https://ift.tt/3ptbRdf This is a collaborative post from Bread Finance and Databricks. We thank co-author Christina Taylor , Senior Data En...
This is a collaborative post from Bread Finance and Databricks. We thank co-author Christina Taylor, Senior Data Engineer–Bread Finance, for her contribution.
Bread, a division of Alliance Data Systems, is a technology-driven payments company that integrates with merchants and partners to personalize payment options for their customers. The Bread platform allows merchants to offer more ways to pay over time, serving up the right options at the right time, empowering merchants to improve conversion rates and lift average-order-value. Bread currently services over 400 merchants — notably GameStop (Canada), SoulCycle, and Equinox (US) — and continues to grow. The platform is driven by big data use cases such as financial reporting, fraud detection, credit risk, loss estimation and a full-funnel recommendation engine.
The Bread platform, running on Amazon Web Services (AWS) Cloud, consists of several dozen microservices. Each microservice represents a part of a user or merchant’s journey, for example: A customer selects a payment option or applies for a loan; a merchant manages the transaction lifecycle or tracks settlement details. Every microservice writes to its own Postgres database, and the databases are isolated from each other by design. For internal business analysis and external partnership reporting, we need a centralized repository where all data from different services come together for the first time.
Existing implementation
Our first iteration of ingestion was a data sync Python module that dumped all databases and tables nightly as CSV files, copied the files into Snowflake warehouse’s raw schema, and overwrote existing tables every night. We then used dbt (Data Build Tool) and a custom decryption module — also run as python containers — to transform the data and make them reporting ready. See the diagram below.
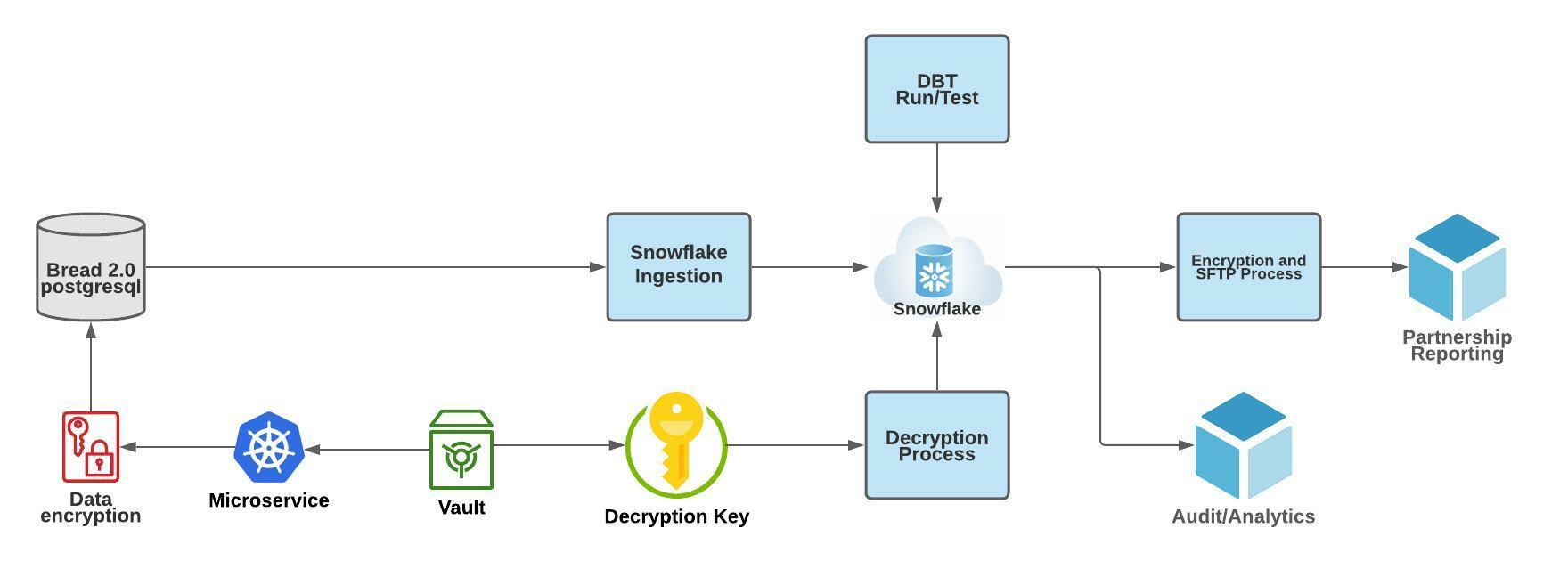
Challenges
While the above ingestion workflow successfully enabled reporting, there were a few significant challenges. The most pressing one was scalability. Our Python module was run by a KubernetesPodOperator on an Airflow cluster in our AWS Cloud. It was subjected to the compute resources (~1GB CPU, ~500 MB memory; 3 times the default) allocated to the pod, and overall extra capacity provisioned by the Airflow cluster. As total data volume grew from Gigabytes to Terabytes, the time it took to run the data sync job in one deployment had also grown from minutes to hours, straining pod resources and creating latency for downstream data transformation. We needed a better solution that could scale with our business as the number of transactions and partners increases.
