https://ift.tt/3C2YqnI Vacuum tubes in a Fender Blues Jr. Amplifier (Image by Author) How difficult would life be if every new thing had...

How difficult would life be if every new thing had to be learned from scratch? If once you learned the word “dog”, you had to once again learn that letters are symbols with sounds and you can put them together to make words and that “c-a-t” is a different four-legged animal with a tail?
Thankfully, our brains are great at recognizing patterns. If you already know that the word “dog” means one animal, then it’s not a huge stretch to understand that the word “cat” represents a different animal. Using what we already know to solve a similar problem is the concept behind transfer learning in artificial neural networks.
Transfer learning is a technique in machine learning where information gained from solving one problem is applied to a similar but different problem. Practically speaking, this technique can be used to attain faster convergence or lower loss when training a neural network. It can also be used when there is a lack of training data for a particular problem.
This article presents the results of several experiments using transfer learning to model guitar effects and amplifiers. (For an introduction to using neural networks for emulating analog guitar effects and amps, start here.)
Experiment Setup
A couple of assumptions were made for these tests. First, the original models and the “transfer-learning enhanced” models use the exact same layers and layer sizes (an LSTM size 20, followed by dense layer). A tricky part of transfer learning is accounting for model architecture differences and keeping the relevant information intact. Using the same model simplifies things considerably.
Second, only devices of similar sound (distortion level) were used for each transfer learning test. A distortion pedal to another distortion pedal and an amp to another amp at similar overdrive levels was tested. Each target device was first trained starting from scratch (baseline). Next, a pre-trained model was used as the starting point (transfer learning enhanced).
Two runs were conducted for each device pair: a full dataset run (3+ minutes of audio) and a limited dataset run (30 seconds of audio). For the data-deficient model, approximately the same length of validation data was used (~30 seconds) to provide a legitimate loss comparison to the full dataset model. Validation was performed every 2 epochs and validation losses were plotted using Matplotlib.
The distortion pedals chosen were the Ibanez TS9 Tubescreamer pedal and the Boss MT-2 Distortion pedal. The TS9 was used as the starting model, and the MT-2 was used as the transfer learning model.

The amplifiers chosen were the Fender Blues Jr and the Blackstar HT40. The Blues Jr. was used as the starting model, and the HT40 was used as the transfer learning model.

Note: The starting models were both trained on the full 3–4 minute dataset (TS9 and Blues Jr).
The training code used is the Automated-GuitarAmpModelling project on Github, specifically the Colab script contained in the GuitarML fork of the same project. Training was allowed to run to completion, and the number of epochs varies for each run based on the “validation patience” setting of 25, which means training was automatically halted after 25 epochs of no improvement. It should be noted that an adaptive learning rate is also implemented in this code.
Distortion Pedal Tests
Boss MT-2 Full Dataset
The first test conducted was the Boss MT-2 starting from the TS9 model. Even though these are similar pedals, their distortion qualities are musically different. The MT-2 drive was dialed back to more closely match the TS9’s lighter distortion, which was set at full drive. The validation loss comparison is shown below.
