https://ift.tt/3jOl5NA Distributed Kafka Consumers Using Ray — Python How to write a distributed Kafka Consumer in Python using Ray Phot...
Distributed Kafka Consumers Using Ray — Python
How to write a distributed Kafka Consumer in Python using Ray

Introduction
Through this blog, I will try to give a gist of a few Ray components that we will be using and then work towards how we can use Ray to create Distributed Kafka Consumers for our Stream processing.
Why Ray for Stream Processing?
Many teams are using python on daily basis for different use cases. Today Python is one of the most used languages.
There are other distributed computing engines like Apache Spark and Apache Flink that provide the Python interface but the learning curve is very steep and you need to create specialised data sets like RDDs/DataFrames etc and the operations and concepts revolves around these constructs.
When I first used Ray it looks more pythonic way of writing distributed systems and you do not need to learn much to use Ray. You can easily convert your existing python functions and classes to run in distributed mode, without writing new or changing existing code.
A Brief Introduction of Ray
Skip to the “Creating Kafka Consumers” section if you already know Ray
Please go through the Ray documentation for more detailed information.
Ray provides simple APIs to run your functions and classes in a cluster of nodes.
Ray Terminology
- Tasks — Python Functions that run in a distributed setup
- Actors — Python classes that run in a distributed setup
- Object Ref — This is similar to Futures or Promises in Javascript. You can call get on these refs to fetch the data from the tasks executions
Running Functions in Distributed Setup
To make a function run in distributed mode, you only need to add a decorator @ray.remote()on top of your function.
In the below code we calculate factorial of numbers 10 to 16 in their own processes using ray.
In the above code:
- we start Ray using ray.init(), which starts several python processes and a bunch of other things.
- We got a factorial function that calculates the factorial of a given number. We have decorated this function with @ray.remote(), which creates a new Ray Task to run in distributed mode.
- max_retries tells ray to rerun the task 3 times, in case if the task dies before completion. The task may die when a node running the tasks is shut down or dead.
- num_cpus tells ray to run this task in 50% of 1 CPU.
- In the subsequent code, we are calling factorial of 5 to 11 and saving the futures into a list. On which we later call ray.get which allows us to wait for all factorial() the task to finish.
The output will look something like this:
This cluster consists of
1 nodes in total
8.0 CPU resources in total
(factorial pid=1155) calculating factorial of 15
(factorial pid=1155) Factorial of 15 = 1307674368000
(factorial pid=1154) calculating factorial of 16
(factorial pid=1154) Factorial of 16 = 20922789888000
(factorial pid=1148) calculating factorial of 10
(factorial pid=1148) Factorial of 10 = 3628800
(factorial pid=1149) calculating factorial of 14
(factorial pid=1149) Factorial of 14 = 87178291200
(factorial pid=1151) calculating factorial of 11
(factorial pid=1151) Factorial of 11 = 39916800
(factorial pid=1153) calculating factorial of 13
(factorial pid=1153) Factorial of 13 = 6227020800
(factorial pid=1152) calculating factorial of 12
(factorial pid=1152) Factorial of 12 = 479001600
Process finished with exit code 0
As you can see, all the factorial() tasks have started in their own processes.
The same above setup can convert to class-based setup (a.k.a Actors) by only annotating the class with @ray.remote(), this will create a new worker instance that runs on different processes and we can invoke class member functions to create remote tasks.
Creating Distributed Kafka Consumers
As you saw in the previous section we were able to run function and class member functions remotely in different processes.
We will use the same concept to run our consumers in different processes in multiple nodes.
In this section, I will cover the following feature -
- Provide configuration support to create the Kafka Consumers.
- Run Kafka Consumers In Distributed mode.
- Expose REST APIs to manage(start, stop etc) these consumers.
We are using kafka-python client to create consumers and fastapi to create REST APIs for our consumers
Making the Setup Configurable
Consumer config JSON file — This consumer config JSON file will host a list of consumer group configurations. For each config in the list, we will start a consumer group with the configured number of workers/consumers.
