https://ift.tt/3b5D8Kx MLOps without too much Ops — Episode 2 With Andrea Polonioli and Jacopo Tagliabue Photo by Stephanie LeBlanc vi...
MLOps without too much Ops — Episode 2
With Andrea Polonioli and Jacopo Tagliabue

While the number of Machine Learning (ML) applications used in production is growing, not a day goes by when we don’t read something about how most enterprises still struggle to see positive ROI (see here and here).
One thing you might notice: nobody ever talks about how Big Tech is struggling to reap the benefits of ML in production. That’s because they are not. Google, Facebook, Netflix and the other top players are pretty good at operationalizing ML and the last thing they are worried about is bad ROI.
The bar is always claimed to be too high for companies that have to deal with constraints that Big Tech does not have. The interesting thing is that the vast majority of companies are like that. Most companies are not like Google: they can’t hire all the talent they dream of, they don’t have billions of data points per day and they cannot count on virtually infinite computing power.
Of all the endless forms most beautiful that companies outside of Big Tech can take, we are particularly interested in a growing — and, we believe, underserved — segment that is especially relevant for ML systems.
We refer to this segment as ‘Reasonable Scale companies’ (as opposed to the unreasonable colossal scale of FAANG companies).
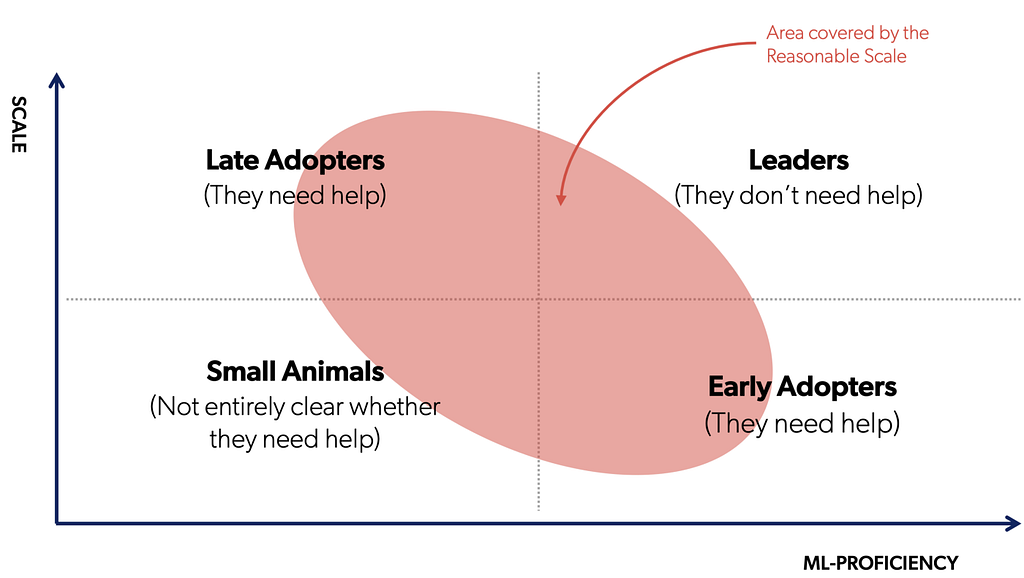
In this post, we will try to flesh out what we mean by Reasonable Scale companies. Most importantly, we want to look into the constraints that such organizations have to deal with on a daily basis. If some (or all) of these constraints resonate to you, congratulations: you are probably doing ML in a Reasonable Scale company.
The good news is that this is actually a great time for ML at a Reasonable Scale. For the first time in history, the DataOps and the MLOps toolkit has become rich, composable and flexible enough to build end-to-end pipelines that are reliable, reproducible and scalable: have no fear, as the upcoming posts of this series will show you exactly how.
Before turning to the “blooming buzzing confusion” of the current MLOps landscape, it is important to expound the hard constraints that define our problem space and to lay down some design principles.
The Reasonable Scale
The definition of Reasonable Scale (RS) is multi-faceted. It is meant to be flexible enough to include many use cases in different industries. In the spectrum, we can find digital native startups skyrocketing towards hyper growth, as well as big traditional enterprises spinning up ML applications in production for limited use cases. At the same time, the definition is meant to capture a certain adoption target for a good deal of open source tools and MLOps products out there right now.