The second challenge was schema evolution. Microservices continue to evolve and schema changes can occur every week. While we could “automatically” respond by dropping and recreating the tables in Snowflake, we had neither knowledge of the change nor time to update the downstream data models. As a result, the transformation jobs often error on schema change. We needed a solution that could warn us of schema changes and was more fault-tolerant.
The last challenge was velocity. As our team and usage both grew, there was an increasing need for timely ingestion. While Day -1 updates may be sufficient for reporting, internal BI functionalities — especially risk and fraud analytics — required fresh data from our applications. We needed a solution that provides near real-time data.
Proposal
To summarize, we needed a platform to provide:
- Scalable computing independent of memory restrictions of kubernetes pods
- Storage option which offered simple but safe schema evolution
- Ability to transition from batch to streaming with one-line code changes
Fortunately, Delta Lake running on Databricks provided the solution to all of the above. We set out to build 1) A formal change data capture process instead of naive data dump, 2) Apache SparkTM instead of Python modules for ingestion, and 3) Databricks instead of Snowflake for computing. We also wanted to continue supporting data models and users on Snowflake, until we could fully migrate to Databricks.
Lakehouse for a transaction enrichment pipeline
The vision of a lakehouse is to deliver on the business use cases described in the first paragraph in this article. The key is to set a foundation in Delta Lake, empowering data science and analytics engineering to run jobs and analyze data where it exists without incurring costs on egress/ingress. Additionally, since Bread is always looking to optimize for data freshness, the core capabilities had to involve a robust engine for reliable and speedy ingestion.
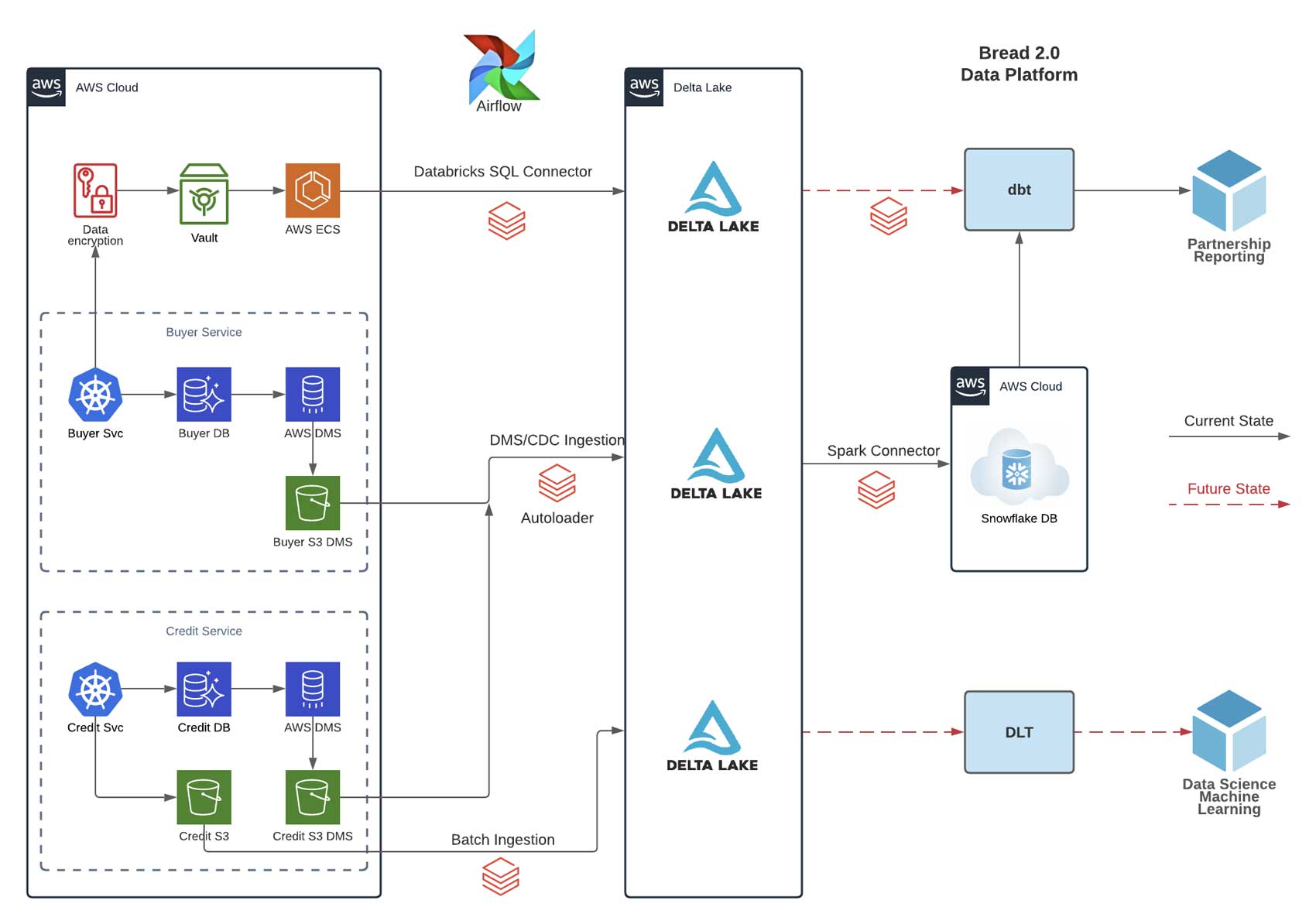
DMS & Auto Loader for change data ingestion
Inspired by this blog, we chose AWS DMS (Database Migration Services) for database snapshotting and change data capture. The source was our microservices which are backed by Postgres databases (RDS); the target was a collection of Amazon S3 buckets. We then ingested the DMS data with Auto Loader and continuously upserted change sets into Delta Lake. We also refactored external jobs using the newly available Databricks SQL Connector. The following sections explain our rationale and implementation in greater technical detail.
