https://ift.tt/3rkYoVK Applied Concurrency Techniques in ETL Pipelines Python concurrency approaches with a case scenario Photo by Burs...
Applied Concurrency Techniques in ETL Pipelines
Python concurrency approaches with a case scenario

Concurrency means running the constituted parts of the program in an overlapping time interval & parallelism implies the ability to run all parts in parallel (this also depends on the system’s capability like multi-core and language support). If we want the program to multitask (parallelism) or behave like multi-tasking (concurrency), we must understand what, when & how these concepts are applied. Today, in this post, I will try to explain — these techniques and their implementation through a simple ETL pipeline.
Glossary:
- Introduction about python techniques.
- Implementation through a sample ETL process
- Execution time chart of all techniques
Introduction: In python, we have a powerful module to achieve concurrency/parallelism in any program. Here, below are the three such necessary modules to implement —
- concurrent.futurers.ThreadPoolExecutor
- concurrent.futures.ProcessPoolExecutor
- asyncio
We will use the above modules in each separate pipeline and read the performance, but before that, let’s try to know what these modules are about?
- The concurrent. futures package provides the Executor interface, which can submit jobs to threads or processes. A job can be submitted to thread to implement multithreading(ThreadPoolExecutor will be used), and a job submitted to the process to implement multiprocessing, then ProcessPoolExecutor can be used.
- asyncio (asynchronous i/o)— on the other hand, is similar to threading, but here it archives concurrency through a single thread or by events loop.
Now, we discuss when & which module will be suited to any specific scenario in our implementation section —
Implementation— We will take a CSV file with airport frequency records processed through the extract function in our example ETL process. The transformation function concatenates these two values [‘airport_ident,’’***’] to a new column in the output file. This is a pretty straightforward scenario to display the flow of ETL execution to implement our techniques(concurrency/parallel).
The threads support i/o bound operation, network i/o, disk operations, and the multiprocess support CPU-bound operations. There are many good articles on the platform to understand what threads & processes are and why they are operation-specific! To continue our discussion, we need to understand which component/module supports which kind of operation.
Below are how it can be run using each technique.
- Multithreading — as we already discussed, each thread’s operation runs concurrently in overlapped time intervals. And this overlap is as quick as it is executed in a parallel fashion.
Also, while implementing multithreading, we need to remember a few things, like race conditions between threads make the program’s critical sections error-prone; in ETL or any program, this could lead to corrupt data load/process. To avoid such race conditions or control the flow of task execution, we can use locks or semaphores. As shown in our ETL example. Also, the below example screenshot displays how threads are executed, which thread is currently entered, and exited execution!
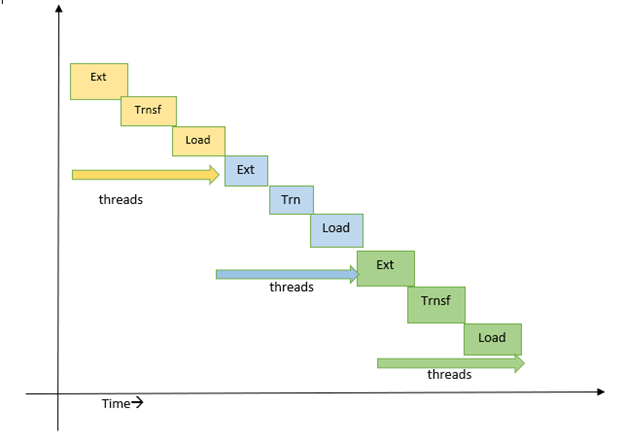
Note- In threading in python, we also have to remember one important thing, i.e., GIL(global interpreter lock), which makes any program run with only one thread at a time by applying a global lock on an interpreter.