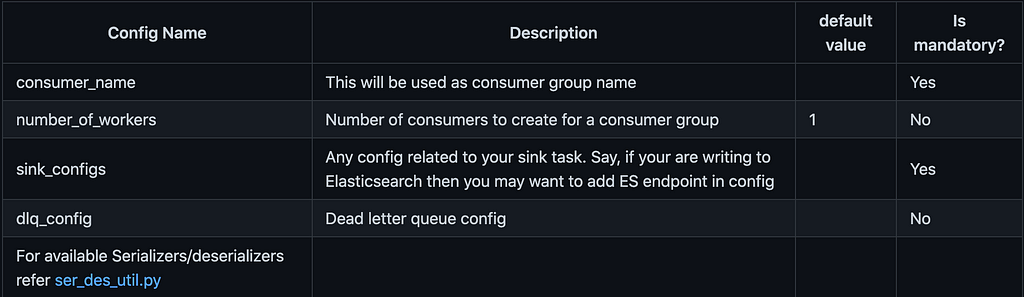
Github: https://github.com/bkatwal/distributed-kafka-consumer-python
Check ser_des_util.py for available serializers and deserializers.
Stream Transformer
Create your own Stream Transformer by extending the abstract class StreamTransformer
Below is one such transformer which converts string messages from Kafka to JSON and creates a SinkRecordDTO object.
Note that I am not performing any operation in the message here. You may want to create your own StreamTransformer that does some processing.
Finally, add your newly created stream transformer in consumer_config.json under sink_configssection.
Stream Writers
Stream writers are the group of classes that write to the target store. For instance, to write transformed events to Elasticsearch, you can create your own Stream Writer that uses ES client to update the index.
To create a stream writer, extend the class StreamWriter.
For instance, I have created one stream writer to print keys and messages in the console.
Finally, I have created a sink task class, which will act as an orchestrator and performs the below task:
- Transform the data
- Write to datastores using the provided stream writers
- Push to dead letter queue in case of failure
Running Kafka Consumers in Distributed Mode
As we saw in one of the previous sections we can run a function or a class member function remotely in different processes by decorating the class and the functions with @ray.remote()
In this section, we will work on creating remote workers and a manager that manages these consumers.
You can find the complete code here.
Remote Consumer Worker
With this setup, Ray will create a worker instance ConsumerWorker in a separate process and start tasks on them, meaning call run() function on them.
Notice that we have added a few extra parameters in the decorator:
@ray.remote(max_restarts=2, max_task_retries=2, num_cpus=WORKER_NUM_CPUS)
ray_restarts tells ray to restart the worker instance maximum of 2 times if the worker dies or is killed.
max_task_retries tells ray to restart any running task/function maximum of 2 times if the worker dies or is killed.
In the above worker, we have —
- Created a new Kafka Consumer in the constructor
- Created a run() function, that performs:
- Runs a infinite loop to poll() for consumer records/messages
- sends records for processing by calling sink_task.process()
- Commits offsets to brokers if messages are processed successfully.
- Stops the worker on demand, by breaking out of the loop - Creates a stop_worker() function that sets the flag to stop the running worker.
Consumer Worker Manager
The manager takes care of starting and stopping the consumer workers on demand.
Key things to note in the manager class
- It maintains a container of ray actors/worker instances and calls run/stop on them.
- Provides APIs to start all the consumer groups or a specific consumer group and start n workers on these consumer groups
- While creating the worker we have provided an option -max_concurrancy=2 . This will allow us to call stop() on the worker instance, even though the run() task is running.
Worker instance runs tasks sequentially in a single thread by default. - Uses ray.kill(actor/worker instance) to kill worker instance after stopping.
Rest APIs to Manage Consumer Workers
I am using Fast API to create endpoints for our consumer worker management and using basic auth to authenticate requests.
Note that on @app.on_event("startup")of service, the app creates and start all consumer groups.
You can find the complete Github code and more documentation here.
To deploy in cloud service providers read Ray Deployment Guide.
Summary
In this blog, I showcased a way to create a distributed Kafka Consumers using Ray.
As discussed this setup is highly configurable and you only need to create your own transformer and stream writer logic to make it work.
References
Distributed Kafka Consumers Using Ray — Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3vYyuHE
via RiYo Analytics








ليست هناك تعليقات