:
docker exec -it sql-ingestion-tutorial-python-client-1 python
which remotely connects to the container and starts an interactive session of python in the container itself.
With python loaded, we can use the following code to load the pyodbc package, configure the settings for the driver to connect to our MySQL instance, and run a test query to SELECT * and output the results in the console.
# Imports
import pyodbc
# Set configuration for DB
MYSQL_HOST="mysql-server"
MYSQL_USER="remote_connect_user"
MYSQL_PASS="remote_connect_password"
MYSQL_DB="test_db"
MYSQL_TABLE="test_table"
# Establish connection to MySQL DB
cnxn = pyodbc.connect(f"DRIVER=;SERVER={MYSQL_HOST};DATABASE={MYSQL_DB};UID={MYSQL_USER};PWD={MYSQL_PASS}")
cursor = cnxn.cursor()
# Run query to select * and output results
cursor.execute(f"SELECT * FROM {MYSQL_TABLE}")
row = cursor.fetchone()
while row:
print (row)
row = cursor.fetchone()
In this case, the pyodbc.connect function references the pre-installed ODBC Driver for MySQL DB’s, and the driver is configured to include the server URL, the database name, and the credentials being invoked to run the queries. The test command than references this connection by running the SELECT * statement on the table in the DB, and iteratively prints the outputs as seen below.
(1, 'A')
(2, 'b')
(3, 'C')
(4, '4')
MySQL DB Connection Using Apache Sqoop
Apache Sqoop [5] is a tool within the Hadoop Ecosystem used for bulk transfer of data in structured databases to and from the Hadoop filestore. While Apache Sqoop was retired in June 2021 [6], the tool is commonly used by Enterprises to ingest data into the Data Lake, and will realistically take some time to fully retire from Enterprise production systems.
Similarly to other containers, Apache Sqoop is readily available out of the box using the dvoros/sqoop image [7], which comes preloaded with Apache Sqoop and all Hadoop Ecosystem tools used to support Sqoop.
The Sqoop image does not contain the JDBC Driver which will be used by Sqoop to connect to the MySQL DB, and therefore the Docker container being launched includes mounting the JDBC Driver to the container which Sqoop will automatically recognize when placed in the /usr/local/sqoop/lib folder. Considering the connection is being made to a MySQL DB, we can acquire this connector by downloading the platform independent version of the connector made available on the MySQL website [8].
Sqoop itself has many parameters to assist in common data ingestion functions [9], however for purposes of this tutorial the demonstration will be a basic ingestion in text form from the MySQL DB to HDFS using code given below:
# Create the data ingestion location
hdfs dfs -mkdir /user/sqoop
# Sqoop import example
MYSQL_HOST=mysql-server
MYSQL_USER=remote_connect_user
MYSQL_PASS=remote_connect_password
MYSQL_DB=test_db
MYSQL_TABLE=test_table
sqoop import --connect jdbc:mysql://$MYSQL_HOST/$MYSQL_DB --table $MYSQL_TABLE --username $MYSQL_USER --password $MYSQL_PASS --as-textfile --target-dir /user/sqoop/text -m 1
# Test the output
hdfs dfs -ls /user/sqoop/text
# Inspect the parquet file
hdfs dfs -cat /user/sqoop/text/part-m-00000
As seen in the code, a target folder in HDFS is first created to store the ingested data. The Sqoop ingestion process is executed directly from the command line, and similarly to the other applications of establishing a connection, the MySQL connector is referenced and configured to point to the proper table location and credentials.
1,A
2,b
3,C
4,4
The end result of the code is shown above, which verifies that a snapshot of the MySQL DB has been ingested to HDFS. At this point, it can be picked up natively in Hadoop by Spark or other means.
MySQL DB Connection Using Spark
Similarly as the examples above, we can leverage a Docker container which comes with Spark installed out-of-the-box, in this case we will employ the jupyter/pyspark-notebook image [10]. Unlike the other connections however, we must include the JDBC Driver as an added jar file for Spark when we submit our application. Exemplified below is the sample code to connect to the MySQL DB for both Scala Spark and PySpark.