from concurrent.futures import ThreadPoolExecutor
import pandas as pd
import time
##Threading:
##- A new thread is spawned within the existing process
##- starting a thread is faster than starting a process
##- memory is shared between all threads
##- mutexes often necessary to control access to shared data
##- on GIL (Global Interpreter Lock) for all threads
##semaphore locks with lock access count
semTrn = Semaphore(4)
semLd = Semaphore(4)
def extract(file):
dtype_dict = {'id': 'category',
'airport_ref': 'category',
'airport_ident': 'category',
'type': 'category',
'description': 'category',
'frequency_mhz': 'float16'
}
df = pd.read_csv(file, dtype=dtype_dict, low_memory=False)
return df
def transform(df):
##semaphore lock
semTrn.acquire()
print("thread {} acquired tranform lock ".format(threading.currentThread().ident))
##basic transformation operation
df['ref_code'] = df['airport_ident'].astype(str)+str('***')
semTrn.release()
print("thread {} released tranform lock ".format(threading.currentThread().ident))
print("thread {} acquired load lock ".format(threading.currentThread().ident))
semLd.acquire()
load(df)
def load(tdf):
tdf.to_csv('airport_freq_output.csv', mode='a', header=False, index=False)
semLd.release()
print("thread {} released load lock ".format(threading.currentThread().ident))
print("thread {} load completion ".format(threading.currentThread().ident))
def main():
pd.set_option('mode.chained_assignment', None)
file = 'airport_freq.csv'
df = extract(file)
chunk_size = int(df.shape[0] / 4)
##t = [0] * 4
executor = ThreadPoolExecutor(max_workers=4)
lst = list()
for start in range(0, df.shape[0], chunk_size):
df_subset = df.iloc[start:start + chunk_size]
##df_subset.is_copy=None
lst.append(executor.submit(transform, df_subset))
for future in lst:
future.result()
executor.shutdown()
if __name__ == "__main__":
start = time.time()
main()
end = time.time() - start
print("Execution time {} sec".format(end))
2. Multiprocessing — In this, python offers the ability to run program tasks as each process and the limitations of global interpreter lock are also extended(means we can officially run each task parallelly through multiprocessing interface), but this comes with particular other pacts like each process takes more creation time than threads. Also, each process needs its own execution space in memory; this makes it costly, so until the users are required to run any CPU-specific activities, the multiprocessing can be expensive for i/o related tasks. The execution flow is shown below with sample ETL implementation.
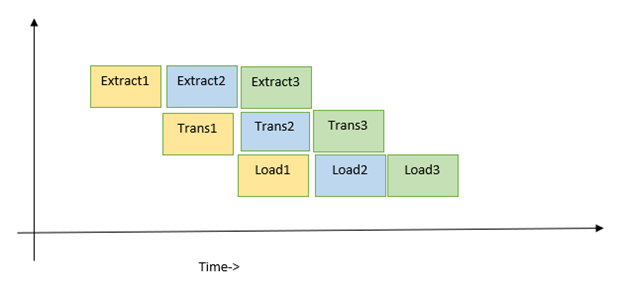
from concurrent.futures import ProcessPoolExecutor
import pandas as pd
import time
##MultiProcessing
##- A new process is started independent from the first process
##- Starting a process is slower than starting a thread
##- Memory is not shared between processes
##- Mutexes not necessary (unless threading in the new process)
##- One GIL(Global Interpreter Lock) for each process
semTrn = Semaphore(5)
semLd = Semaphore(5)
def extract(file):
dtype_dict = {'id': 'category',
'airport_ref': 'category',
'airport_ident': 'category',
'type': 'category',
'description': 'category',
'frequency_mhz': 'float16'
}
df = pd.read_csv(file, dtype=dtype_dict, low_memory=False)
return df
def transform(df):
print("process {} transform started ".format(multiprocessing.current_process().pid))
##basic transformation operation
semTrn.acquire()
df['ref_code'] = df['airport_ident'].astype(str)+str('***')
semTrn.release()
print("process {} transform completion ".format(multiprocessing.current_process().pid))
semLd.acquire()
load(df)
def load(tdf):
print("process {} load started".format(multiprocessing.current_process().pid))
tdf.to_csv('airport_freq_output.csv', mode='a', header=False, index=False)
semLd.release()
print("process {} load completion ".format(multiprocessing.current_process().pid))
def main():
file = 'airport_freq.csv'
df = extract(file)
chunk_size = int(df.shape[0] / 4)
executor = ProcessPoolExecutor(max_workers=5)
lst = list()
for start in range(0, df.shape[0], chunk_size):
df_subset = df.iloc[start:start + chunk_size]
lst.append(executor.submit(transform, df_subset))
for future in lst:
future.result()
executor.shutdown()
if __name__ == "__main__":
start = time.time()
main()
end = time.time() - start
print("Execution time {} sec".format(end))
3. Asyncio — This module provides high-performance for any network, disk, or web-based operations. We can able to write concurrent code using the asyncio module. And this can be implemented using async/await conditions in functions; the below execution of the ETL example displays implementation of the asyncio technique.