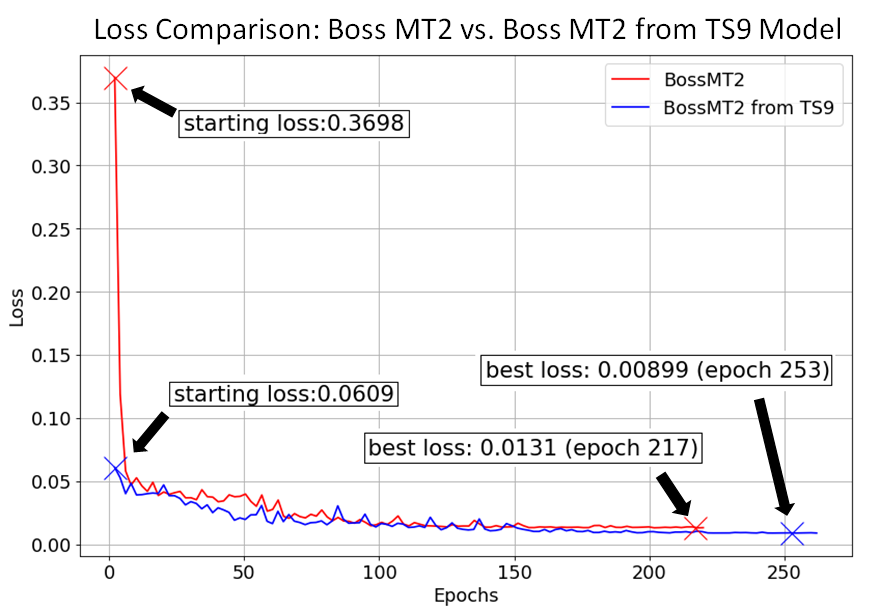
The most significant difference is the starting loss, which was measured after the first two epochs. The transfer learning model was able jump start down to 0.06 from 0.37. The overall trend shows the transfer model at a slightly lower loss continuing to the end of the run. The overall loss improvement of 0.004 is not (to my ears) audibly better. The sweet spot in this case seems to be just prior to epoch 50, where the loss difference is around .02.
Boss MT-2 Reduced Dataset
The second test was done using 30 seconds of the same MT-2 data for training, rather than the full 150 seconds. 30 seconds of audio was still used for validation, since a smaller length of validation data could result in a deceptively lower loss value.
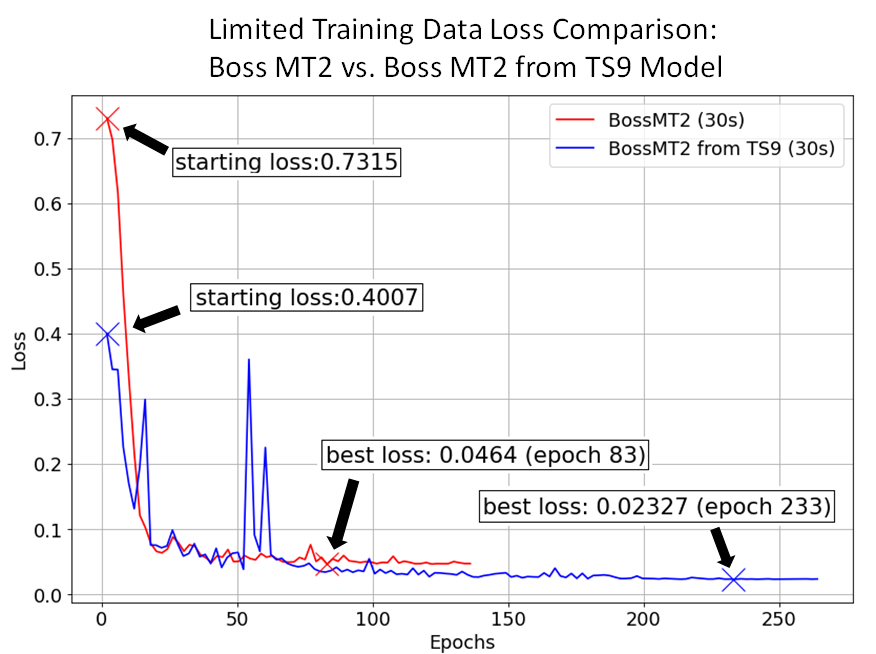
Due to the smaller training datasets, the training time was cut in half, and would be even less if a smaller validation set was used. (Again, the validation set was kept to the same length as in the full data training, about 30 seconds, for a more accurate comparison).
The starting loss was significantly lower, with a similar trend until around epoch 60 where the transfer learning model continues to improve. The transfer learning model also continued to have very small improvements for more epochs, until halting at epoch 263. Compared to the full dataset test, the loss difference between the from-scratch model and the transfer learning model is more significant starting around epoch 60. An overall loss difference of 0.023 is enough for a trained ear (and high quality speakers) to identify the more accurate model.