The dimensions we use to define RS companies are the following:¹
1. Monetary impact: ML models at a RS create monetary gains for hundreds of thousands to tens of millions of USD per year (rather than hundreds of millions or billions).
Intuitively, what we want to say is that successful models at RS seldom have the kind of impact of applying BERT models to Google search or improving Amazon’s recommendations. ML in RS companies can have considerable impact, but the absolute scale of such impact rarely reaches the scale of big-data companies.
Another way of thinking of this a bit more formally is to look at the Net Present Value (NPV)² state of investing in ML in RS companies. As mentioned, RS companies come in different sizes and differ along many dimensions, from business maturity to operational efficiency, from financial leverage to liquidity. They can be booming companies, growing fast in revenues but not necessarily profitable, such as direct-to-consumer brands like Warby Parker and Casper or digital native players like Tubi or Lyst; or they can be more established players that already hit profitability, like retailers Kingfisher and Marks and Spencer.
The key point is that all these organizations should follow a key tenet of capital budgeting, namely they are expected to undertake those projects that will increase their profitability.
A positive NPV normally indicates that the investment should be made, unless other projects have higher NPVs. Investments in ML are no exception and the NPV correlates with the impact that ML application can have in a company and with the size of the company. When companies are too small, the NPV of ML investments can be negative or modest, meaning that the project shouldn’t be pursued at all or is actually unlikely to get prioritized over competing initiatives with comparable NPV (for example because the latter may have shorter payback periods or be generally perceived as less risky).
The notion of RS is meant to describe a range of companies that, despite their differences, face similar problems and would all benefit from adopting similar principles. If you are somewhere in this spectrum, it’s likely that the projected NPV for your ML investments has an upper bound of 100,000,000 USD. ³
2. Team size: RS companies have dozens of engineers (rather than hundreds or thousands).
FAANG companies have no real troubles securing and retaining talent (e.g. Netflix receives somewhere in the ballpark of 350,000 job applications each year). RS companies cannot count on such flow. Their ML teams are made by dozens of data scientists and ML engineers and RS companies need to organize those teams in a way that ensures productivity and maximizes their output. This is not exactly easy. ML people in these companies face many challenges, as their employers are often later adopters of ML tools and tend to be less mature across the entire stack.
To optimize for smaller teams, RS companies are often striving to minimize operational friction, that is, to find ways for ML developers and data scientists to rely as little as possible on other teams to get data, provision GPUs, serve models, etc.
That makes a whole lot of sense, since much of ML systems’ development depends on the type of problem solved, so data scientists need to be able to make choices about tooling, architecture and modeling depending on datasets, data types, algorithms and security constraints. In addition, ML systems are not deployed against static environments, so data scientists need to be aware of changes in the data, changes in the model, adversarial attacks, and so on.
At the same time, it is important not to have data scientists involved in too many ancillary tasks, as it would require them to develop too many complementary skills: if it is now their job to provision GPUs, we simply shifted the burden, rather than increasing velocity. Striking the right balance is no mean feat.
3. Data volume: RS companies deal with terabytes (rather than petabytes or exabytes).
FAANG companies have data from billions of users to continuously train their models. For example, WhatsApp users exchange up to 100 billion messages daily and Amazon has 153 million members in its Prime membership program only in the US. Google has 8 (!) products with more than 1BN users each.
For RS companies, instead, collecting massive training sets is typically not feasible due to issues such as data scarcity, privacy protection, and regulatory compliance or simply mere scale.⁴
Consider a pretty data-intensive space such as e-commerce. From our own data, we know that multi-billion dollar retailers with websites, ranked between 25k and 4k by the Alexa Ranking generate in between 1.5M and 10M of unique visitors per month. That’s quite impressive: 10M people is the population of Mexico City. But…if we take Amazon, the unique visitors per month are in the order of magnitude of 200 millions. That’s approximately six times the population of Canada. So much for the megacity scale!