import asyncio
import time
import pandas as pd
##coroutine - wrapped version of the function to run async
##async function in python is typically called coroutine
##coroutines declared with async/await syntax
##coroutines are special functions that return coroutine objects when called
##event loop -
##the event loop is a very efficient task manager
##coordinate tasks
##run asynchronous tasks and callbacks
def extract(file):
dtype_dict = {'id': 'category',
'airport_ref': 'category',
'airport_ident': 'category',
'type': 'category',
'description': 'category',
'frequency_mhz': 'float16'
}
df = pd.read_csv(file, dtype=dtype_dict,low_memory=False)
return df
async def transform(df):
df['ref_code'] = df['airport_ident'].astype(str)+str('***')
await load(df)
async def load(tdf):
tdf.to_csv('airport_freq_out.csv', mode='a', header=False, index=False)
await asyncio.sleep(0)
async def main():
pd.set_option('mode.chained_assignment', None)
file = 'airport_freq.csv'
df = extract(file)
chunk_size = int(df.shape[0] / 4)
for start in range(0, df.shape[0], chunk_size):
df_subset = df.iloc[start:start + chunk_size]
x = asyncio.create_task(transform(df_subset))
await x
start = time.time()
asyncio.run(main())
end=time.time()-start
print("execution time {} sec".format(end))
Execution time:
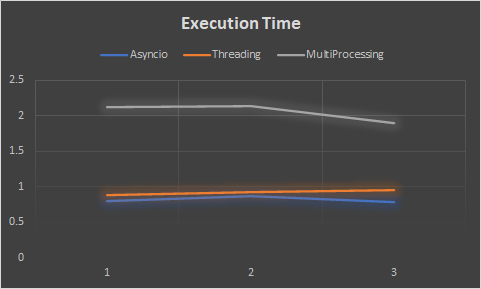
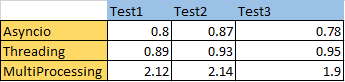
Conclusion: From our sample runs, we can assume the approach of asyncio threading is suitable for our scenario as it involves i/o processing of a file. The multiprocessing is being costly to our system, though it involves parallel processing.
Today’s post highlighted the techniques to apply concurrency/parallelism with a sample ETL example. I hope this detail is of some help to understand these techniques and make use in your implementations. I will try to implement these techniques on operations like groupby & aggregation of any datasets in the future post.
GitHub Location — https://github.com/Shivakoreddi/ConcurrencyPipelines
Reference:
- Python Docs, https://docs.python.org/3/library/asyncio.html
- Serdar, https://www.infoworld.com/article/3632284/python-concurrency-and-parallelism-explained.html, 2021
- PyMOTW, http://pymotw.com/2/threading/
Applied Concurrency Techniques for ETL Pipelines was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3pdRS0q
via RiYo Analytics







ليست هناك تعليقات