Amplifier Tests
The transfer learning tests for the combo amps were conducted next. The Blues Jr. drive was set to max with the “fat” boost button engaged. The drive knob for the HT40 was reduced to approximately 25% from max in order to get close to the same level of crunch. Both amps feature all-tube pre-amp and power-amp circuits, but the HT-40 also has an overdrive clipping circuit with a Tubescreamer style sound. Both samples were recorded using a SM57 dynamic microphone positioned at mid speaker cone. Generally speaking, training is more difficult from a mic’d amp than an amp with direct out capability. The speaker and microphone add dynamics to the signal that are musically pleasing to the ear, but more complex for training.
HT40 Full Dataset (with sound samples)
The first amp test used the full set of data, this time with 4 minutes of audio (3' 20" for training and 40 seconds for validation).
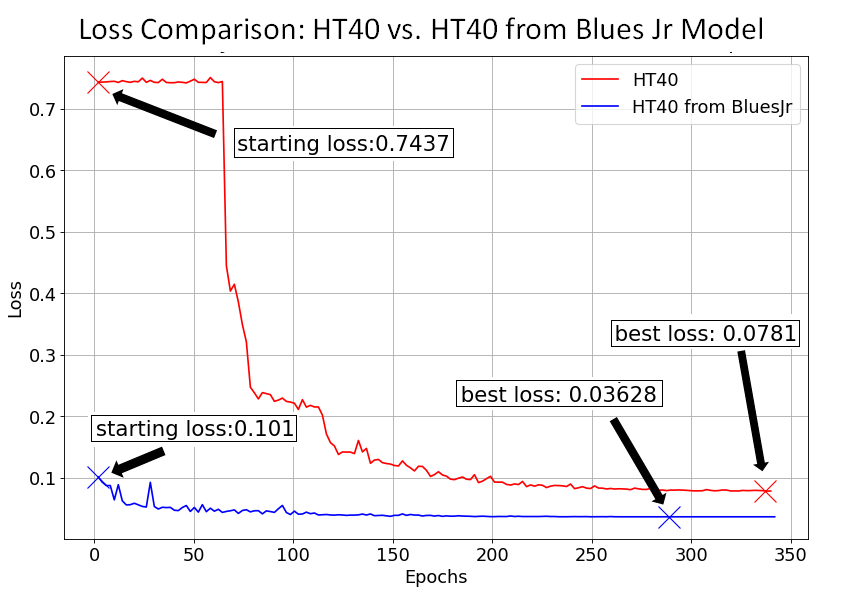
The loss difference throughout training for the HT40 amp is more extreme than the MT-2 distortion pedal. The HT40 from scratch required around 60 epochs before the loss began to decrease. The transfer learning enhanced model however, started much lower and continued to make small improvements throughout the run.
Note: The HT40 from-scratch training was interrupted near epoch 340, but seemed to be close to finishing on it’s own.
The sound samples for the full dataset HT40 amplifier test are shared here for comparison. The goal is to sound the closest to the target audio as possible. This is the target audio, which is the HT40 amp at 25% gain (overdrive channel) recorded from an SM57 microphone:
This is the model trained from scratch (no transfer learning, loss value of 0.078):
And this is the model using the Blues Jr. amp as a starting point (transfer learning enhanced, loss value of 0.036):
Even without studio monitors or expensive headphones, the transfer learning model is noticeably closer to the target. The loss improvement by using transfer learning was approximately 0.04.
HT40 Reduced Dataset
Next, the limited dataset was used; 40 seconds for training and 40 seconds for validation.