Add to this also that 96 % of enterprises encounter data quality and labeling challenges in ML projects and that for some use cases data volume challenges have only become more serious due to disruptions such as the COVID-19 pandemic.⁵
The fact that there is a limited amount of data available at RS has consequences for what it should be considered optimal. Perhaps, excessive focus on top-notch modeling is less than strategically wise. For instance, best in class models might not be optimal in terms of cost/gain ratio or in many cases might not even be a viable option if they are too data hungry.
There is much more marginal gain for RS companies from focusing on clean, standardized and accessible data, as suggested by the original proponents of Data-Centric AI.
4. Computing resources: RS companies have a finite amount of computing budget.
The complexity of ML models has been growing steadily, with DL being especially demanding in terms of compute infrastructure. Spending on computing is generally rising and so do costs.
Now, even if the demand for computing in Big Tech companies is escalating (just an example), these companies have pretty much infinite computing resources. Let’s be real: Amazon and Google literally own their cloud provider.
For everybody else, the costs for performance gains can be prohibitive. For example, Strubell et al. recently benchmarked model training and development costs in terms of dollars and for the task of machine translation they estimated that an increase in 0.1 BLEU score using neural architecture search for English to German translation resulted in an increase of 150,000 USD compute cost.
One of the factors that impacts computational efficiency the most in RS companies is the inefficient design of ML systems from an end-to-end perspective (including the data stack). At RS the focus needs to be equally split between keeping the bill as low as possible and making scaling as efficient as possible.
The paradox is that it is easier for Google to go from 1 GPU to 1000 GPUs than it is to go from 1 GPU to 3 GPU for most RS companies. For instance, plenty of RS companies use distributed computing systems, like Spark, that are unlikely to be required. Much can be achieved with an efficient vertical design that encompasses ways to scale computational resources with minimal effort and only when needed.
Shameless cliffhanger for the next post
These four dimensions define what we call RS companies. You don’t necessarily have to find severe constraints with respect to all of them at the same time, nor should they describe exactly the situation in your company. However, if you found yourself wondering often how to estimate the ROI from a monetary perspective or how to model computational efficiency given your budget constraints or how to choose the right strategy to stop making your data scientist spend most of their time on data quality, well…you probably are in RS company.
In the next post, we will go into the details of what you can do about it and discuss four simple pillars that constitute our own spiritual and practical guide as ML practitioners at RS:

● Data > Modeling
● ELT > ETL
● PaaS/FaaS > IaaS
● Vertical > Distributed
Don’t worry there will take the time to walk through this framework thoroughly and there will be stuff you can actually use, like plenty of opensource code and documentation.
Notes
¹ Note that the dimensions we are going to introduce are strongly correlated, but there are some exceptions: for instance, in Adtech you get enormous amounts of data and need plenty of computing resources but perhaps not too many engineers.
² Namely the current value of (discounted) future net cash flows (difference between benefits and costs) given an interest rate (the discount rate).
³ An important corollary to this point is that at the beginning of the ML adoption cycle, organizations should always start at RS, irrespective of their global size, because it’s awfully hard to estimate ROI without at least one practical example. The tech stack and the practices we describe in this series are well-suited also for big enterprises that are starting out.
⁴ Note on B2B: some RS may be quite large in terms of data processed if considered as a whole, but in practice data are siloed by customer. Coveo is one of them, for instance, and we have to address this point specifically when we do product development.
⁵ There are options available to mitigate data scarcity challenges. For example, data enrichment allows RS companies to add third-party data to make models more accurate. Synthetic data is another option (i.e. data not obtained from direct measurements) using methods such as statistically rigorous sampling from real data, generative adversarial networks, or by creating simulation scenarios. Innovation in this area is mostly spearheaded by early-stage startups such as MostlyAI or Rendered.AI and it is worth keeping an eye on.
Acknowledgment
This series wouldn’t be possible without the commitment of our open source contributors:
- Patrick John Chia: local flow and baseline model;
- Luca Bigon: general engineering and infra optimization;
- Andrew Sutcliffe: remote flow;
- Leopoldo Garcia Vargas: QA and tests.
ML and MLOps at a Reasonable Scale was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/2ZcdYY3
via RiYo Analytics








No comments