DMS configuration
In our setup, for each microservice, there is a corresponding DMS task and S3 bucket. The migration consists of 3 major phases:
- The snapshot of existing data (full load)
- The application of cached changes
- Ongoing replication (CDC)
We configured the extra connection attributes as such
cdcInsertsOnly=false;compressionType=GZIP;dataFormat=parquet;datePartitionEnabled=true;DatePartitionSequence=YYYYMMDD;includeOpForFullLoad=true;parquetTimestampInMillisecond=true;timestampColumnName=timestamp;DatePartitionDelimiter=NONE;
Given the above configuration, full load files are written to <microservice_bucket>/<schema_name>/<table_name>/LOAD*.parquet
CDC files are written to <microservice_bucket>/<schema_name>/<table_name>/yymmdd/*.parquet
The extra connection attributes partition the change data by date and add an “Op” column with “I”, “U”, or “D” possible values, indicating if the change is an insert, update, or delete operation.
An important customization for us involves limitations using S3 as a DMS target. Some of our source table columns store large binary objects (LoB). When using S3 as a target, full LoB mode is not supported. We must specify a Lob MaxSize in the DMS task setting; DMS LoB columns will appear as Spark StringType. The MaxLobSize parameter is 32 (kb) by default. Based on our calculation, we need to increase the value to prevent string truncation.
SELECT max(pg_column_size(col_name)) from source_table; ------- 17268
DMS Replication handles each character as a double-byte character. Therefore, find the length of the longest character text in the column (max_num_chars_text) and multiply by 2 to specify the value for Limit LOB size to. In this case, Limit LOB size is equal to max_num_chars_text multiplied by 2. Since our data includes 4-byte characters, multiply by 2 again: 17268 * 4 ~ 70 kb
Spark jobs
For each microservice, there is a Snapshot Spark job that traverses the S3 DMS directory, finds all tables, loads the data into Databricks Delta Lake and creates initial tables. This is followed by CDC ingestion spark jobs that locate all tables, find the latest state of each record, and merge the changed data into the corresponding Delta tables. Each time we run CDC ingestion, we also keep track of the schema and store the current version on S3.