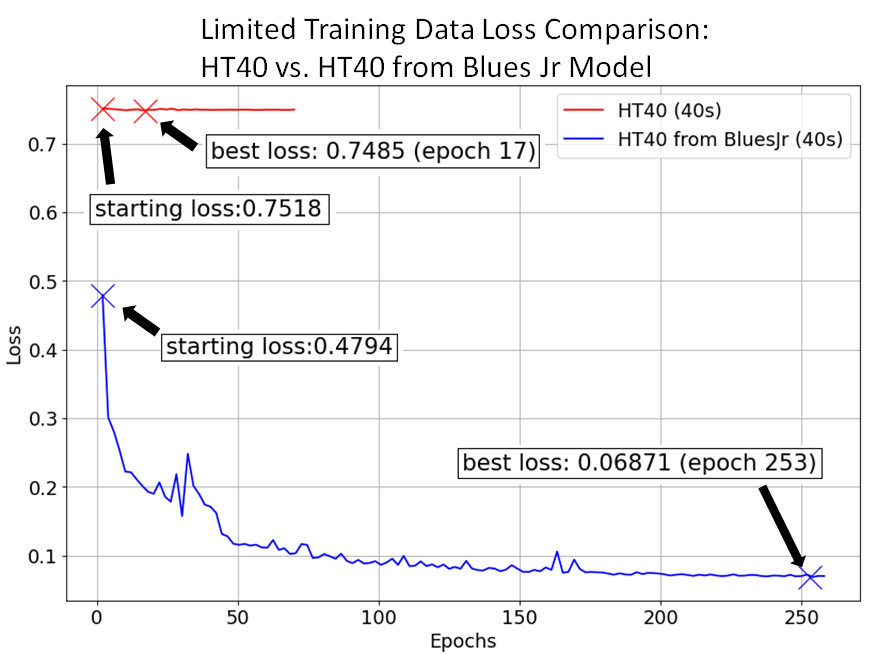
This test showed the most dramatic benefit from using transfer learning. The limited dataset training the HT-40 from scratch did not converge, and validation loss did not go below 0.74. The run lasted for 68 epochs before the patience limit was reached and training automatically halted. When starting from the Blues Jr. model however, the loss immediately started decreasing and continued improving throughout the run.
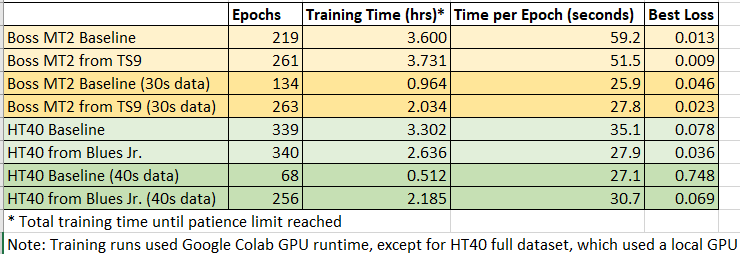
The losses and training times for all tests are compared in Table 1 below. The time-per-epoch for the reduced training sets was cut in approximately half when training on Colab. The HT40 full dataset had to be trained on a local GPU due to hitting Colab limits, so the training times for the HT40 should not be compared with the reduced dataset. The final loss values of the transfer learning models were smaller, and the difference was more noticeable in the case of the amplifier test vs. the distortion pedal. In the case of the HT-40 amplifier reduced dataset, using transfer learning was required for the model to train at all. With the exception of the HT40 reduced dataset, the best loss for the transfer models was approximately cut in half.
Conclusions and Future Work
These initial tests showed that using transfer learning can reduce training time due to requiring less training data to reach an acceptable accuracy. It is also beneficial when training a difficult signal such as a mic’d amp in overdrive. With limited data, transfer learning may be required for the model converge at all, as with the HT40 limited dataset. Using transfer learning to train an “easy” signal such as a direct-out mild distortion pedal seemed to have the smallest impact on the final model. More testing is needed to determine if these conclusions hold true for other effects and amplifiers.
In the above tests, the determination of what constitutes a similar sounding device was based on simply listening to it, which is subjective. It may be possible to use A.I. (or other DSP techniques) to first analyze the audio from a target device, and then determine which is the closest from a library of pre-trained models to get the best results.
All tests were conducted on “snapshots” of each device at particular settings (gain level, EQ, volume). It is possible to condition the models for a given parameter or set of parameters using training data for each setting. For example, you could train a single model of the full range of a gain or drive knob. However, using model conditioning increases the amount of data and training time required. Transfer learning may be a good solution to reduce the training time and amount of data needed for conditioned model training.
I hope you enjoyed reading this article! For questions and feedback you can email me at smartguitarml@gmail.com.
Transfer Learning for Guitar Effects was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3AZIT6Q
via RiYo Analytics







ليست هناك تعليقات