Connecting to MySQL DB Using Scala Spark
As performed with prior containers, we first run the following command to connect to the Spark container and invoke the Scala prompt:
docker exec -it sql-ingestion-tutorial-pyspark-client-1 spark-shell --jars /jdbc/*
After connecting to the Scala prompt, the following commands invoke the JDBC Driver to connect to the DB and print the resultant data to verify a successful connection.
// Set configuration for DB
val MYSQL_HOST="mysql-server";
val MYSQL_USER="remote_connect_user";
val MYSQL_PASS="remote_connect_password";
val MYSQL_DB="test_db";
val MYSQL_TABLE="test_table";
// Establish connection for MySQL DB using credentials provided
val df = (spark.read
.format("jdbc")
.option("url", s"jdbc:mysql://$MYSQL_HOST/$MYSQL_DB")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("dbtable", MYSQL_TABLE)
.option("user", MYSQL_USER)
.option("password", MYSQL_PASS)
.load())
// Display results for validating successful connection
df.show()
With a successful connection established, the following output is generated.
+------+----------+
|row_id|test_value|
| 1| A|
| 2| b|
| 3| C|
| 4| 4|
+------+----------+
Connecting to MySQL DB Using PySpark
In order to connect to the PySpark prompt, the same container used previously will be invoked, however the following command will instead launch a PySpark session for connecting to the DB.
docker exec -it sql-ingestion-tutorial-pyspark-client-1 pyspark --jars /jdbc/*
The PySpark version of the code to invoke the JDBC Driver and pull the data is as follows:
# Set configuration for DB
MYSQL_HOST="mysql-server"
MYSQL_USER="remote_connect_user"
MYSQL_PASS="remote_connect_password"
MYSQL_DB="test_db"
MYSQL_TABLE="test_table"
# Establish connection for MySQL DB using credentials provided
df = spark.read.format('jdbc').options(
url = f"jdbc:mysql://{MYSQL_HOST}/{MYSQL_DB}",
driver = "com.mysql.cj.jdbc.Driver",
dbtable = MYSQL_TABLE,
user = MYSQL_USER,
password = MYSQL_PASS
).load()
# Display results for validating successful connection
df.show()
With a successful connection established, the following output is seen.
+------+----------+
|row_id|test_value|
| 1| A|
| 2| b|
| 3| C|
| 4| 4|
+------+----------+
Conclusion
Without data, there is no opportunity for analytics or data science to benefit the business. Most Enterprise systems rely heavily on SQL databases to store vast amounts of data, and not every team has access to a dedicated Data Engineer or warehouse which provides easy access to data for development. In this case it is worth learning these skills yourself to greatly make your life easier. This article briefly outlined the usage of ODBC and JDBC Connectors to establish a connection to databases in software applications, demonstrated using Python (pyodbc package), Sqoop, and Spark (PySpark and Scala Spark).
References
[1] SQL Ingestion Tutorial Github Page, https://github.com/mkgray/sql-ingestion-tutorial
[2] MySQL Server Dockerfile, https://hub.docker.com/r/mysql/mysql-server/
[3] PyODBC Package, https://pypi.org/project/pyodbc/
[4] PyODBC Dockerfile, https://hub.docker.com/r/laudio/pyodbc
[5] Apache Sqoop, https://sqoop.apache.org/
[6] Apache Sqoop Attic, https://attic.apache.org/projects/sqoop.html
[7] Apache Sqoop Dockerfile, https://hub.docker.com/r/dvoros/sqoop
[8] MySQL JDBC Connector, https://dev.mysql.com/downloads/connector/j/
[9] Apache Sqoop User Guide, https://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
[10] Spark Dockerfile, https://hub.docker.com/r/jupyter/pyspark-notebook
Connecting to SQL Databases for Data Scientists, Analysts, and Engineers was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3HeqI1C
via RiYo Analytics






ليست هناك تعليقات