When ingesting DMS change data, it is critical to identify the primary key of source tables. For most of our microservices, the primary key is “ID”. Some tables do not observe this naming convention, and others use composite primary keys. Therefore, the key columns to merge into must be declared explicitly or created. We concatenate composite primary key columns.
// Snapshot data ingestion
snapshotData
.withColumn("latest", to_timestamp(col("timestamp")))
.drop("timestamp")
.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
.option("path",deltaTablePath)
.saveAsTable(deltaTableName)
// Change data ingestion
changeData.writeStream
.format("delta")
.foreachBatch(
Platform.cdcMerge(
tableName = deltaTableName,
pkColName = pkColName,
timestampColName = "timestamp"
) _
)
.outputMode("update")
.option("checkpointLocation", checkpointPath)
.option("mergeSchema", "true")
.trigger(Trigger.Once())
.start()
// Merge function
def cdcMerge(tableName: String, pkColName: String, timestampColName: String)(
microBatchChangeData: DataFrame,
batchId: Long
): Unit = {
DeltaTable
.forName(tableName)
.as("t")
.merge(
microBatchChangeData
.transform(
findLatestChangeByKey(
windowColName = pkColName,
strTimeColName = strTimeColName
)
)
.as("c"),
s"c.${pkColName} = t.${pkColName}"
)
.whenMatched("c.Op == 'D'")
.delete()
.whenMatched()
.updateAll()
.whenNotMatched("c.Op != 'D'")
.insertAll
.execute()
}
Note: Depending on how microservices perform updates — for instance, when records are replaced in place — there can be concurrent inserts and updates. In this case, finding the latest change by key may require custom ordering. Additionally, change data can arrive out of order. We may receive a DMS file containing the eventual delete operation before the file with insert or update. Special handling such as CDC timestamp marking and using a “premature delete flag” may be needed to prevent insertion of actually deleted data.
Why use Auto Loader?
Databricks Auto Loader can automatically ingest files on cloud storage into Delta Lake. It allows us to take advantage of the bookkeeping and fault-tolerant behavior built-in Structured Streaming, while keeping the cost down close to batching.
Cost savings
Why not a traditional structured streaming job? Streaming job clusters are on 24/7. The cluster can scale up, but not down. During testing, we called the cluster API and forced the cluster to scale down every 2 hours. In comparison, when we use the run once trigger to process files at desired intervals (every 2 hours), our compute cost decreased by more than 90%, even with our naive scaler in place.
Streaming vs batch
How is using Auto Loader different from simply running a batch job? We do have batch jobs that load daily partitioned files from S3. In the batch processing scenario, we set up an S3 sensor and a replace where logic to reprocess when necessary. Structured Streaming, on the other hand, commits all files created by the job to a log after each successful trigger. In the event of failure, we can simply pick up where we left off without having separate processes to remove incorrect or duplicated data.
Notification vs directory listing mode
We have seen DMS output many small files in the change data partition — typically several hundred in each day’s partition. Auto Loader’s notification mode can reduce the amount of time taken by each Spark job listing file prior to ingestion. However, due to AWS limitations, file notification does not have a definite SLA. We have observed that some files landed on S3 did not get discovered until the next day. As each business day’s transaction must be reported to our partners before a cutoff time, notification mode is not a reliable option for us.
Fortunately, in Databricks 9.0 and above, file listing has been greatly optimized. More details on this improvement can be found here. In our scenario, each job run only takes ⅔ of the time in contrast to running with DBR 8.4. The difference compared to using notification mode in 8.4 is also negligible. We no longer need to sacrifice performance to guarantee data freshness.
Use Databricks SQL connector to decrypt PII for data scientists
To fully migrate to a Lakehouse, we need to refactor several jobs running on external systems connected to Snowflake, notably PII decryption on Amazon ECS. A subset of transformation relies on decrypted data and is critical to BI work. We must minimize migration risks and prevent disruption to business functions.
The ECS cluster is configured with access to private keys for decryption. The keys are shared with microservices and stored in Vault. The job writes pandas dataframes to Snowflake and replaces existing data each night. Still, we need to solve the following challenges:
- How do we keep the existing ECS setup and secrets management strategy?
- Is it possible to write to Delta Lake without installing Apache Spark as a dependency?
Thanks to Databricks SQL connector, we are able to add the databricks-sql-connector Python library to ECS, thereby using a pyodbc connection under the hood to enable a simple data flow writing pandas dataframe to delta lake. More details on this connector can be found here.
from databricks import sql
for s in range(0, conn_timeout):
while True:
try:
connection = sql.connect(
server_hostname=getenv("DATABRICKS_HOST"),
http_path=getenv("SQL_CONN"),
access_token=getenv("DATABRICKS_TOKEN"),
)
except Exception as err:
logger.warning(err)
logger.info("retrying in 30s")
sleep(30)
continue
break
Databricks SQL Connector is newly released and a good fit for remote connection to Databricks SQL or Clusters
The connector provided enough flexibility so we are able to decrypt in chunks and upsert the data into Delta Lake, leading to a performance improvement over decrypting all records and replacing the entire table in Snowflake.
num_records = df.shape[0]
batch_num = math.floor(num_records / batch_size)
cursor = connection.cursor()
for i in range(batch_num + 1):
pdf = df.iloc[i * batch_size : (i + 1) * batch_size]
insert_values = pdf.to_records(index=False, index_dtypes=None, column_dtypes=None).tolist()
query = f"""MERGE INTO {database_name}.{delta_table_name} as Target
USING (SELECT * FROM (VALUES {",".join([str(i) for i in insert_values])}) AS s ({key_col}, {",".join(val_cols)})) AS Source
ON Target.id=Source.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *"""
cursor.execute(query)
Spark connector vs external tables
To support Snowflake reporting work and user queries during migration, we tested using Delta Lake Integration with Snowflake external tables. Eventually, we opted for using the Spark connector to copy Delta tables into Snowflake prior to high profile, time-sensitive reporting tasks. Here are our main reasons for moving off external tables:
- Frequent schema changes: Although we configured auto refresh using S3 notifications and queue system, Snowflake cannot support automatic schema merge or update as Delta Lake does. CREATE OR REPLACE and external table auto refresh became incompatible.
- Performance concerns: External tables have proven to be roughly 20% slower compared to copying the data over with Spark Connector.
- Inconsistent views of partitioned, vacuumed, and optimized tables: Maintaining external tables became blockers for Delta Lake optimization.
- Lack of documentation and references: External tables configuration can be complex and experimental in nature; comprehensive and accurate documentation proved challenging to find.
- Loss of functionalities within Snowflake: Very limited ability to audit and debug external table freshness and validity issues.
Future data science directions
As we productionize DMS/CDC ingestion and Databricks SQL connector, we centralize all our raw data in Delta Lake forming a single source of company facts. We are now ready to build out the Lakehouse vision, moving computation and query to Databricks SQL, and paving the way for near eal-time data science and analytics work. Below is the illustration of our platform pipeline (solid line for current state; dotted line for future state):
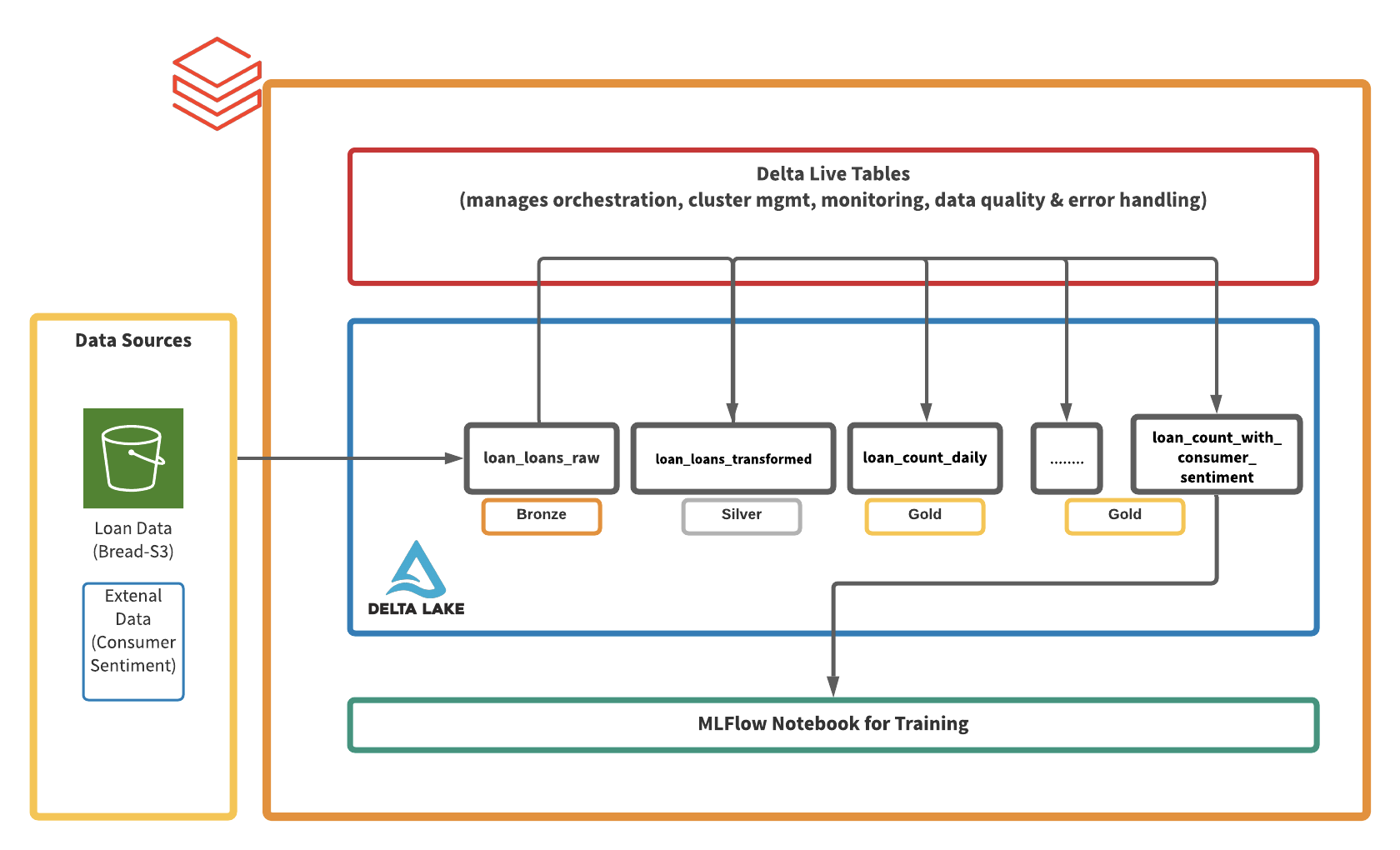
Delta Live Tables + expectations for rapid prototyping
Our current BI analysis flow requires Data Engineers to write spark jobs and deploy dbt models. To accelerate ML development, we explored Delta Live Tables running on Photon, the next-generation query engine. Data Engineers and Analysts collaborated closely and effectively combining Python and SQL. We were particularly excited by how quickly we were able to ingest raw loan data stored on S3, join external data sets (e.g. consumer sentiment), validate data quality, experiment with ML models in a notebook environment, and visualize the results in our BI tools.
Below is an illustration of our Pipeline, from S3 files to Looker Dashboards delivered by Slackbot. Following are the main reasons we want to use DLT for future Data Science work:
Speed
In just a matter of hours, we can move from raw data to actionable insights and predictions. We can even continuously stream data from S3, and build in expectations for validation.
Democratization
Analysts and data scientists can work directly on an end-to-end pipeline without extensive support from engineering. We can also collaborate and mix languages in one pipeline.
Unification
All stages of the deployment exist in one place, from data load, orchestration to machine learning. The pipeline lives with its execution engine.
Conclusion
In this blog, we demonstrated how Bread is building a resilient, scalable data platform with Databricks Delta Lake: We use AWS DMS and Databricks Auto Loader jobs to incrementally capture changes from RDS data sources and continuously merge CDC data into Delta Lake. We also showcased how to migrate jobs external to Databricks using the native Databricks SQL connector. Once we complete building the centralized data lake, our next steps will be taking advantage of Photon SQL Analytics endpoints and DLT pipelines to enable near real-time BI and ML work with much simpler configurations and less engineering dependency.
--
Try Databricks for free. Get started today.
The post How Bread Standardized on the Lakehouse With Databricks & Delta Lake appeared first on Databricks.
from Databricks https://ift.tt/3b1ZhJD
via RiYo Analytics








No comments